《分析》专题
-
 AQS之ReentrantReadWriteLock分析 (九)
AQS之ReentrantReadWriteLock分析 (九)主要内容:1.ReentrantReadWriteLock 介绍,2.读写锁,3.读写锁源码分析1.ReentrantReadWriteLock 介绍 ReentrantReadWriteLock即可重入读写锁,其同时应用了共享锁和排斥锁,写锁使用排斥锁,读锁使用共享锁,从而实现读读共享,读写互斥,写写互斥。 当读操作远远高于写操作时,这时候使用读写锁让读——读可以并发,提高性能。 1.1 Sync 读写锁使用的是一个Sync同步器(使用一个对象),可以分别创建。有公平锁和非公平锁两种子类进
-
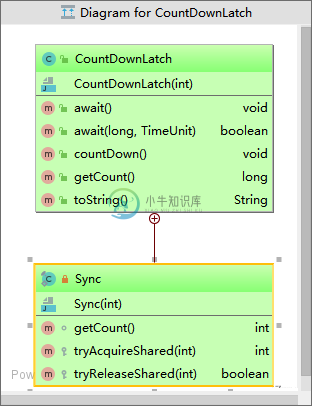 AQS之CountDownLatch分析 (八)
AQS之CountDownLatch分析 (八)主要内容:1.CountDownLatch 介绍,2.实例代码,3.源码分析1.CountDownLatch 介绍 CountDownLatch即减少计数,是AQS共享锁的另一个经典应用。其应用主要是一个(或多个)线程等待一系列线程完成某些操作后才继续向下执行的场景。 换种程序上的描述:A线程申请资源await,进行阻塞等待,一系列线程进行某些操作(共state个),每完成一个释放一次资源coutDown。所有操作完成后,A线程资源获取成功,继续向下执行。 2.实例代码
-
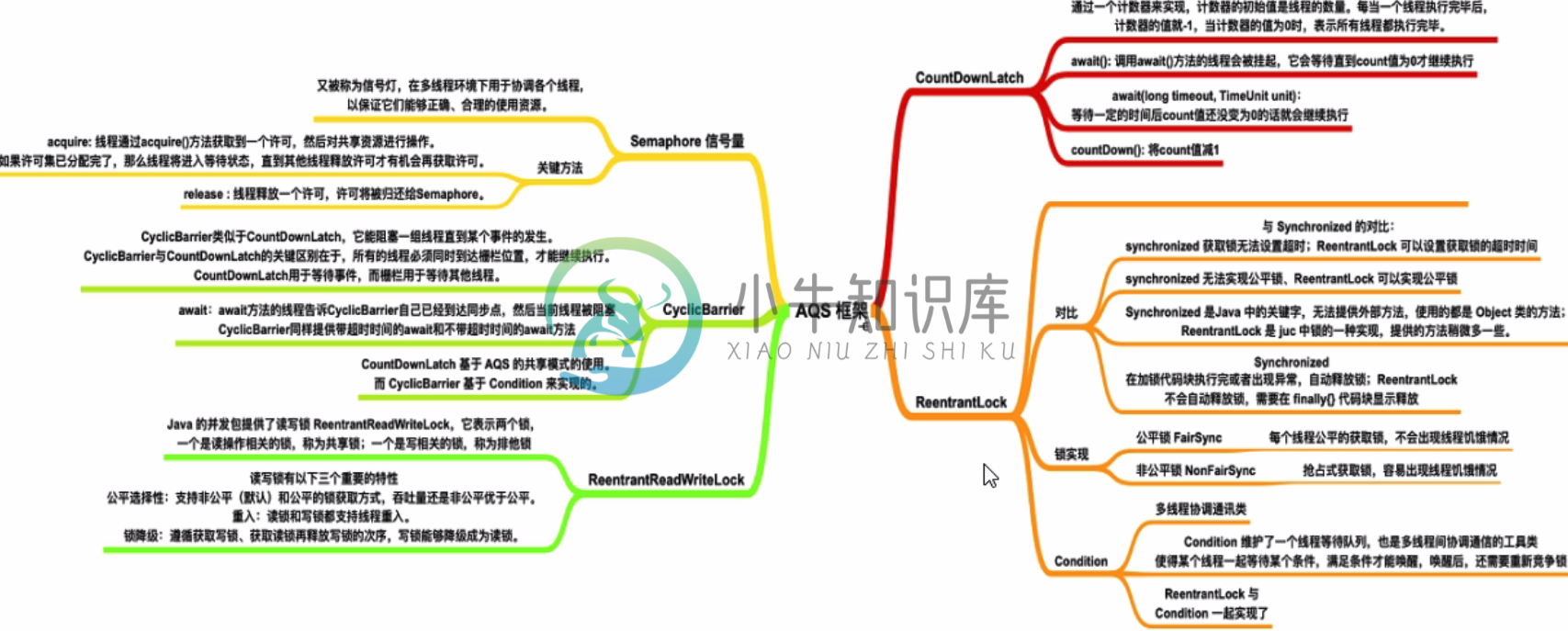 AQS之Semaphore分析 (七)
AQS之Semaphore分析 (七)主要内容:1.Semaphore 介绍,2.实例代码,3.资源获取acquire,4.释放资源1.Semaphore 介绍 Semaphore即信号量,常用于同时限制访问某些资源的线程数量。 其内部抽象类Fair继承了AQS,Semaphore正是通过Sync实现数量的控制 1.1 Sync Semaphore是基于AQS原理实现的,但并不是说Semaphore继承了AbstractQueuedSynchronizer抽象类,而是其内部类进行了AbstractQueuedSynchroni
