《Keep内推》专题
-
分析算法-递推方程(河内塔)
我在维基百科上看到这个求解河内塔的递归算法。谁能给我解释一下我是怎么得到这个算法的递推方程的? null 将N-1个光盘从A移动到B,这将使光盘n单独位于peg A上 将磁盘n从A移动到C 将N-1个光盘从B移动到C,使它们位于光盘N上 上面是一个递归算法,为了执行步骤1和3,对n-1再次应用相同的算法。整个过程是一个有限的步骤,因为在某一点上,算法将需要n=1。这一步,将单个光盘从pega移动到
-
 校园大使面经| SHEIN内推码💥
校园大使面经| SHEIN内推码💥💥💥💥专属内推码【DSyjD21W】,免筛选直通测评! 面试总共氛围4分部分,分别是自我介绍、hr提问、hr对公司介绍、反问。 【自我介绍】 这个部分我我介绍了我的学校专业、过往实习经历,最后说了我为什么想要来参加shein校园大使。(这个部分可以着重突出你的优势,比如你的院校是不是target school,自身在运营上的擅长、对shein的了解等等) 【hr提问】 SHEIN的hr感觉都
-
 招银网络科技java面经内推
招银网络科技java面经内推分享一下之前招银一面的一些流程和问题 笔试通过后一面二面的一些问题 先自我介绍 一面一般比较看基础 Start run 区别 Hashtable Hashset 布控过滤器 Redis 持久化 key失效策略 为什么快 二面一般设计到项目: 秒杀项目设计 项目内容设计技术 3.多线程sys lock 后面顺利的话静待HR面吧 下面是个内推码 #春招#
-
Java正则表达式提取方括号内的内容
问题内容: 输入线在下面 你能帮我写一个Java正则表达式来提取 从上方输入线? 问题答案: 更加简洁:
-
措词内容和流内容之间有什么区别?
问题内容: 我是HTML和CSS的新手,我想知道流内容和短语内容之间的区别。除了W3官方文档之外,MDN文档也很有帮助,并指出: 流内容定义如下: 属于流内容类别的元素通常包含文本或嵌入的内容。 短语内容定义如下: 短语内容定义了文本及其包含的标记。措辞内容由段落组成。 但是,文档在两者之间几乎没有什么区别,有人可以说明措辞内容和流程内容之间的主要区别是什么吗? 问题答案: 记住的最简单方法是,如
-
java中堆内存与栈内存的知识点总结
本文向大家介绍java中堆内存与栈内存的知识点总结,包括了java中堆内存与栈内存的知识点总结的使用技巧和注意事项,需要的朋友参考一下 一、概述 在Java中,内存分为两种,一种是栈内存,另一种就是堆内存。 二、堆内存 1、什么是堆内存? 堆内存是Java内存中的一种,它的作用是用于存储Java中的对象和数组,当我们new一个对象或者创建一个数组的时候,就会在堆内存中开辟一段空间给它,用于存放。
-
Spark驱动程序内存和应用程序主内存
我是否正确理解了客户端模式的文档? 客户端模式与驱动程序在应用程序主程序中运行的集群模式相反? 在客户端模式下,驱动程序和应用程序主程序是独立的进程,因此+必须小于计算机的内存? 在客户端模式下,驱动程序内存不包括在应用程序主内存设置中吗?
