《集度》专题
-
.NET Core垃圾收集
主要内容:垃圾收集的优势,垃圾收集的条件,阶段过程在本章中,我们将介绍垃圾收集的概念,垃圾收集是.NET托管代码平台最重要的特性之一。 垃圾收集器(GC)管理内存的分配和释放。 垃圾收集器用作自动内存管理器。 我们不需要知道如何分配和释放内存或管理使用该内存的对象的生命周期 每当使用关键字声明对象或将值类型装箱时,都会进行分配。分配通常非常快。 当没有足够的内存分配一个对象时,GC必须收集和处理垃圾内存以使内存可用于新的分配。 这个过程被称为垃圾
-
Java16 垃圾收集器
Java 15 使 ZGC、Z 垃圾收集器成为标准功能。它是 Java 15 之前的一个实验性功能。它是低延迟、高度可扩展的垃圾收集器。 ZGC 是在 Java 11 中作为一项实验性功能引入的,因为开发人员社区认为它太大而无法提前发布。 即使在机器学习应用程序等海量数据应用程序的情况下,ZGC 也具有高性能和高效工作。它确保在处理数据时不会因垃圾收集而长时间停顿。它支持 Linux、Window
-
Java15 垃圾收集器
Java 15 使 ZGC、Z 垃圾收集器成为标准功能。它是 Java 15 之前的一个实验性功能。它是低延迟、高度可扩展的垃圾收集器。 ZGC 是在 Java 11 中作为一项实验性功能引入的,因为开发人员社区认为它太大而无法提前发布。从那时起,对这个垃圾收集做了很多改进,例如 - 并发类卸载 取消提交未使用的内存 支持班级数据共享 NUMA 多线程堆Pre-touch 最大堆大小限制从 4 T
-
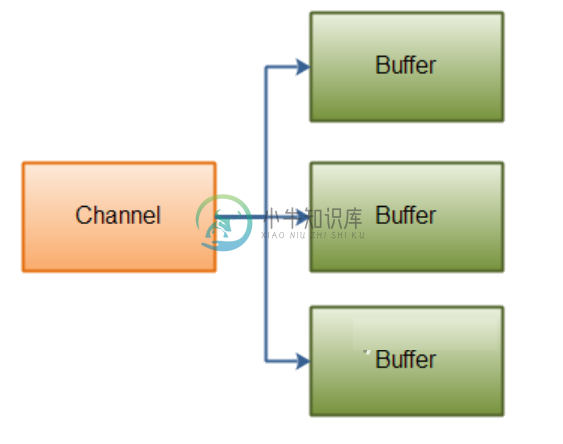 Java NIO 分散/聚集
Java NIO 分散/聚集主要内容:1 分散/聚集的介绍,2 分散读取,3 聚集写入1 分散/聚集的介绍 Java NIO带有内置的分散/聚集功能。分散/聚集是在读取和写入Channel中使用的概念。 从Channel分散读取是将数据读取到多个缓冲区中的读取操作。因此,通道将数据从通道“分散”到多个缓冲区中。 对Channel的聚集写入是一种将来自多个缓冲区的数据写入单个通道的写入操作。因此,通道将来自多个缓冲区的数据“聚集”到一个Channel中。 在需要分别处理传输数据的各个
-
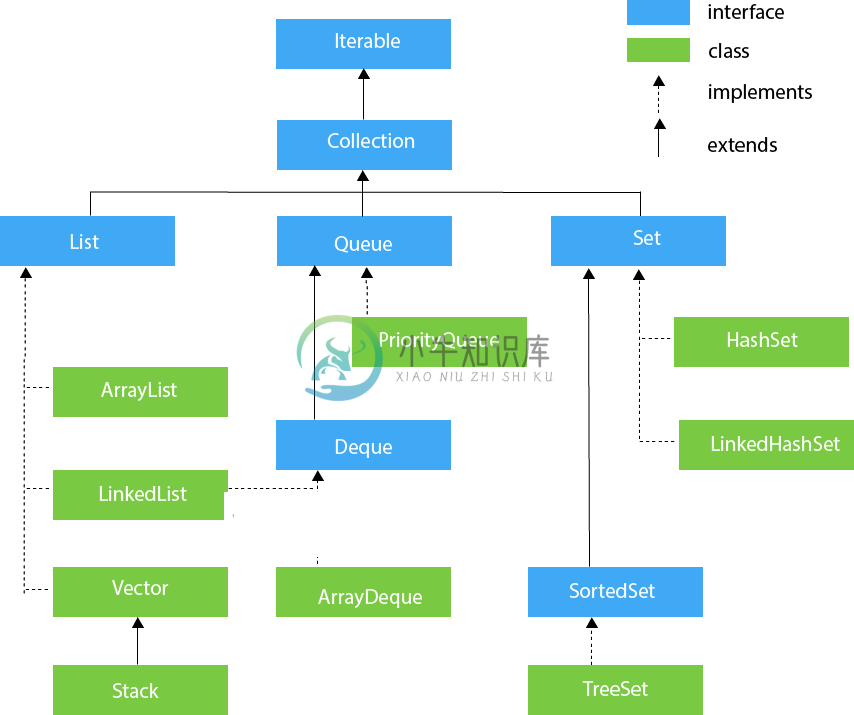 什么是Java集合
什么是Java集合主要内容:1 什么是Java集合,2 Java集合层次结构,3 Java Collection接口的方法,4 Iterator接口,5 Iterable接口,6 Collection接口,7 List接口,6 ArrayList,7 LinkedList,8 Vector,9 Stack,10 Queue接口,11 PriorityQueue,12 Deque接口,13 ArrayDeque,14 Set接口,15 HashSet,16 LinkedHashSet,17 SortedSet接口,
-
Spring Data Redis集成Fastjson
主要内容:1 XML配置方式,2 注解方式通常我们在 Spring 中使用 Redis 是通过 Spring Data Redis 提供的 RedisTemplate 来进行的,如果你准备使用 JSON 作为对象序列/反序列化的方式并对序列化速度有较高的要求的话,建议使用 Fastjson 提供的 GenericFastJsonRedisSerializer 或 FastJsonRedisSerializer 作为 RedisTempla
-
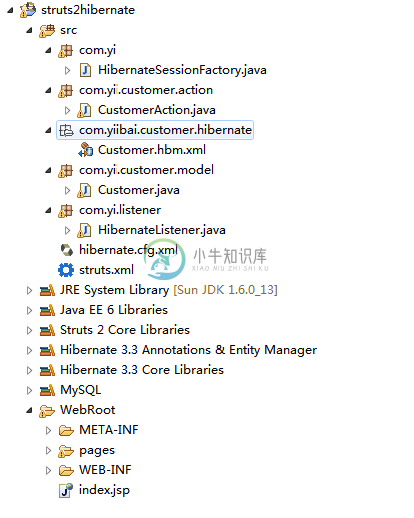 Struts2+Hibernate集成实例
Struts2+Hibernate集成实例主要内容:1. 工程目录结构,2. MySQL表结构脚本,4. Hibernate 相关配置,5. Hibernate ServletContextListener,6. Action,7. JSP 页面,8. struts.xml,9. 实例测试执行,参考在 Struts2 中,没有官方的插件集成Hibernate框架。但是,可以通过以下步骤解决方法: 注册一个自定义的 ServletContextListener 在 ServletContextListener 类, 初始化Hibernat