-
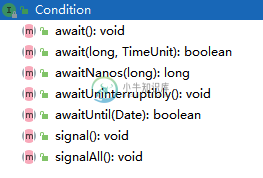 AQS之Condition分析 (六)
AQS之Condition分析 (六)主要内容:1.Condition 介绍,2.等待方法介绍,3.唤醒方法介绍,4.整体逻辑介绍1.Condition 介绍 是AQS中基于排斥锁的另一应用,其await和sign,signAll方法可以用于替代Object的wait和notify,notifyAll方法。 借助可以实现多路选择通知,通过和方法可以实现等待/通知机制(单路通知) 具体实现类是的内部类 代码中调用的实际调用的是类中的方法。 1.1 结构介绍 Condition ConditionObject 内部维护了一个基于
-
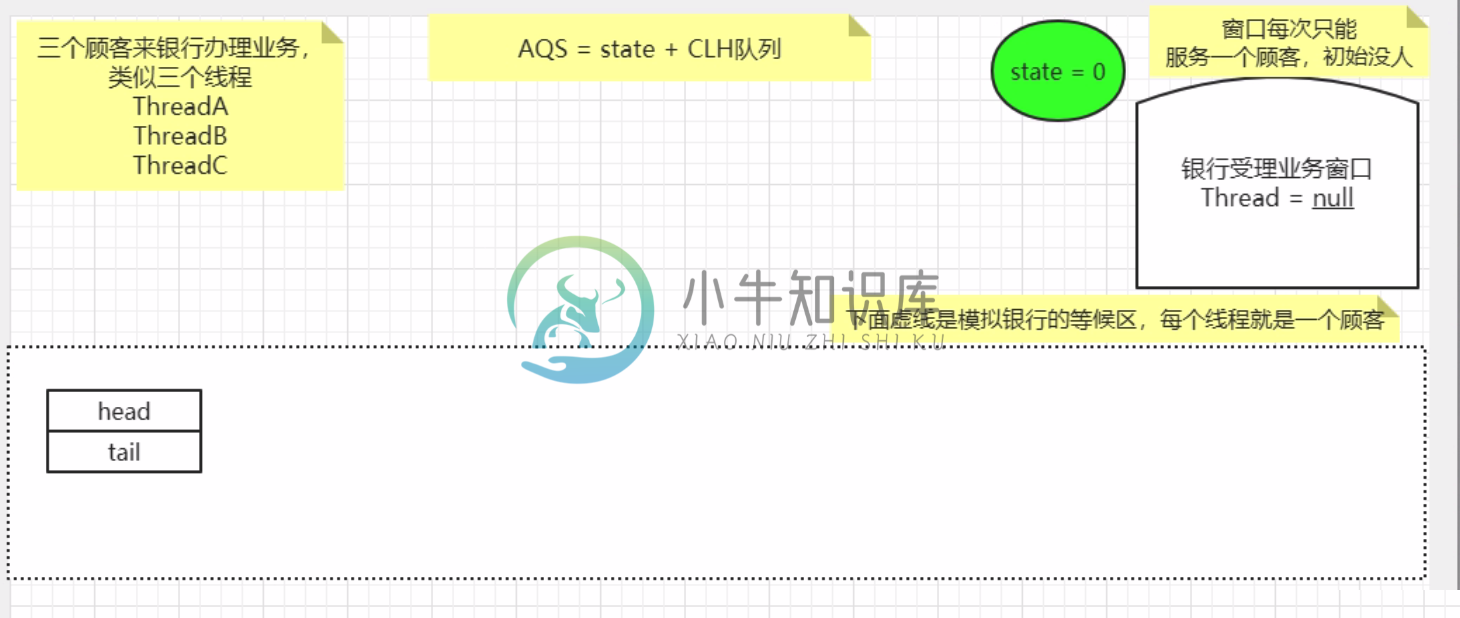 AQS之ReentrantLock分析 (五)
AQS之ReentrantLock分析 (五)主要内容:文章目录,1.案例说明,2.代码过程,3.问题解析1.案例说明 相当于3个客户访问一个线程。 2.代码过程 2.1 初始过程一 AQS 中的 state表示信号灯, 0表示没有人占用此线程 2.2 线程A的改变 通过CAS尝试将state从0变为1, 如果成功的话, 则获得资源, 失败的话, 进入到else中, 尝试获得资源。 compareAndSetState():底层调用的是unsafe的compareAndSwapInt,该方法是原子操作
-
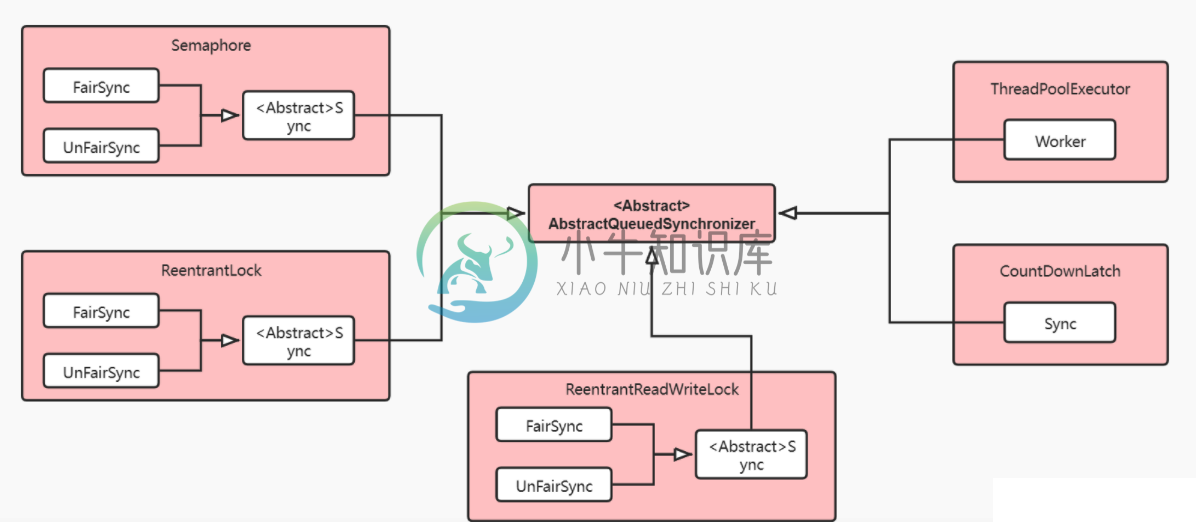 AQS之ReentrantLock分析 (四)
AQS之ReentrantLock分析 (四)主要内容:1.AQS 子类,2.ReentrantLock 简介,3.获取锁,4.释放锁1.AQS 子类 Semphore: 共享锁案例 ReentrantLock: 排他锁案例 ReentrantReadWriteLock: 共享锁和排它锁案例 ThreadPoolExecutor CountDownLatch: 共享锁案例 2.ReentrantLock 简介 ReentrantLock 为可重入锁。 2.1 Sync 和Semaphore相似,ReentrantLock也是通过
