《算法》专题
-
python实现随机漫步算法
本文向大家介绍python实现随机漫步算法,包括了python实现随机漫步算法的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了python实现随机漫步的具体代码,供大家参考,具体内容如下 编写randomwalk类 choice([1,-1])*步数巧妙的完成了随机方向,x轴随机加y轴随机使得4个方向的随机漫步得以完成 显示随机漫步点 以上就是本文的全部内容,希望对大家的学习有所帮助
-
java微信红包实现算法
本文向大家介绍java微信红包实现算法,包括了java微信红包实现算法的使用技巧和注意事项,需要的朋友参考一下 随着目前微信越来越火,所以研究微信的人也就越来越多,这不前一段时间,我们公司就让我做一个微信公众号中问卷调查发红包功能,经过一段时间的研究,把功能完成,里面主要的实现步骤都是按照微信公众号开发文档来的,很详细,在整个过程唯有红包算法需要仔细编写,因为毕竟涉及到钱,所以得小心,而且不仅微信
-
python实现数独算法实例
本文向大家介绍python实现数独算法实例,包括了python实现数独算法实例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了python实现数独算法的方法。分享给大家供大家参考。具体如下: 希望本文所述对大家的Python程序设计有所帮助。
-
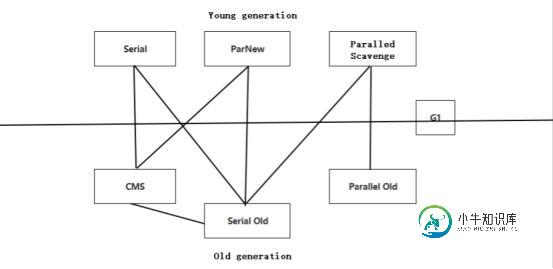 java中gc算法实例用法
java中gc算法实例用法本文向大家介绍java中gc算法实例用法,包括了java中gc算法实例用法的使用技巧和注意事项,需要的朋友参考一下 在我们对gc中的算法有基本概念理解后,要把算法的理念实现还需要依托实际垃圾收集器的使用。因为光靠一些简单的原理不足以支撑整个程序的运行,在回收机制上有专门的收集器。下面我们就垃圾收集器的概念、使用注意事项、收集器图解进行介绍,然后带来两种常见的垃圾收集器供大家参考。 1.概念 垃圾收
-
PHP面试常用算法(推荐)
本文向大家介绍PHP面试常用算法(推荐),包括了PHP面试常用算法(推荐)的使用技巧和注意事项,需要的朋友参考一下 一、冒泡排序 基本思想: 对需要排序的数组从后往前(逆序)进行多遍的扫描,当发现相邻的两个数值的次序与排序要求的规则不一致时,就将这两个数值进行交换。这样比较小(大)的数值就将逐渐从后面向前面移动。 //冒泡排序 二、快速排序 基本思想: 在数组中挑出一个元素(多为第一个)作为标尺,
-
PHP二维数组去重算法
本文向大家介绍PHP二维数组去重算法,包括了PHP二维数组去重算法的使用技巧和注意事项,需要的朋友参考一下 需求 现在有下面一组二维数组: 需要将处于第二维键名为name,其值相同的数组的value合并,形成一个新的数组。 比如上面代码中的name为fileds_510的两个二维数组,就应该合并为一个值为足球,棒球的数组。 思路 提到数组,再PHP中我们首先想到了循环,那么这里显然比较适合使用fo
-
C#排序算法之堆排序
本文向大家介绍C#排序算法之堆排序,包括了C#排序算法之堆排序的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了C#实现堆排序的具体代码,供大家参考,具体内容如下 代码: 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
Javascript冒泡排序算法详解