-
 请问虚拟内存和物理内存怎么对应
请问虚拟内存和物理内存怎么对应本文向大家介绍请问虚拟内存和物理内存怎么对应相关面试题,主要包含被问及请问虚拟内存和物理内存怎么对应时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 1、概念: 物理地址(physical address) 用于内存芯片级的单元寻址,与处理器和CPU连接的地址总线相对应。 虽然可以直接把物理地址理解成插在机器上那根内存本身,把内存看成一个从0字节一直到最大空量逐字节的编号的大数组,然后把
-
请你说一说C++内存溢出和内存泄漏
本文向大家介绍请你说一说C++内存溢出和内存泄漏相关面试题,主要包含被问及请你说一说C++内存溢出和内存泄漏时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 1、内存溢出 指程序申请内存时,没有足够的内存供申请者使用。内存溢出就是你要的内存空间超过了系统实际分配给你的空间,此时系统相当于没法满足你的需求,就会报内存溢出的错误 内存溢出原因: 内存中加载的数据量过于庞大,如一次从数据库取出过多
-
 Django之富文本(获取内容,设置内容方式)
Django之富文本(获取内容,设置内容方式)本文向大家介绍Django之富文本(获取内容,设置内容方式),包括了Django之富文本(获取内容,设置内容方式)的使用技巧和注意事项,需要的朋友参考一下 富文本 1、Rich Text Format(RTF) 微软开发的跨平台文档格式,大多数的文字处理软件都能读取和保存RTF文档,其实就是可以添加样式的文档,和HTML有很多相似的地方 图示 2、tinymce插件 安装插件 pip instal
-
Django admin-内联内联(或一次编辑三个模型)
问题内容: 我有一组看起来像这样的模型: 和一个看起来像这样的: 我的目标是获得一个管理界面,使我可以在一页上编辑所有内容。这种模型结构的最终结果是,事物被生成到一个视图+模板中,看起来或多或少像: 我知道,如我所料,内联的内联技巧在Django管理员中失败。有人知道允许这种三级模型编辑的方法吗?提前致谢。 问题答案: 你需要创建一个自定义表单和模板的。 像这样的东西应该适用于以下形式: (那只是
-
为什么C#内存流保留了这么多内存?
我们的软件正在通过一个从内存流读取数据的GZipStream解压某些字节数据。这些数据以4KB的块解压缩,并写入另一个内存流。 我们已经意识到进程分配的内存远高于实际解压的数据。 示例:具有2425536字节的压缩字节数组被解压缩为23050718字节。我们使用的内存分析器显示了方法MemoryStream。设置容量(Int32值)分配的67104936字节。这是保留内存和实际写入内存之间的2.9
-
如何忽略ANTLR中大括号内的任意内容?
我正在尝试编写一个配置文件语法并让ANTLR4来处理它。我对ANTLR很陌生(这是我第一个使用它的项目)。 在很大程度上,我理解大多数配置文件语法需要做什么(或者至少我认为我需要做什么),但我将要阅读的文件将在大括号内包含任意C代码。以下是一个示例: 类似于: 可能有很多这样的人。我似乎无法让它理解我只想忽略(不跳过)源代码。以下是我迄今为止的语法: 问题是,我在C\U BLOCK lexer规则
-
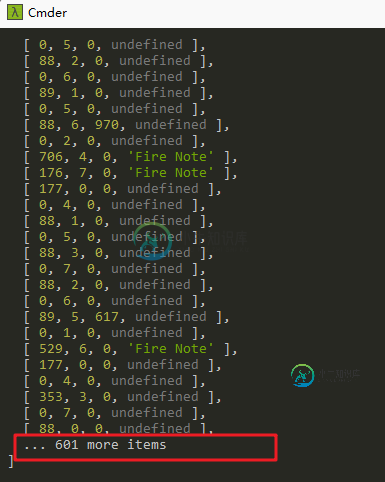 内容太长,如何在console.log()中显示完整内容?
内容太长,如何在console.log()中显示完整内容?我有一个很大的数组,它有很多元素,我需要在控制台中显示它,我使用console.log(),但只显示了一部分。 如何显示完整的内容?