-
数据分析系统
数据概览 1.数据概览 首页>报表>数据 查看时间范围内系统的关键数据指标。包括总会话量、总消息量、平均会话时长、平均响应时长、排队放弃会话量、平均满意度以及会话量、消息量、平均会话时长之间的变化趋势条形图、柱状图和饼状图。 2.客服报表 首页>报表>客服 客服工作量分析:查看人工客服的工作数据。包括接待总数、对话总数、对话总时长、在线总时长以及在线人工利用率。 客服工作效率/质量分析:查看人工客
-
 客尼数据分析
客尼数据分析1.简历 2.标准化和归一化 3.ab test 4.如何与非技术人员进行沟通
-
 招联-数据分析
招联-数据分析1轮面试 5.13下午三点面试 1.自我介绍 2.实习项目深挖,好像也没问很多 (实习的经历和数分并不是很相关,偏算法) 3.比赛项目深挖 数据有哪些特征,用了什么模型,xgboost原理和rf的优缺点 4.反问 总得来说好像并没有问很深很难的的问题 二轮面试 一面面完五分钟内就通知过了 四点半开始(效率感人😂) 1.自我介绍 2.base,投了哪些公司,有什么offer(可能比较关注意向度)
-
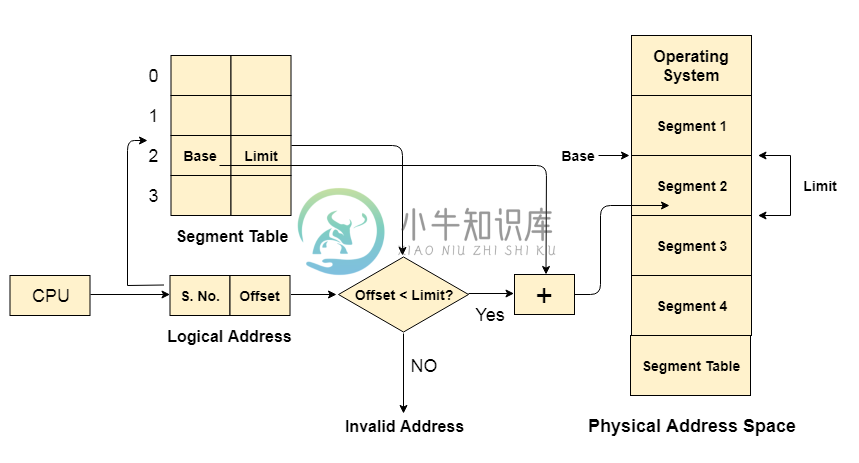 分段
分段主要内容:为什么需要分段?,逻辑地址按段表转换为物理地址在操作系统中,分段是一种内存管理技术,其中内存分为可变大小的部分。 每个部分被称为可以分配给进程的段。 有关每个段的详细信息存储在称为段表的表中。 分段表存储在一个(或多个)分段中。 分段表主要包含两个关于分段的信息: 基:它是细分分段的基地址 限制:它是分段的长度。 为什么需要分段? 到目前为止,我们使用分页作为主要内存管理技术。 分页更接近操作系统而不是用户。 它将所有进程划分为页面形式,而不
-
分页
