《同花顺2023春招交流讨论》专题
-
 2023秋招提前批 | 中兴未来领军算法工程师
2023秋招提前批 | 中兴未来领军算法工程师写在前面 四个面试官,问的很全面,自己没准备好,面试的时候就知道过不了了。面试之后,根据面试官问的问题梳理了下知识点,感觉学到了很多。 应聘岗位 算法工程师(知识图谱&图像处理) 一面 基础知识 介绍一下指针,指向指针的指针 熟悉什么网络协议,介绍一下 TCP和UDP有什么区别 说一下TCP的拥塞控制 介绍一下数据结构 介绍一下图像变换 什么是面向对象编程 机器学习 如何实现卷积 知道矩阵加速的方
-
 2023届秋招百度安全部产品经理面试凉经
2023届秋招百度安全部产品经理面试凉经23届秋招|百度产品经理安全部一面偏凉经 这里是CUI's Job Studio📞,没想到秋招提前批在匆匆忙忙的百度产品经理一面中开始了。 我的基本情况:985硕/新传/产品经理实习经理仅一个月 投递事件:7月17日 约一面时间:7月21日 面试部门:安全部产品经理岗 就让这次的面试经历开启我的秋招准备之路吧~每次面试笔试也都会在小红书分享经验,希望能给同样热爱互联网的同学们有点帮助。 第一部分
-
 2023年秋招多维感知算法岗面经笔经汇总
2023年秋招多维感知算法岗面经笔经汇总公司 笔面试 内容 虹软(杭州),视觉服务提供商 笔试过,一面挂 三维感知算法岗,主要是问项目,问得很细,比如ICP的原理、点云的修复、网格的重建等。需要对原理有较深的理解。还问了一道中等难度算法题。 大华(杭州),安防摄像头 笔试过,二面挂 多维感知算法工程师,电话面试,两轮面试都是15分钟左右。第一轮同事面,主要问了项目、相机标定、C++等内容。问得比较基础。第二轮主管面,问了视觉方面的内容。
-
 迪普科技2023届秋招面经-售前技术工程师
迪普科技2023届秋招面经-售前技术工程师一面-业务面30min-10/13 自我介绍 介绍下你的家乡 大学里你最喜欢的两门专业课 简历中各种数据站了很大篇幅,为什么? 你了解网络安全吗? 你对这个岗位的理解?你有什么优势?过往你觉得最匹配的经历是什么? 最有成就感的事情 你觉得你抗压能力很强吗?举个例子 反问:对同学的期望(学习能力、开心、抗压、做自己保持特点和竞争力) 二面-HR面20min-10/24 主要围绕简历和个人情况做了进一
-
 迪普科技2023届秋招面经-售前技术工程师
迪普科技2023届秋招面经-售前技术工程师迪普科技2023届秋招面经-售前技术工程师 一面-业务面30min-10/13 自我介绍 介绍下你的家乡 大学里你最喜欢的两门专业课 简历中各种数据站了很大篇幅,为什么? 你了解网络安全吗? 你对这个岗位的理解?你有什么优势?过往你觉得最匹配的经历是什么? 最有成就感的事情 你觉得你抗压能力很强吗?举个例子 反问:对同学的期望(学习能力、开心、抗压、做自己保持特点和竞争力) 二面-HR面20min
-
