《寒冬逼人,快寄了》专题
-
NotRxJava懒人专用指南
NotRxJava懒人专用指南 原文链接 : NotRxJava guide for lazy folks 原文作者 : Yaroslav Heriatovych 译文出自 : 开发技术前线 www.devtf.cn 译者 : Rocko 校对者: Mr.Simple 状态 : 完成校对 如果你是一位 Android 开发者,那么这些天你可能已经听到或看到一些关于 RxJava 满天飞的宣传了。R
-
Django用户个人资料
问题内容: 在将其他字段(例如位置,性别,雇主等)添加到用户个人资料时,是否应该在其中添加其他列并将其保存在其中?还是应该创建一个新表来保存用户个人资料信息? 另外,当用户上传个人资料图片时,是否应该将其保存在同一张表中?(请注意,这不是生产服务器,我只是在本地运行服务器上执行此操作以弄清楚问题)。谢谢 问题答案: 你必须为用户个人资料建立模型: 然后在中配置
-
定制@angular/服务人员
如何自定义@角/服务工作者?我知道在npm_modules文件夹内修改是不合适的。我遇到了一个教程,作者创建了一个额外的2 js文件。其中一个文件包含服务工作人员代码,而另一个文件包含导入ngsw-worker.js文件和自定义服务工作人员文件的“导入脚本()”。它工作正常,自定义服务辅助角色监听安装事件,但是当涉及到读取事件时,它不会通过这个读取事件监听器。我没有得到这个函数里面的控制台。我不知
-
工兵和服务工人
这更像是一个服务人员的问题,尽管它可能更具体地针对Sapper。我真的不知道,因为我是第一个和服务人员打交道的人,我几乎没有使用过他们,而且经常觉得他们是个麻烦。 基本上,无论我做什么,我都无法让localhost:3000停止加载应用程序的旧副本。我以各种方式取消了服务工作人员的注册,包括尝试以编程方式取消注册。我清除了缓存,甚至清除了浏览器中的所有浏览数据。我的Sapper开发环境中的服务器未
-
服务人员未激活
带有服务工作者的网站,托管https://121eddie.github.io/并在Chrome 66.0中运行。3359.181 /索引。html在每次加载时正确跟踪以下注册 }); 第一次运行时,/serviceWorker。js执行“激活”事件,正确获取缓存名称并缓存文件 在第二次运行时,不会触发“激活”(没有日志跟踪,没有获取)。 在第三次运行中,甚至不再触发“抓取”。这意味着脱机请求不被
-
2人掷骰子输入
-
码头工人ERR_NAME_NOT_RESOLVED http ajax
问题内容: 我有3个简单的微服务(mysql,apirest,gui),我开始使用docker-compose: 在 MySQL的 和 apirest 微服务没有问题可以进行通信(我可以连接到我的数据库 apirest 使用 的MySQL 作为主机名。 但是,当我尝试使用 apirest* 作为主机名执行http请求(角度)时,我在 gui 微服务中收到以下错误: * 无法加载资源:net ::
-
反应型Kafka制作人
我正在探索反应性Kafka,只是想确认反应性Kafka是否等同于同步制作人。与同步生产者,我们得到消息传递保证与确认字符和生产者序列保持。但是,ASYNC不能保证交付和测序。反应式生产者等同于SYNC还是ASYNC?
-
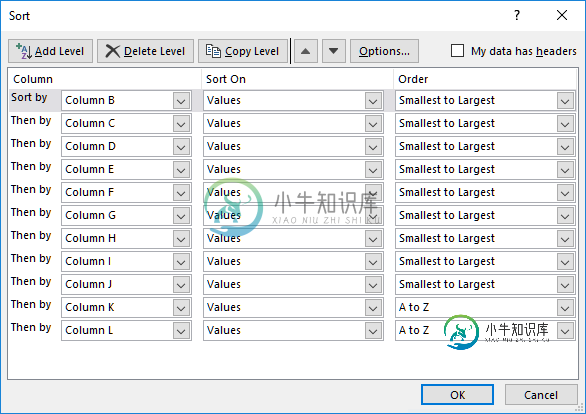 自然或人为排序
自然或人为排序问题内容: 我已经为此工作了几个月。我只是无法获得(真实的字母数字)结果。令我震惊的是我无法获得自1992年以来的成就。 我正在寻找SQL,VBS或简单的excel或access中的任何解决方案。这是我的数据: 我要查找的顺序是真实的字母数字顺序,如下所示: 库存为7800条记录,因此我在处理能力方面也遇到了一些问题。 任何帮助,将不胜感激。 杰夫 问题答案: 在本机Excel中,您可以添加多个排
-
圣诞老人分类帽
我正在做一个程序,它将模拟秘密圣诞老人的分类帽。我试图让程序有一个错误陷阱,以防止人们获得自己的名字,但我无法让程序在有人获得自己的名字时选择一个新的名字。我遇到的另一个问题是,程序一直过早退出。 这是我的代码:
-
TimeoutError:工人启动失败
我在jupyter笔记本电脑上的conda环境中工作。尝试使用以下过程创建客户端时 出现以下错误 回调(f)827尝试:-- 在结果(self,timeout)237中尝试:-- 提升exc信息(exc信息) 运行(自我)1068其他:- 在启动工人(自我,死亡超时,**kwargs)228个自我工人。移除(w)-- 在init(self、n_-worker、线程/worker、进程、循环、启动、
-
为私人方法编织
我有一个AspectJ编织注释,它适用于公共方法,但私有方法被忽略了。此方法的目的是简单地记录运行函数所用的时间。 这是实际的接口: 我已经看到了很多答案,在部分的第一个之前添加,我看到了注释不支持的,并且我使用的是没有SpringAOP的AeyJ。 有什么想法吗?
-
私人服务和Symfony 4
我正在尝试将我的Symfony 3.4应用程序迁移到Symfony 4.1。 测试不起作用,因为服务默认是私有的(这是一个好消息)。 以下这篇文章:https://symfony.com/blog/new-in-symfony-4-1-simpler-service-testing,我仍然面临私人服务的问题: Symfony\Component\DependencyInjection\Except
-
Python中的人脸识别
我能够找到这些面孔,并使用python将它们保存在本地目录中,然后根据下面视频中的代码打开cv 但是现在我想知道那个视频里有脸的人的身份...... 我如何定义此人的身份? 喜欢扫描人脸并将其匹配到本地人脸数据库中,如果找到匹配项,请给出姓名等
-
Flinkkafka消费者/制作人
大家好,我正在努力将一个简单的avro模式与模式注册表一起序列化。 设置: 两个用java编写的Flink jobs(一个消费者,一个生产者) 目标:生产者应该发送一条用ConfluentRegistryAvroSerializationSchema序列化的消息,其中包括更新和验证模式。 然后,使用者应将消息反序列化为具有接收到的模式的对象。使用。 到目前为止还不错:如果我将架构注册表上的主题配置