《B站面经》专题
-
使用 Adobe Muse 创建响应式站点
注意: Adobe Muse 不再添加新增功能,并将于 2020 年 3 月 26 日停止支持。有关详细信息和帮助,请参阅 Adobe Muse 服务结束页面。 通过响应式网页设计这种方法,可创建能在各种设备(从台式机显示器到手机屏幕)上查看的网站。使用 Adobe Muse,不需要进行任何编码即可创建适合任何屏幕尺寸的响应式网站。响应式布局可让您的用户提供您网站的一致的浏览体验。 在之前的 Ad
-
静态网站构建工具 - Hugo简介
Hugo是由Steve Francis基于Go语言开发的静态网站构建工具。
-
静态网站构建工具 - Hexo简介
Hexo是一款使用node.js开发的静态网站构建工具,便于构建华丽绚烂的页面。
-
静态网站构建工具 - Jekyll简介
Jekyll 是最早开始流行的静态网站构建工具,使用Ruby语言开发,开源已有9个年头了,是Github Pages默认的静态网站构建工具。当前互联网上有大量基于jekyll构建的静态网站,包括现在流行的开源容器编排调度引擎kubernetes的官网。 Jekyll的理念 Jekyll网站构建的理念就是只做用户告诉它要做的事情,不多也不少: No Magic:简单易懂 It “Just Works
-
分布式缓存 - 网站群和缓存
现在假设我们有一个社交网站,有数以百万的用户简介,一些著名用户的简介页面每分钟有数百或数千人访问。 要生成一个用户简介,需要多个 SQL 查询(朋友、相册名称及照片总数、简介信息、最后状态等)。 只要用户没有更新个人资料,在个人资料页显示的信息几乎是静态的。因此,个人资料页的快照可以缓存 5 分钟或 1 小时等。 但这或许还不够。我们正在谈论数以百万的简介和用户。用户不会只查看一些简介页。我们需要
-
IIS下使用appcmd批量搭建网站
本文向大家介绍IIS下使用appcmd批量搭建网站,包括了IIS下使用appcmd批量搭建网站的使用技巧和注意事项,需要的朋友参考一下 使用 cmd 运行如下命令 修改 d 盘 下的 sites.xml 文件 包括批量新增的网站项目 在 cmd 中 使用如下命令导入 在 cmd 中 使用 如下命令重启IIS 刷新你的 iis .. 批量增加成功. 是不是很简单呢,小伙伴们自己参考下吧
-
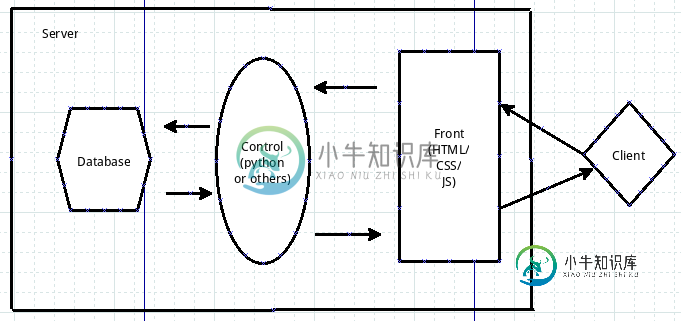 跟老齐学Python之网站的结构
跟老齐学Python之网站的结构本文向大家介绍跟老齐学Python之网站的结构,包括了跟老齐学Python之网站的结构的使用技巧和注意事项,需要的朋友参考一下 很早很早的时候,computer这个东西习惯于被称之为计算机,因为它的主要功能是完成一些科学计算的东西,我记得自己鼓捣它的时候,就是计算,根本就没有想到它有早一日还可以用来做别的。后来另外一个名字“电脑”逐渐被人们接收了,特别是网络发展起来之后,computer这个东西,
-
在Django网站中将HTML渲染为PDF
问题内容: 对于我的django网站,我正在寻找一种将动态html页面转换为pdf的简单解决方案。 页面包含HTML和来自Google可视化API的图表(该图表基于javascript,但必须包含这些图表)。 问题答案: 尝试从Reportlab解决方案。 下载并像往常一样使用python setup.py install安装 你还需要安装以下模块:具有easy_install的xhtml2pdf
-
使用node.js 制作网站前台后台
本文向大家介绍使用node.js 制作网站前台后台,包括了使用node.js 制作网站前台后台的使用技巧和注意事项,需要的朋友参考一下 node.js 能做什么?我至今也不清楚,他在哪方面应用比较广泛,我没有机会接触到那样的项目。只是因为喜欢,业余时间做了一个网站和后台。深刻领悟到一个道理那就是如果你喜欢一项技术可以玩玩,但是如果用到项目中就必须花些时间去解决很多问题。 使用到的技术: expr
-
使用PHP cURL登录到远程站点
问题内容: 我是使用cURL的新手,它很难为其找到好的资源。我想做的是通过curl来登录到远程站点,然后执行登录表单,然后将其发送回去。 我拥有的代码似乎无效,仅尝试显示网站的主页。 我究竟做错了什么。在此工作之后,我想重定向到另一个页面并从我的网站获取内容。 问题答案: 我已经放弃了好一阵子,但后来又重新讨论了。由于这个问题是定期查看。最终,这就是我最终使用的对我有用的东西。 更新:此代码绝不打
-
PHP获取站点URL协议-http与https
问题内容: 我写了一个小函数来建立当前站点的URL协议,但是我没有SSL,也不知道如何测试它是否可以在https下工作。 你能告诉我这是否正确吗? 是否有必要像上面那样做?还是我可以像上面那样做?: 在SSL下,即使定位标记网址使用的是http,服务器也不会自动将网址转换为https吗?是否需要检查协议? 谢谢! 问题答案: 这不是自动的。您的最高职能看起来还不错。
-
 ASP.NET网站模板的实现(第2节)
ASP.NET网站模板的实现(第2节)本文向大家介绍ASP.NET网站模板的实现(第2节),包括了ASP.NET网站模板的实现(第2节)的使用技巧和注意事项,需要的朋友参考一下 我们的主要学习任务是掌握站点地图文件和站点导航控件的使用以及熟练掌握创建母版页和生成内容页的方法,开始学习吧 学习内容: 第一步,网站的面包屑导航 1、创建ASP.NET应用程序,运行Visual Studio2008,在菜单栏中选择“文件”→“新建”→“项目
-
使用dropbox文件夹管理网站库
我正在尝试在网站上制作一张画廊照片,我的客户需要将这些照片上传到dropbox或google drive。 我已经嵌入了一个画廊从谷歌驱动器在我的网站和它完美的作品(这意味着我可以看到照片)。但是,当我点击一张照片时,它会在谷歌驱动器上重定向我,这不是一个好的渲染。 我也尝试过这个解决方案:从dropbox目录中拉取和显示网站库中的图像。这似乎是一个很好的解决方案,但不幸的是,没有出现在我的网站上
-
使用phatomJS和selenium滚动浏览网站
我需要在一个网页上滚动(例如twitter),并制作一个网站上出现的新元素的网络抓取。我试着用,和来做这个。这是我的密码 问题是我无法滚动到底部。和是相同的。但是如果我将从更改为,同样的代码可以正常工作。为什么?
-
使用登录信息刮网站与python
我正试图使用从我订阅的新闻网站上刮取文章。 我在电脑上的每个浏览器上都登录了网站(这不重要吗?),但每当我试图从特定文章中获取任何文本时,请使用以下命令: 页面=请求。得到(”http://www.SomeWebsite.com/blah/blah/blah.html") tree=html。fromstring(page.text) 文章=tree.xpath('//div/p/text()')