Django提供了一些类来帮助你管理分页的数据 -- 也就是说,数据被分在不同页面中,并带有“上一页/下一页”标签。这些类位于django/core/paginator.py中。 示例 向Paginator提供对象的列表,以及你想为每一页分配的元素数量,它就会为你提供访问每一页上对象的方法: >>> from django.core.paginator import Paginator >>> o
-
分页
当一次要在一个页面上显示很多数据时,通常需要将其分成几部分, 每个部分都包含一些数据列表并且一次只显示一部分。这些部分在网页上被称为分页。 Yii 使用 yii\data\Pagination 对象来代表分页方案的有关信息。特别地, total count 指定数据条目的总数。 注意,这个数字通常远远大于需要在一个页面上展示的数据条目。 page size 指定每页包含多少数据条目。 默认值为 2
-
分类
在上几章中我们使用用户对物品的评价来进行推荐,这一章我们将使用物品本身的特征来进行推荐。这也是潘多拉音乐站所使用的方法。 内容: 潘多拉推荐系统简介 特征值选择的重要性 示例:音乐特征值和邻域算法 数据标准化 修正的标准分数 Python代码:音乐,特征,以及简单的邻域算法实现 一个和体育相关的示例 特征值抽取方式一览 数据集: athletesTrainingSet.txt athletesTe
-
分号
Semicolons 分号 Like C, Go’s formal grammar uses semicolons to terminate statements, but unlike in C, those semicolons do not appear in the source. Instead the lexer uses a simple rule to insert semicol
-
分页
简介 在 Linux 内核启动过程中的第五部分,我们学到了内核在启动的最早阶段都做了哪些工作。接下来,在我们明白内核如何运行第一个 init 进程之前,内核初始化其他部分,比如加载 initrd ,初始化 lockdep ,以及许多许多其他的工作。 是的,那将有很多不同的事,但是还有更多更多更多关于内存的工作。 在我看来,一般而言,内存管理是 Linux 内核和系统编程最复杂的部分之一。这就是为什