本文向大家介绍Javascript冒泡排序算法详解,包括了Javascript冒泡排序算法详解的使用技巧和注意事项,需要的朋友参考一下 比较相邻的元素。如果第一个比第二个大,就交换他们两个。 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。 针对所有的元素重复以上的步骤,除了最后一个。 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需
-
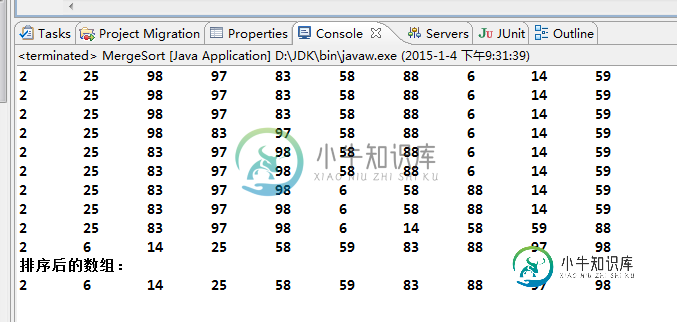 浅析java 归并排序算法
浅析java 归并排序算法本文向大家介绍浅析java 归并排序算法,包括了浅析java 归并排序算法的使用技巧和注意事项,需要的朋友参考一下 归并排序(Merge)是将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列分为若干个子序列,每个子序列是有序的。然后再把有序子序列合并为整体有序序列。 归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型
-
 PHP 快速排序算法详解
PHP 快速排序算法详解本文向大家介绍PHP 快速排序算法详解,包括了PHP 快速排序算法详解的使用技巧和注意事项,需要的朋友参考一下 概念 这里借用百度百科的一张图来,非常形象: 快速排序算法是对冒泡算法的一个优化。他的思想是先对数组进行分割, 把大的元素数值放到一个临时数组里,把小的元素数值放到另一个临时数组里(这个分割的点可以是数组中的任意一个元素值,一般用第一个元素,即$array[0]),然后继续把这两个临时数
-
ASP.NET加密解密算法分享
本文向大家介绍ASP.NET加密解密算法分享,包括了ASP.NET加密解密算法分享的使用技巧和注意事项,需要的朋友参考一下 以上所述就是本文的全部内容了,希望大家能够喜欢。
-
C语言实现K-Means算法
本文向大家介绍C语言实现K-Means算法,包括了C语言实现K-Means算法的使用技巧和注意事项,需要的朋友参考一下 一、聚类和聚类算法 聚类,就是将数据对象划分成若干个类,在同一个类中的对象具有较高的相似度,而不同的类相似度较小。聚类算法将数据集合进行划分,分成彼此相互联系的若干类,以此实现对数据的深入分析和数据价值挖掘的初步处理阶段。例如在现代商业领域,聚类分析算法可以从庞大的数据集合中对消
-
python实现ID3决策树算法
本文向大家介绍python实现ID3决策树算法,包括了python实现ID3决策树算法的使用技巧和注意事项,需要的朋友参考一下 决策树之ID3算法及其Python实现,具体内容如下 主要内容 决策树背景知识 决策树一般构建过程 ID3算法分裂属性的选择 ID3算法流程及其优缺点分析 ID3算法Python代码实现 1. 决策树背景知识 决策树是数据挖掘中最重要且最常用的方法之一,主要应用于数据
-
 python实现红包裂变算法
python实现红包裂变算法本文向大家介绍python实现红包裂变算法,包括了python实现红包裂变算法的使用技巧和注意事项,需要的朋友参考一下 本文实例介绍了python实现红包裂变算法,分享给大家供大家参考,具体内容如下 Python语言库函数 安装:pip install redpackets 使用: 1、前情提要 过年期间支付宝红包、微信红包成了全民焦点,虽然大多数的红包就一块八角的样子,还是搞得大家乐此不疲。作为
-
 javascript常用经典算法详解
javascript常用经典算法详解本文向大家介绍javascript常用经典算法详解,包括了javascript常用经典算法详解的使用技巧和注意事项,需要的朋友参考一下 阅读目录 冒泡排序 插入排序 希尔排序 归并排序 快速排序 选择排序 奇偶排序 总结 前言:在前端大全中看到这句话,以此共勉。基础决定你可能达到的高度, 而业务决定了你的最低瓶颈 其实javascript算法在平时的编码中用处不大,不过不妨碍我们学习它,学习一下这