-
 Struts2+Spring集成实例
Struts2+Spring集成实例主要内容:1. 工程结构,2. Spring监听器,3. 注册Spring Bean,4. Struts.xml,5. 示例,用例1,用例 2,参考在本教程中,我们来学习Struts2和Spring的集成。 1. 工程结构 下面的图是本教程的项目文件夹结构。 2. Spring监听器 配置Spring监听器 “org.springframework.web.context.ContextLoaderListener” 到 web.xml 文件中。 web.xml 3. 注册Spring Bean
-
Hibernate值收集标准
问题内容: 我正在尝试使用Hibernate进行复杂的查询。我一直倾向于“标准”,但是我开始怀疑这是不可能的,因此任何建议都将有所帮助。 我有一个如下的实体结构: 这些实体与您期望的相关: 现在,我希望能够采用一组属性/值对(字符串)并找到包含 所有 属性/值对的所有实例。在“值”中,只有attribute和localAttributeName中的一个为非空值,因此属性名称可以与localAttr
-
Java集合(LIFO结构)
问题内容: 我正在寻找Java的LIFO结构(堆栈)的Collections框架,但没有成功。基本上,我想要一个非常简单的堆栈;我最好的选择是Deque,但是我使用Java 1.5。 我不想不必在我的结构中添加另一个类,但是我想知道是否可行: Collections框架(1.5)中是否有任何类可以完成这项工作? 如果没有,是否有任何方法可以在不重新实现的情况下在LIFO队列(又称为堆栈)中转换队列
-
集合的removeAll方法
问题内容: 我想知道以下可能的事情, 我希望上下文是可以理解的。 的类型是其中有一个方法。 的是要除去的对象的包含姓名。 我知道可以通过在类中重写equals方法来实现。我想知道是否还有其他选择。 问题答案: 您可以使用Google收藏夹执行以下操作 :
-
将Spring与IntelliJ集成
问题内容: 我已经下载并安装了Spring工具套件。现在,当我尝试在IntelliJ中创建新项目时,它在库中没有显示Spring。如何在其中获取Spring? 提前致谢! 问题答案: 在SpringSource工具套件具有无关的IntelliJ IDEA ,实际上它是一个不同的IDE(这是一个专门的Eclipse分布)。 因此,尽管下载Spring 框架 确实有意义(尽管最好通过Maven之类的构
-
 蚂蚁集团 一面
蚂蚁集团 一面9.17 14:00 换了一次时间 提前5分钟面试官来了 问了项目 python数据类型 HTTP含义 http https区别 get post区别 cookie session区别 进程线程 进程锁 数据库索引和视图 20分钟左右的题 代码题 python的 不难 但我字典那边很久没写 给忘了 数据库 查找成绩>80分的学生姓名 多条成绩怎么查 后面介绍了一下公司业务 反问 问了题的问题
-
集合类型综述
一、集合简介 Scala 中拥有多种集合类型,主要分为可变的和不可变的集合两大类: 可变集合: 可以被修改。即可以更改,添加,删除集合中的元素; 不可变集合类:不能被修改。对集合执行更改,添加或删除操作都会返回一个新的集合,而不是修改原来的集合。 二、集合结构 Scala 中的大部分集合类都存在三类变体,分别位于 scala.collection, scala.collection.immutab
-
Flink Standalone 集群部署
一、部署模式 Flink 支持使用多种部署模式来满足不同规模应用的需求,常见的有单机模式,Standalone Cluster 模式,同时 Flink 也支持部署在其他第三方平台上,如 YARN,Mesos,Docker,Kubernetes 等。以下主要介绍其单机模式和 Standalone Cluster 模式的部署。 二、单机模式 单机模式是一种开箱即用的模式,可以在单台服务器上运行,适用于