-
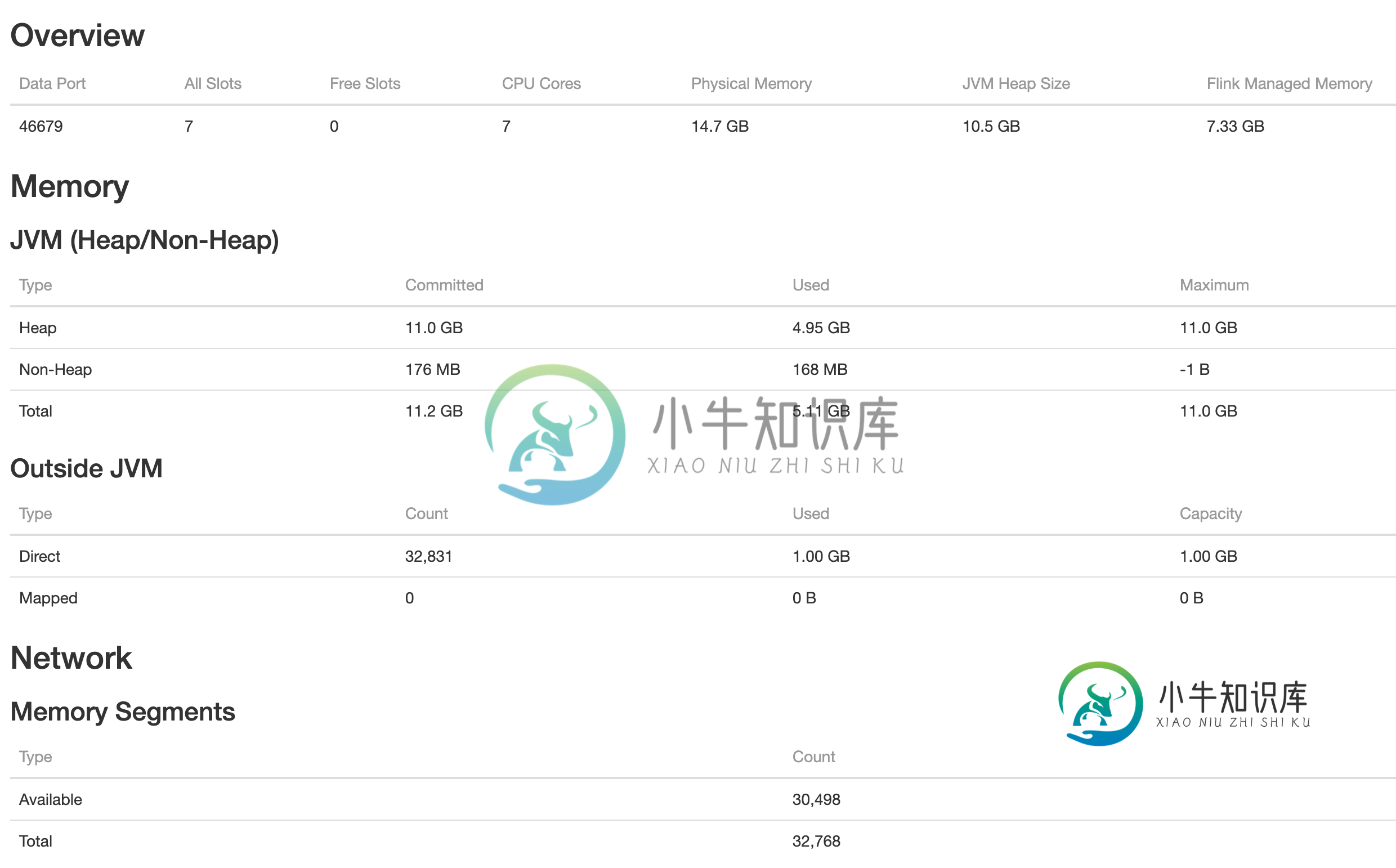 Apache Flink:与网络内存段的直接内存关系
Apache Flink:与网络内存段的直接内存关系我正在运行Flink 1.8版。 主要配置如下: 声明的堆大小是12GB,为什么在概述部分显示为7.33GB。 根据文档,堆大小=声明的堆大小-网络缓冲区内存(默认值:声明的堆的0.1倍,但最大为1gb)。所以正确的值是JVM(堆/非堆)部分中显示的值,即11GB :我假设,由于现在使用1GB作为网络缓冲内存,因此32768段基本上是指32KiB大小的内存段的计数。这些用于在任务之间传输数据的TC