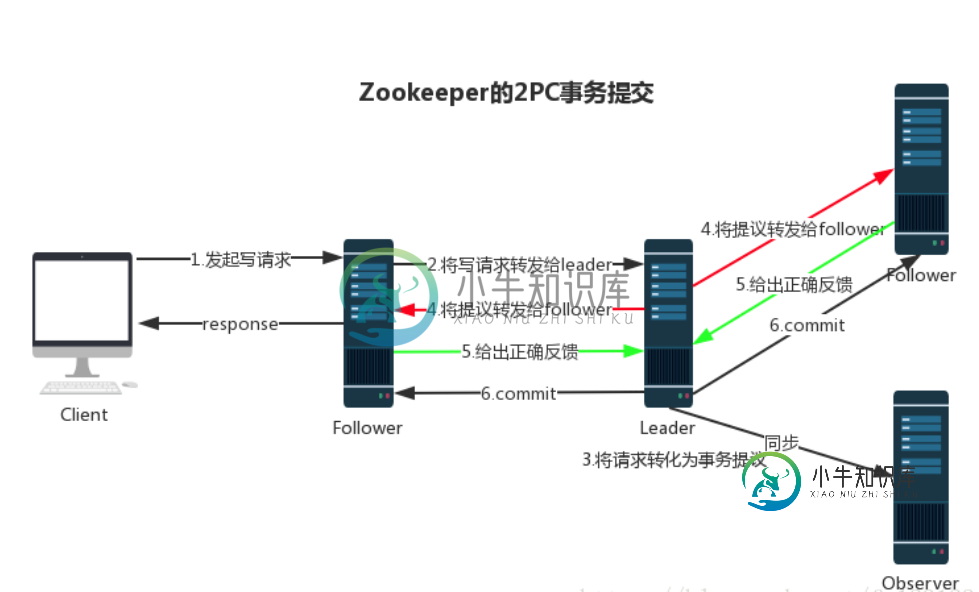 12.0 Zookeeper 数据同步流程
12.0 Zookeeper 数据同步流程在 Zookeeper 中,主要依赖 ZAB 协议来实现分布式数据一致性。 ZAB 协议分为两部分: 消息广播 崩溃恢复 消息广播 Zookeeper 使用单一的主进程 Leader 来接收和处理客户端所有事务请求,并采用 ZAB 协议的原子广播协议,将事务请求以 Proposal 提议广播到所有 Follower 节点,当集群中有过半的Follower 服务器进行正确的 ACK 反馈,那么Lea
-
在两个片段之间进行交流
我的应用程序中有三个片段,其中需要传递和接收数据。我应该如何进行他们之间的沟通。我试图参考许多网站,但没有解决方案。 请给我推荐一些好的链接。 提前感谢。
-
如何交错(合并)两个Java 8流?
问题内容: 对于下面的输出,我需要做什么? 我调查了一下,但是正如javadoc所解释的,它只是一个接一个地追加,它不会交错/散布。 创建一个延迟串联的流,其元素是第一个流的所有元素,后跟第二个流的所有元素。 错误地给 如果我收集它们并进行迭代,但是希望获得更多Java8-y,Streamy :-),可以这样做 注意 我不想压缩流 “ zip”操作将从每个集合中获取一个元素并将其组合。 压缩操作的
-
如何交织(合并)两个Java 8流?
我需要做什么才能使输出如下所示? 我查看了concat,但正如javadoc所解释的,它只是一个接一个地附加,而不是交错/穿插。 创建一个延迟连接的流,其元素是第一个流的所有元素,然后是第二个流的所有元素。 错误地给予 如果我收集它们并迭代,可以做到这一点,但希望有更多的Java8-y,Streamy:-) 笔记 我不想让溪流断流 “zip”操作将从每个集合中获取一个元素并将其组合。 zip操作的
-
嵌入式Kafka与真实课堂交流
我有一个Spring Boot应用程序,可以使用和。我有一位制片人。 我想写JUnit上面没有任何嘲弄类。我尝试了,但我不确定如何将其连接到我的应用程序定义的kafka代理,所以当我发送主题消息时,消费者(其中存在)应该选择消息并处理它。 有了我也得到了下面的错误。 有人能告诉我如何在不模仿任何类的情况下为我的Kafka制作人编写Junit,它应该用真实的类进行测试。
-
提交云数据流作业时出错
-
 百度测开暑期0410笔试交流
百度测开暑期0410笔试交流百度用的赛码网考,需要开摄像头,笔试包括30道选择题60分,两道编程题40分 题目一:优惠券这道题笔试时a了27%,笔试后发牛客上有佬给做了指正,我觉得应该是可以的了 题目描述:在L-R闭区间内,取一个整数x,优惠计算方式=x *(x的各位数字之和),问最大的优惠是多少? 例:[3,6],取3时,优惠为3*3=9,取4时,优惠为4*4=16,...因此最大优惠为6*6=36 再比如[28,31],
-
Kafka分区是如何在火花流与Kafka共享的?
