《算法》专题
-
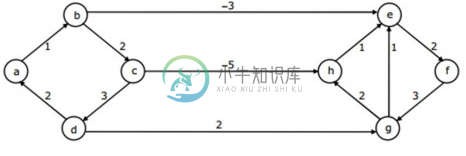 Dijkstra算法=SSSP
Dijkstra算法=SSSP据我所知,dijkstra无法处理负边权重。为此,我们必须使用贝尔曼福特。 Bellman fords在负边权重和负循环下运行良好,这是无法从源位置访问到的,否则,它将返回消息“负循环存在”。 但是,上面显示的图表与dijkstra运行良好,即使存在负边权重。那么,如何知道何时使用具有负边权重的dijkstra?? 我们想的是,dijkstra可以或不能使用负权重边。如果存在负循环,那么它将不起作
-
算法练习
我正在做这个算法练习,但我不完全理解公式。下面是练习: 给定一个string str和一对数组(该数组指示字符串中的哪些索引可以交换),返回通过执行允许的交换而产生的词典中最大的字符串。您可以交换任何次数的索引。 示例 对于str=“abdc”和pairs=[[1,4],[3,4]],输出应该是swapLexOrder(str,pairs)=“dbca”。 通过交换给定的索引,可以得到字符串:“c
-
找峰算法
给定一个数组[a,b,c,d,e,f,G],其中a-g是数,b是峰当且仅当a<=b且b>=c。 他给出了一个递归的方法: 他说算法是T(n)=T(n/2)+o(1)=o(lgn) 在他的pdf中,他还给出了一个完整的例子: 他的定义是否意味着我们只需要找到一个峰? 我相信这个问题可以看作是在Riverst算法入门书中寻找最大和最小元素。
-
分治算法
几周前我有一个工作面试,我被要求设计一个分而治之的算法。我无法解决这个问题,但他们只是打电话给我进行第二次面试!问题是: 我们给出了两个n元素数组A[0..n-1]和B[0..n-1](它们不一定是排序的),以及一个整数值作为输入。给出了一个O(nlogn)分治算法,该算法确定是否存在不同的值i,j(即i!=j),使得A[i]+B[j]=value。如果i,j存在,算法应返回True,否则返回Fa
-
 算法面经
算法面经个人简介:双广州某985(2015-2022)、计算机硕士(保研)、CV方向、论文在投、YY算法岗3个月实习、国家级竞赛一二等奖(Robot CV相关)、研究生实验室个人项目、硕本GPA分别为3.61和3.37 秋招经历: ① 美团:到店平台技术部>ML/DM>二面后泡很久然后挂 ② 快手:机器学习算法岗>三面后泡很久然后挂 ③ 字节:抖音推荐算法岗>二面后挂(面试官迟到45min左右, 只面了1
-
 算法笔试
算法笔试好像是25道单选题+3道编程题 原题没有复制下来,俺只记得大致意思,大家将就着看吧 第一题: 1、有俩哥们小A和小B玩游戏,每个游戏会有奖品(用数字和字母表示),相同的奖品(拿的顺序也必须相同)才能带回家,最多能带回多少件奖品 输入 3478297 3djakl7 输出 4 第二题: 信封嵌套问题,有n个信封,每个信封有长和宽,只有长宽比另一个信封的小,才能放进去,问最多能嵌套多少个信封 输入 4
-
 8.20算法岗
8.20算法岗#做完网易2023秋招笔试题,我裂开了# #网易笔试# 求讨论思路! 第一题:求最小交换次数,让排列是非递减(思路:答案就是逆序对的数量) 第二题:求只含r e d字符的字符串中,所含三个元素数量相等的子串数量 第三题:求n个数中k个数的按位与结果最大 第四题:第一项a,第二项b, 之后每一项都是前两项乘积的平方
-
 旷视算法
旷视算法cpp map unordered map区别,进程线程区别,快排复杂度分析,写一个vector,n个人俩人生日相同概率。 问的cpp基础,手写的时候顺手来了一个def,。。。,最后问了问,是深度学习强化学习相关。。。
-
共识算法
共识算法 实际上,要保障系统满足不同程度的一致性,往往需要通过共识算法来达成。 共识算法解决的是对某个提案(Proposal),大家达成一致意见的过程。提案的含义在分布式系统中十分宽泛,如多个事件发生的顺序、某个键对应的值、谁是领导……等等,可以认为任何需要达成一致的信息都是一个提案。 注:实践中,一致性的结果往往还需要客户端的特殊支持,典型地通过访问足够多个服务节点来验证确保获取共识后结果。 问
-
遗传算法
在程序里生宝宝, 杀死不乖的宝宝, 让乖宝宝继续生宝宝 所有的遗传算法 (Genetic Algorithm), 后面都简称 GA, 我们都需要一个评估好坏的方程, 这个方程通常被称为 fitness 在 GA 中有基因, 为了方便, 我们直接就称为DNA吧. GA 中第二重要的就是这DNA了, 如何编码和解码DNA, 就是你使用 GA 首先要想到的问题. 传统的 GA 中,DNA我们能用一串二进
-
推荐算法
推荐算法是非常古老的,在机器学习还没有兴起的时候就有需求和应用了。概括来说,可以分为以下5种: 1)基于内容的推荐:这一类一般依赖于自然语言处理NLP的一些知识,通过挖掘文本的TF-IDF特征向量,来得到用户的偏好,进而做推荐。这类推荐算法可以找到用户独特的小众喜好,而且还有较好的解释性。这一类由于需要NLP的基础,本文就不多讲,在后面专门讲NLP的时候再讨论。 2)协调过滤推荐:本文后面要专门讲
-
签名算法
签名算法描述如下: 1.将请求参数按参数名升序排序; 2.按请求参数名及参数值相互连接组成一个字符串:...; 3.将应用密钥分别添加到以上请求参数串的头部和尾部:<请求参数字符串>; 4.对该字符串进行MD5(全部大写),MD5后的字符串即是这些请求参数对应的签名; 5.该签名值使用sign参数一起和其它请求参数一起发送给服务开放平台。 参数示例 { "name": "file.uplo
-
检索算法
二分搜索 在计算机科学中,二分搜索(binary search),也称折半搜索(half-interval search)、对数搜索(logarithmic search),是一种在有序数组中查找某一特定元素的搜索算法。 搜索过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜索过程结束;如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间
-
排序算法
冒泡排序 相邻的两个元素依次比较,小的放在左边。 选择排序 从未排序序列中找到最大(小)值存放到已排序序列末尾。 插入排序 从已排序序列中找到小于或等于当前数的位置并插到其后。 希尔排序 归并排序 归并排序(merge sort)是创建在归并操作上的一种有效的排序算法。归并操作(merge),也叫归并算法,指的是将两个已经排序的序列合并成一个序列的操作。归并排序算法依赖归并操作。 递归方式 此方式
-
加密算法
MD5 加密算法 类型:MD5 可配置属性:无 AES 加密算法 类型:AES 可配置属性: 名称 数据类型 说明 aes-key-value String AES 使用的 KEY RC4 加密算法 类型:RC4 可配置属性: 名称 数据类型 说明 rc4-key-value String RC4 使用的 KEY