《原理》专题
-
DBSCAN原理和算法伪代码,与kmeans,OPTICS区别
本文向大家介绍DBSCAN原理和算法伪代码,与kmeans,OPTICS区别相关面试题,主要包含被问及DBSCAN原理和算法伪代码,与kmeans,OPTICS区别时的应答技巧和注意事项,需要的朋友参考一下 参考回答: DBSCAN聚类算法原理 DBSCAN(Density-Based Spatial Clustering of Applications with Noise)聚类算法,它是一种基
-
vue的双向绑定的原理,和angular的对比
本文向大家介绍vue的双向绑定的原理,和angular的对比相关面试题,主要包含被问及vue的双向绑定的原理,和angular的对比时的应答技巧和注意事项,需要的朋友参考一下 在不同的MWM框架中,实现双向数据绑定的技术有所不同。 AngulaJS采用‘‘脏值检测”的方式,数据发生变更后,对于所有的数据和视图的绑定关系进 行一次检测,识别是否有数据发生了改变,有变化进行处理,可能进一步引发其他数据
-
多线程中 synchronized 锁升级的原理是什么?
本文向大家介绍多线程中 synchronized 锁升级的原理是什么?相关面试题,主要包含被问及多线程中 synchronized 锁升级的原理是什么?时的应答技巧和注意事项,需要的朋友参考一下 synchronized 锁升级原理:在锁对象的对象头里面有一个 threadid 字段,在第一次访问的时候 threadid 为空,jvm 让其持有偏向锁,并将 threadid 设置为其线程 id,再
-
介绍一下,归并排序的原理是什么?
本文向大家介绍介绍一下,归并排序的原理是什么?相关面试题,主要包含被问及介绍一下,归并排序的原理是什么?时的应答技巧和注意事项,需要的朋友参考一下 考察点:归并排序 (1)归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。 (2)首先考虑下如何将将二个有序数列合并。这个非常简单,只要从比较二个数列的第一个数,谁小就先取谁
-
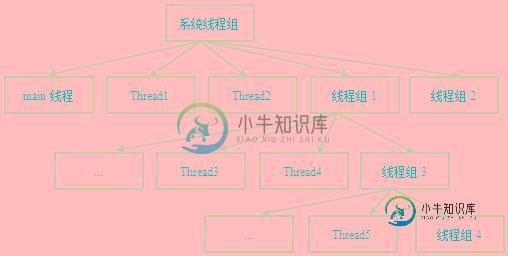 Java多线程 线程组原理及实例详解
Java多线程 线程组原理及实例详解本文向大家介绍Java多线程 线程组原理及实例详解,包括了Java多线程 线程组原理及实例详解的使用技巧和注意事项,需要的朋友参考一下 线程组 线程组可以批量管理线程和线程组对象。 一级关联 例子如下,建立一级关联。 输出结果如下 每隔三秒输出两个线程名称,符合预期。 线程组自动归组属性 输出结果如下 没有指定线程组,则归属到当前线程所属的组。 根线程组 运行结果 当前线程的线程组的父线程组是系统
-
js中数组排序sort方法的原理分析
本文向大家介绍js中数组排序sort方法的原理分析,包括了js中数组排序sort方法的原理分析的使用技巧和注意事项,需要的朋友参考一下 本文实例分析了js中数组排序sort方法的原理。分享给大家供大家参考。具体分析如下: 最近在百度的项目中要用到对数组进行排序,当然一开始自然想到了数组的sort方法,这方法应用非常简单,大致如下: 但是我突然想到,sort用法为什么这么简单,其原理到底是什么呢?于
-
Python参数传递对象的引用原理解析
本文向大家介绍Python参数传递对象的引用原理解析,包括了Python参数传递对象的引用原理解析的使用技巧和注意事项,需要的朋友参考一下 大家都知道在python中,一切皆对象,变量也不再具有类型,变量仅仅是对象的一个引用,我们通常用变量来测类型,通常测得就是被这个变量引用得对象的类型。 python采用的是传递对象的引用,为了方便说明,我们来看一个例子: 我们来看一下最后的输出: [1,3]
-
Spring 事务事件监控及实现原理解析
