《数据人的面试交流地》专题
-
第 3 章 数据处理的流程控制
第 3 章 数据处理的流程控制 计算机程序是对特定数据进行特定操作的一系列编排好的处理步骤。第 2 章介绍了各种 类型的数据的表示和操作,本章介绍如何“编排”处理步骤的问题,即程序的流程控制。编 程语言①提供了控制流语句,用于控制程序从多条执行路径中选择一条路径执行下去。不同 语言支持的控制流语句在形式上可能各不相同,但其作用是相同的,大致可分为顺序、无条 件跳转、条件分支、循环、子程序等几类控制
-
Spring云数据流商业支持
我们正在将我们的工作和数据流从Spring XD迁移到Kubernetes上的Spring cloud数据流。 Spring cloud数据流有商业支持吗?任何链接都有帮助。
-
Spring云数据流与Kafka安全
是否可以为Apache Kafka的Spring Cloud DataFlow配置身份验证?在哪里可以看到示例? 谢谢你。
-
春云数据流输入源Kafka
我有一个常见的任务问题,我可以找到任何解决方案或帮助(也许我需要传递一些属性来工作?)我使用本地服务器1.3.0.M2并创建简单的流 在日志中,我得到了这个: 2017-09-28 12:31:00.644 信息 5156 --- [ -C-1] o.. a.k.c.c.internals.AbstractCoordinator : 成功加入第 1 代的组测试 2017-09-28 12:31:0
-
云数据流、PubSub和Bigquery问题
我想使用Cloud Dataflow,PubSub和Bigquery将tableRow写入PubSub消息,然后将它们写入Bigquery。我希望表名、项目id和数据集id是动态的。 我在internet上看到下面的代码,我不明白如何传递数据行参数。 先谢谢你,盖尔
-
Google云数据流工作线程
-
apache_beam.transforms.util.reshuffle()不适用于GCP数据流
我已经通过。但是,我注意到Reshuffle()没有出现在发行版中。这是否意味着我将不能在任何数据流管道中使用?有什么办法可以绕过这个吗?或者pip包可能只是不是最新的,如果Reshuffle()在github的master中,那么它将在Dataflow上可用? 根据对这个问题的回答,我试图从BigQuery中读取数据,然后在将数据写入GCP存储桶中的CSV中之前对数据进行随机化。我注意到,我用来
-
如何存储火花流数据
在spark streaming中,流数据将由在worker上运行的接收器接收。数据将被周期性地推入数据块中,接收者将向驱动程序发送receivedBlockInfo。我想知道这会引发流将块分发到集群吗?(换句话说,它会使用分发存储策略吗)。如果它不在集群中分发数据,如何保证工作负载平衡?(我们有一个10s节点的集群,但只有几个接收器)
-
JDBC流ASCII和二进制数据
主要内容:实例对象可以使用输入和输出流来提供参数数据。能够将整个文件放入可以容纳大值的数据库列,例如和数据类型。 有以下方法可用于流式传输数据 - :此方法用于提供大的ASCII值。 :此方法用于提供较大的UNICODE值。 :此方法用于提供较大的二进制值。 方法除了参数占位符之外还需要额外的参数和文件大小。此参数通知驱动程序使用流向数据库发送多少数据。 实例 考虑要将XML文件上传到数据库表中。下面是XML文
-
Google Cloud数据流、TextIO和Kerberize HDFS
我正在尝试使用Dataflow运行器上的BeamJava2.22.0从kerberize HDFS读取TSV文件。我正在使用带有kerberos组件的Dataproc集群来提供kerberize HDFS。我得到的错误是: 我正在按如下方式配置管道(注意,我已经配置了java.security.krb5.realm/kdc,我认为这使得在worker上不需要krb5.conf。我的hdfstext
-
使用Apache Flink进行数据流
我正在构建一个有以下要求的应用程序,我刚刚开始使用Flink。 null null 谢谢并感激你的帮助。
-
Apache Flink:创建滞后数据流
如果每个事件间隔为1秒,并且有2秒的滞后,那么我希望示例输入和输出如下所示。 输入:1,2,3,4,5,6,7... 输出:NA,NA,1,2,3,4,5...
