《万得》专题
-
js实现的万能flv网页播放器代码
本文向大家介绍js实现的万能flv网页播放器代码,包括了js实现的万能flv网页播放器代码的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了js实现的万能flv网页播放器代码。分享给大家供大家参考,具体如下: 附: swfobject.js的官方地址:http://blog.deconcept.com/swfobject/ 更多关于JavaScript相关内容可查看本站专题:《JavaScr
-
处理长度为3000万个字符的字符串
问题内容: 我正在从另一台服务器下载CSV文件,作为供应商的数据提要。 我正在使用curl获取文件的内容,并将其保存到名为的变量中。 我可以很好地达到那部分,但是我尝试通过爆炸并获得行数组,但是失败并出现“内存不足”错误。 我,大约是3050万个字符。 我需要处理这些值并将它们插入数据库。为了避免内存分配错误,我该怎么办? 问题答案: PHP令人窒息,因为它耗尽了内存。不要使用curl来用文件的内
-
Python aiohttp百万并发极限测试实例分析
本文向大家介绍Python aiohttp百万并发极限测试实例分析,包括了Python aiohttp百万并发极限测试实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python aiohttp百万并发极限测试。分享给大家供大家参考,具体如下: 本文将测试python aiohttp的极限,同时测试其性能表现,以分钟发起请求数作为指标。大家都知道,当应用到网络操作时,异步的代码表现
-
websocket与header connection-keep-alive=百万的http有何不同
-
一千万条数据的表, 如何分页查询?
本文向大家介绍一千万条数据的表, 如何分页查询?相关面试题,主要包含被问及一千万条数据的表, 如何分页查询?时的应答技巧和注意事项,需要的朋友参考一下 数据量过大的情况下, limit offset分页会由于扫描数据太多而越往后查询越慢. 可以配合当前页最后一条ID进行查询, SELECT * FROM T WHERE id > #{ID} LIMIT #{LIMIT}. 当然, 这种情况下ID必
-
 Python实现PS滤镜的万花筒效果示例
Python实现PS滤镜的万花筒效果示例本文向大家介绍Python实现PS滤镜的万花筒效果示例,包括了Python实现PS滤镜的万花筒效果示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python实现PS滤镜的万花筒效果。分享给大家供大家参考,具体如下: 这里用 Python 实现 PS 的一种滤镜效果,称为万花筒。也是对图像做各种扭曲变换,最后图像呈现的效果就像从万花筒中看到的一样: 图像的效果可以参考附录说明。具体Py
-
无法将RDD转换为DataFrame(RDD有数百万行)
我使用的是Apache Spark 1.6.2 我有一个。csv数据,它包含大约800万行,我想把它转换成DataFrame 映射RDD可以很好地工作,但是当涉及到将RDD转换为DataFrame时,Spark引发了一个错误 以下是我的代码: 有超过800万行,但是当我将这些行减到只有<500行时,程序就可以正常工作了 数据很乱,每行中的总列经常不同,这就是为什么我需要首先映射它。但是,我想要的数
-
如何在HBase中扫描和删除数百万行
发生的事情 由于系统中的错误,上个月的所有数据都已损坏。所以我们不得不手动删除并重新输入这些记录。基本上,我想删除在某段时间内插入的所有行。但是,我发现很难在HBase中扫描和删除数百万行。 可能的解决方案 我找到了两种批量删除的方法: 第一种是设置一个TTL,这样所有过期的记录都会被系统自动删除。但是我想保留上个月之前插入的记录,所以这个解决方案对我不起作用。 第二种选择是使用Java API编
-
在Oracle中更快地插入SQL百万行[重复]
我有一个查询,它从另一个表中填充表数据。现在它看起来像这样。 在10 000条记录上,它执行大约10秒。但是会有10,000,000条记录的情况,恐怕它会很慢。我能做得更快吗?
-
MongoDB对超过500万条记录的查询性能
我已经确保使用explain查询确实使用了我创建的索引,但性能仍然不够好。 我在想,现在是不是该去sharding了..但是我们很快就会开始每天有大约100万张新唱片在这个收藏中…所以我不确定它是否能很好地扩展.. 编辑:查询示例: 请注意,deviceType在我的集合中只有2个值。
-
 北京万维盈创产品助理初面面经
北京万维盈创产品助理初面面经1.刚过完年那几天在智联上投递了他们的岗位之后大概三四天有HR给我打电话了解基本信息,大概会问一些关于自己未来规划和对于岗位看法的问题,然后就约了初试 2.初试是一个HR姐姐面试的,没有业务部门的人,了解了一些在校期间的履历,问了一些对产品岗位的理解和对行业的看法,让我介绍了一下过往做的一些项目,问了一下对未来职业的规划什么的。 说是2-3工作日会回复我面试结果,目前还在等消息,是一家做环保的公司
-
重磅:近 1GB 的三千万聊天语料供出
注意:本文提到的程序和脚本都分享在https://github.com/lcdevelop/ChatBotCourse。如需直接获取最终语料库,请见文章末尾。 第一步:爬取影视剧字幕 请见我的这篇文章《二十八-脑洞大开:基于美剧字幕的聊天语料库建设方案》 第二步:压缩格式分类 下载的字幕有zip格式和rar格式,因为数量比较多,需要做筛选分类,以便后面的处理,这步看似简单实则不易,因为要解决:文件
-
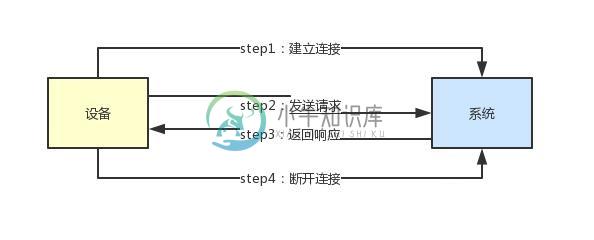 什么样的架构才能支持百万连接?
什么样的架构才能支持百万连接?主要内容:1、到底什么是连接?,2、为什么每次发送请求都要建立连接?,3、长连接模式下需要耗费大量线程资源,4、Kafka遇到的问题:应对大量客户端连接,5、Kafka的架构实践:Reactor多路复用,6、优化后的架构是如何支撑大量连接的?这篇文章,给大家聊聊:如果你设计一个系统需要支撑百万用户连接,应该如何来设计其高并发请求处理架构? 1、到底什么是连接? 假如说现在你有一个系统,他需要连接很多很多的硬件设备,这些硬件设备都要跟你的系统来通信。 那么,怎么跟你的系统通信呢? 首先,他一定会跟
-
 长沙 万兴科技 Android开发工程师笔试
长沙 万兴科技 Android开发工程师笔试一个小时,整体来说题量不大,共15道题目,只有一道编程题。难度适中 一、选择题(10道*5分) 计算机网络TCP传输协议、JAVA基础知识、Android编程相关 二、问答题 ThreadLocal介绍和应用 哈夫曼编码介绍和应用 时间、空间复杂度介绍 三、编程题 最长上升子序列(LIS) 不知道为啥过了三个显性测试,但是隐藏测试案例10个只过了6个#秋招##万兴科技##安卓工程师##牛客创作赏金
-
Java读取200万行文本文件的最快方法
问题内容: 目前,我正在使用扫描仪/文件阅读器,同时使用hasnextline。我认为这种方法效率不高。还有其他方法可以读取与此功能类似的文件吗? 问题答案: 您会发现这是所需的速度:您可以每秒读取数百万行。字符串拆分和处理很可能导致遇到的任何性能问题。