本文向大家介绍Spring 事务事件监控及实现原理解析,包括了Spring 事务事件监控及实现原理解析的使用技巧和注意事项,需要的朋友参考一下 前面我们讲到了Spring在进行事务逻辑织入的时候,无论是事务开始,提交或者回滚,都会触发相应的事务事件。本文首先会使用实例进行讲解Spring事务事件是如何使用的,然后会讲解这种使用方式的实现原理。 1. 示例 对于事务事件,Spring提供了一个注解@
-
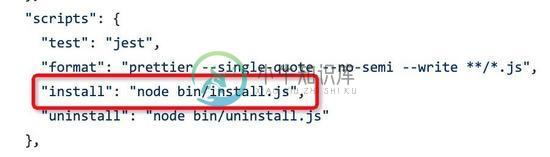 vue-cli创建的项目中的gitHooks原理解析
vue-cli创建的项目中的gitHooks原理解析本文向大家介绍vue-cli创建的项目中的gitHooks原理解析,包括了vue-cli创建的项目中的gitHooks原理解析的使用技巧和注意事项,需要的朋友参考一下 前言 在使用 vue create my-app 创建项目的时候,Vue 会自动帮我们做好一些预配置,你可以不使用它,但是一旦需要的时候,突然发现,咦~原来它已经帮我做好准备工作了,只需要按自己的需求配置一下就可以了,就会觉得 vu
-
Python接口自动化判断元素原理解析
本文向大家介绍Python接口自动化判断元素原理解析,包括了Python接口自动化判断元素原理解析的使用技巧和注意事项,需要的朋友参考一下 这篇文章主要介绍了Python接口自动化判断元素原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 背景: 在做接口自动化时,通常会判断接口返回中的数据信息,与数据库中返回的数据信息是否一致,比如:将接口
-
为什么识别如此纯净。发动机原理
如果我写的关于引擎的是正确的。 假设训练集基于大小为14pt的字体。图片中的符号被调整到特定的大小,我看不出在这种情况下它们不被识别的任何原因。 我还尝试了定制词典,以惩罚非词典词汇--这对识别没有太大好处。 老实说,我为什么要训练它?对于来自互联网的默认训练数据文本,或者PC(Mac)的屏幕,我得到了很好的识别。 我还检查了原始的tesseract英语训练数据,它有38个tiff文件,属于以下家
-
如何用界面分离原理实现多态性?
我的目标是理解接口隔离原则,同时实现多态性。 我的预期结果是:我可以用接口分离原理实现多态。 我的实际结果是:不,我不能。我被迫创建样板并使用Liskov替换原则(如果有一个Worker,必须有一个Worker不能吃,所以为Worker创建一个可以吃的扩展Worker的接口)。我想我误解了接口隔离原则。 这是违反接口隔离原则的代码。 我被告知将接口分成两部分。 解决方法是使用Liskov替换原理。
-
Azure密钥保险库服务原理验证失败
为此挣扎了一天,终于寻求帮助了。我试图使用Azure密钥库在Typescript应用程序中存储一些配置。我在Azure Active Directory中创建了一个服务原则和一个密钥库。在Key Vault中,我进入了角色分配,并给了应用程序角色Key Vault秘密用户(应该提供列表和读取权限)。据我所知,我的应用程序正在成功地进行身份验证,但当它请求一个秘密时,它得到了一个403。我会漏掉哪一
-
 为什么纹理图像颜色与原点不同?
为什么纹理图像颜色与原点不同?我正在使用 LWJGL(适用于 Java 的开放GL)库进行纹理映射。以下是从文件中读取图像的代码: 以字节数组形式获取数据栅格(图像像素)的代码: 现在,创建“bytePixels”数组并将其放入字节缓冲区的代码: 这里用于将所有这些绑定到缓冲区: 问题是,图像纹理的颜色与原始图像颜色不同! 原始图片: 纹理图像: 这个答案OpenGL渲染纹理与原始图像颜色不同?,不能解决这个问题,因为在lwj
-
架构原理 - segment merge对写入性能的影响
通过上节内容,我们知道了数据怎么进入 ES 并且如何才能让数据更快的被检索使用。其中用一句话概括了 Lucene 的设计思路就是”开新文件”。从另一个方面看,开新文件也会给服务器带来负载压力。因为默认每 1 秒,都会有一个新文件产生,每个文件都需要有文件句柄,内存,CPU 使用等各种资源。一天有 86400 秒,设想一下,每次请求要扫描一遍 86400 个文件,这个响应性能绝对好不了! 为了解决这