-
JSON解码Base64数据流Apache Flink
需要一些建议,我已经使用scala创建了一个flink作业来消费来自Kafka的消息。但是消息是用base64编码压缩的。我已经试过这个代码了 代码由于它不是有效的Json格式而失败。 然后我尝试使用SimpleStringSchema(),就像下面的代码一样 Kafka的信息完美地消耗了,但是输出如下 如何将此数据解码为有效的JSON? 此致敬意
-
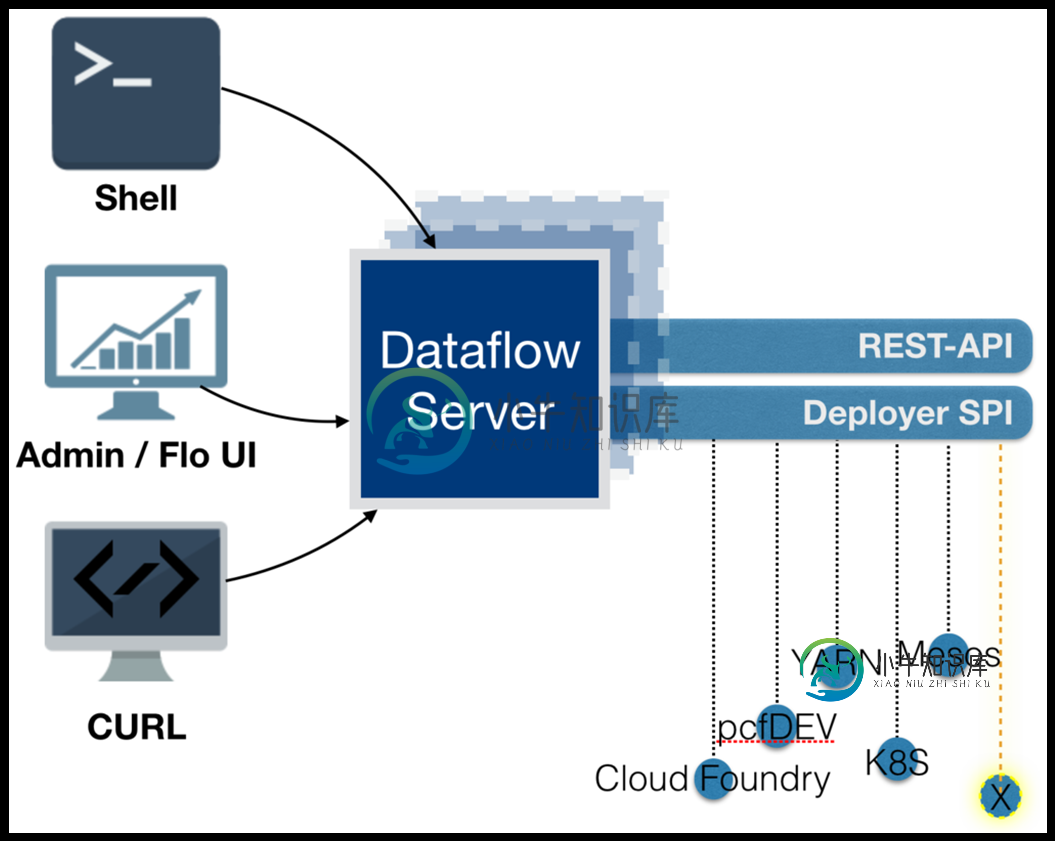 LoadBalancing Spring云数据流服务器
LoadBalancing Spring云数据流服务器在spring cloud dataflow中,根据我的理解,每个流都是一个微服务,但数据流服务器不是。我说的对吗?
-
Spring Webflux-向endpoint发送数据流
我有一个关于Spring WebFlux的问题。我想创建一个使用内容类型text/event-stream的反应endpoint。不是生产而是消费。我们的一个服务需要向另一个服务发送大量的小对象,我们认为这样流式传输可能是一个很好的解决方案。 流量是每1秒产生一个值的流。我遇到的问题是,WebClient完全读取发布服务器,然后将数据作为一个整体发送,而不是一个接一个地流式传输。我能用这个客户机或