《同花顺2023春招》专题
-
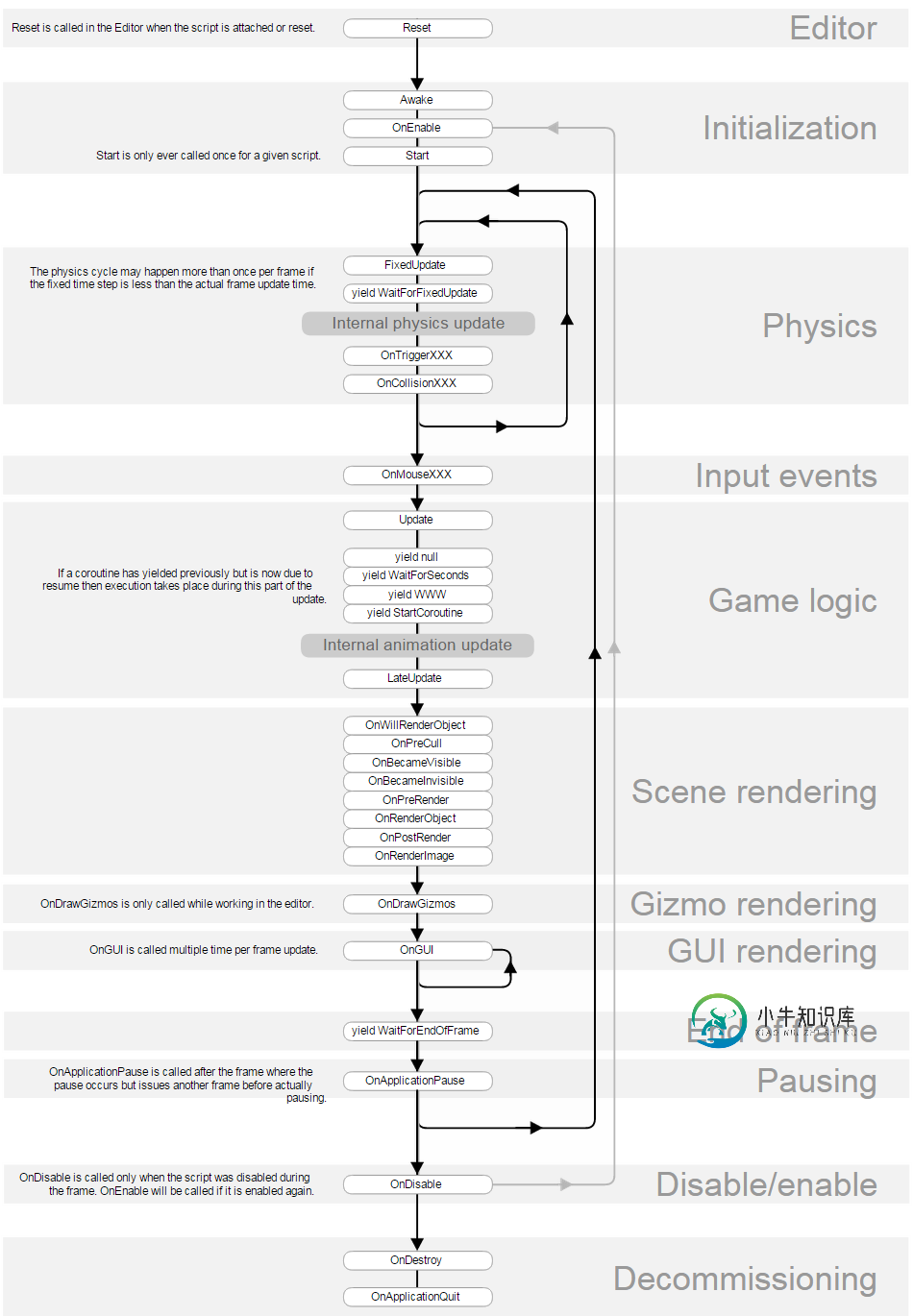 Unity3D中脚本的执行顺序和编译顺序
Unity3D中脚本的执行顺序和编译顺序本文向大家介绍Unity3D中脚本的执行顺序和编译顺序,包括了Unity3D中脚本的执行顺序和编译顺序的使用技巧和注意事项,需要的朋友参考一下 事件函数的执行顺序 先说一下执行顺序吧。 官方给出的脚本中事件函数的执行顺序如下图: 我们可以做一个小实验来测试一下: 在Hierarchy视图中创建三个游戏对象,在Project视图中创建三条脚本,如下图所示,然后按照顺序将脚本绑定到对应的游戏对象上:
-
SQL排序顺序按查询中指定的顺序
问题内容: 假设我有一个查询“ select * from子句,其中id在(0,2,5,1,3)中”,我实际上希望返回的行以它们在where子句中指定的相同顺序返回。ID的顺序将随查询的不同而改变,并且该顺序没有模式。 我知道可以更改数据模型,创建临时表等。但是请相信我,这些类型的解决方案在我的情况下将行不通。我也无法在应用程序代码中更改结果对象的顺序。 我还知道,不同的数据库引擎对事物的排序方式
-
顺序磁盘读取实际上是顺序的吗?