我想知道Kafka分区是如何在从executor进程内部运行的SimpleConsumer之间共享的。我知道高水平的Kafka消费者是如何在消费者群体中的不同消费者之间分享利益的。但是,当Spark使用简单消费者时,这是如何发生的呢?跨计算机的流作业将有多个执行程序。
-
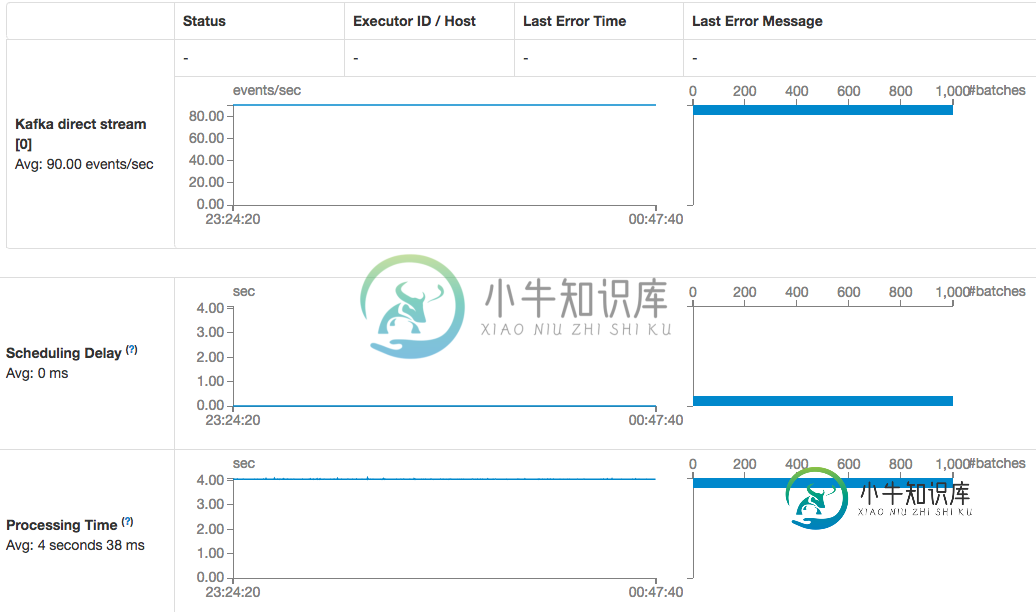 火花流Kafka直接消费者消费速度下降
火花流Kafka直接消费者消费速度下降我使用的是运行在AWS中的spark独立集群(spark and spark-streaming-kafka version 1.6.1),并对检查点目录使用S3桶,每个工作节点上没有调度延迟和足够的磁盘空间。 没有更改任何Kafka客户端初始化参数,非常肯定Kafka的结构没有更改: 也不明白为什么当直接使用者描述说时,我仍然需要在创建流上下文时使用检查点目录?
-
火花流从Kafka源返回到检查点或重绕
当streaming Spark DStreams作为来自Kafka源的消费者时,可以检查Spark上下文,因此当应用程序崩溃(或受到的影响)时,应用程序可以从上下文检查点恢复。但如果应用程序“意外地部署了错误的逻辑”,您可能想要倒回到最后一个主题+分区+偏移量,以重播某个Kafka主题的分区偏移量位置的事件,这些位置在“错误逻辑”之前正常工作。当检查点生效时,流式应用程序如何被重绕到最后的“好点