问题内容: 我正在使用PostgreSQL 9.4。 首先,我在只有一个-drive的系统上安装了postgreSQL 。 我试图了解什么是顺序读取,并最终遇到一些问题。例如,如果我们要求SQL Server提供一些未索引的数据,则可能会发生seq- scan。但是,如果两个不同的客户端同时从两个不同的表中请求数据怎么办?在这种情况下,sql-server为每个客户端创建两个不同的进程并同时执行查
-
如何在Oracle10g中按顺序连接多行顺序
问题内容: 如果我有这样的数据: 我如何将命令连接成这样: 我在下面使用了此查询,但命令列的顺序不依其顺序号而定: 任何意见和建议将不胜感激。^ _ ^ 问题答案: 永远不要使用。阅读为什么不在Oracle中使用WM_CONCAT函数? 请参阅本主题https://stackoverflow.com/a/28758117/3989608。 它没有记录,并且依赖的任何应用程序一旦升级到后都将无法工作
-
按顺序排序是否保证选择的顺序?
问题内容: 我认为使用某种顺序才有意义。我想做的是在视图中包括该子句,以便该视图上的所有s都可以忽略它。但是,我担心该订单不一定会延续到,因为它没有指定订单。 是否存在一种情况,即视图指定的顺序不会反映在该视图上的select结果中(该视图中的order by子句除外)? 问题答案: 您不能指望没有显式子句的任何查询中的行顺序。如果查询有序视图,但没有包括子句,则如果它们的顺序正确,请感到惊喜,并
-
 顺丰产品一面,希望可以顺利通过!
顺丰产品一面,希望可以顺利通过!顺丰一面: 自我介绍 遇到什么困难的问题,怎么解决的? 互联网几大盈利模式 B站对你来说有什么痛点 顺丰你觉得有什么需要改进的? 你有什么要问的吗?
-
附加到拼花文件的EMR Spark步骤正在覆盖拼花文件
使用Python 3.6在Amazon EMR集群(1个主节点,2个节点)上运行Spark 2.4.2 我正在Amazon s3中读取对象,将其压缩为拼花格式,并将其添加(附加)到现有的拼花数据存储中。当我在pyspark shell中运行代码时,我能够读取/压缩对象,并将新的拼花文件添加到现有的拼花文件中,当我对拼花数据运行查询时,它显示所有数据都在拼花文件夹中。但是,当我在EMR集群上的步骤中
-
火花:无法从HDFS加载拼花文件,直到将它们“放入”hdfs
我有一个c#应用程序,可以创建拼花地板文件并将其上载到远程HDFS。如果我使用scp将文件复制到安装了HDFS客户端的目标计算机上,然后将文件“HDFS放入”HDFS中,spark可以正确读取文件。 如果我使用curl针对webhdf服务从客户端应用程序直接将文件上传到HDFS,则在尝试读取拼花文件时会从Spark收到以下错误: df=sqlContext。阅读parquet(“/tmp/test
-
组织。阿帕奇。火花SparkException:任务不可序列化。斯卡拉火花
将现有应用程序从Spark 1.6移动到Spark 2.2*(最终)会导致错误“org.apache.spark.SparkExctive:任务不可序列化”。我过于简化了我的代码,以演示同样的错误。代码查询拼花文件以返回以下数据类型:“org.apache.spark.sql.数据集[org.apache.spark.sql.行]”我应用一个函数来提取字符串和整数,返回字符串。一个固有的问题与Sp
-
Regex:在花括号之间查找字符串,它本身包含花括号
假设一个字符串的格式如下: 我想提取: 什么正则表达式可以用于这样的提取? 我被这个困住了:
-
比较2 list是否以任何顺序包含相同的元素[JUnit-Asset]
我想通过使用JUnit创建单元测试来测试某些字符串列表是否正确生成。 我有两个字符串列表(我的代码中的一个列表是private static final,比方说列表1),它们以不同的顺序使用相同的元素(相同的元素可以相乘): 我不想使用这种类型的函数,因为它只适用于少量元素:
-
只反转字符串中的字母,并保持单词的顺序相同
我只需要反转字符串中的字母,并使用将符号和数字保持在相同的位置,并且我还需要保持反转单词的相同顺序。我的代码反转字符串并将符号和数字保持在适当的位置,但更改单词的顺序,例如: 我的输入字符串: a1bcd efg!H 我的输出字符串: h1gfe dcb!A. 相反,我的输出应该是: d1cba hgf! e
-
使用键控协同处理函数的 Flink 超时 FlinkKafkaConsumer 的读取顺序
我使用Flink数据流API中的< code > keyedcorprocessfunction 类来实现一个超时用例。场景如下:我有一个输入kafka主题和一个输出kafka主题,一个服务从输入主题中读取并处理它(持续可变的时间),然后在输出Kafka主题中发布响应。 现在要实现超时(必须使用Flink datastream API),我有一个从kafka输入主题读取的和另一个从kafka输出主
-
为什么两个火花流作业从具有相同组id的相同Kafka主题拉消息不平衡负载,但得到相同的消息?
Kafka 0.8官方文档对Kafka消费者描述如下: “消费者用一个消费者组名称给自己贴标签,发布到主题的每条消息都被传递到每个订阅消费者组中的一个消费者实例。消费者实例可以在不同的进程中或在不同的机器上。如果所有消费者实例都有相同的消费者组,那么这就像传统的队列平衡消费者的负载一样。” 我用Kafka0.8.1.1设置一个Kafka集群,并使用Spark Streaming作业(Spark 1
-
 (23春招)航旅纵横(中航信)-测开-一面
(23春招)航旅纵横(中航信)-测开-一面2023/2/7 17mins 自我介绍 本科生为啥会有两端实习经历 学校不管你们实习吗 Java后端开发,谈谈自己的理解,编写一个接口的过程 补充:service层和dao层的细节 mybatis和springboot怎么集成 补充:引包,maven依赖引入 前端了解多少 找到工作了吗 为什么没有留在实习公司 redis的哨兵模式 redis的数据机构 反问:业务、技术栈相关;多久出结果和反馈#