《字节跳动春招》专题
-
URLConnection低级字节计数
我正在尝试使用URLConnection获得可能的最低级别的字节计数。我已经使用来自Apache Commons IO的CountinInputStream和CountinOutputStream来计数通过两个流的数据,但我在那里得到的字节计数等于我发送的主体大小我收到的响应主体大小。 在HttpClient中,我有一个MeasurengClientConnManager,我认为它是一个较低级别的
-
字节数组到整数
如何在java中将字节数组转换为int。我正在构建蓝牙应用程序,我在其上收到字节数组中的消息,然后将其转换为字符串,它已成功转换,但我也希望它以整数形式存在
-
CRC-UINT64到两个字节?
我只知道几件事:(1),我正在为其编写适配器的硬件需要两个字节的CRC值。(2),CRC包的作者说明uint64可以显示为0xFFFF,即两个字节。(3)在线CRC计算器将这些值显示为两个字节,例如https://www.lammertbies.nl/comm/info/crc-calculation.html。其余的对我来说都是新的... 我刚刚发布了CRC包自述文件中的一个片段。由于uint6
-
Vaadin流:字节[]到图像
我尝试显示一个图像,作为blob存储在表中。 因此,我需要将byte[]转换为Vaadin图像类(我想这是显示它的最佳方式?)。 我尝试此解决方案(4岁): https://vaadin.com/forum/thread/10271496/byte-array-to-vaadin-image 它不起作用: 在瓦丁13我怎么做?
-
BufferedReader读取的字节数
据我所知,缓冲阅读器比非缓冲阅读器优化了很多,因为每次读取都将从内存中完成,不需要每次都从磁盘/网络进行I/O读/写。 所以我在这里阅读答案: 缓冲读取器和文件读取器之间的特定区别 我被第二个答案弄糊涂了,这个答案似乎有很高的票数: 当向BufferedReader对象发出“read”指令时,它会使用FileReader对象从文件中读取数据。当给出指令时,FileReader对象一次读取2(或4)
-
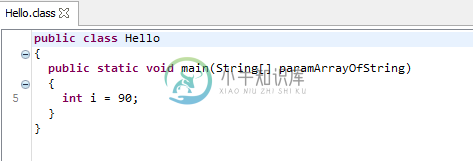 字节值转换为int
字节值转换为int我知道,如果我们对字节值执行算术运算,那么隐式地将其提升为int值,结果将是int值,因此我们需要显式地将其转换为byte,以便将结果存储在byte变量中。但我想问- 从字节到int的转换是在声明它的时候发生的,还是在我们在算术运算中使用它的时候发生的?因为我使用的java反编译器在声明时将它从字节转换为int。所以,这是反编译器的问题还是真的是这样。 如果它真的发生在声明时,那么为什么存储超出字
-
 字节测开一面 8.10
字节测开一面 8.101.自我介绍 2.介绍一下java(面向对象、三大特性:继承封装、多态) 2. == 和equals区别 3.接口和抽象类区别 4.array 和 arraylist区别 5.反射机制 6.OSI七层模型(介绍每一层及协议) TCP三次握手和四次挥手 7.TCP和UDP区别 8.mysq都有哪些索引? 索引的优缺点 ,索引的底层结构 9.算法:删除链表的倒数第N个结点 10.测试用例:发朋友圈 (
-
 UX设计面经-字节
UX设计面经-字节1、自我介绍 2、提问环节(主要针对自我介绍提问) Q1:你参加的机器人大赛是什么性质的?整个team多少人呢?你的工作内容是针对单独的组还是整个team?运营的公众号和微博叫什么,一会儿去关注一下;一等奖是什么时候获得的? Q2:你认为你GPA差的那0.4是差在哪儿去了呢? Q3:你觉得你最不擅长的课程是? Q4:如果遇到2B端的工具你找不到竞品该怎么办? Q5:在不同公司不同岗位的实习差别都很
-
 字节三面(已意向)
字节三面(已意向)8.2 三面 自我介绍; 问实习,问了一些业务指标的开放性问题; ctr模型的发展演进; 做题:有序链表排重 30分钟就结束了 总体来说不难~三轮面试的面试官都很好,技术很强但为人谦和的那种,让人感到如沐春风。也可能是我见过百度的 pua面试官之后看谁都眉清目秀的😂 8.4 收到调查问卷链接之后hr告知通过,马上就发了意向~效率好高 前几天还说大概率离开互联网了,但现在看来可能推荐这块也没我想的
-
 字节 cpp 二面面经
字节 cpp 二面面经今天面试感觉不像技术面,技术内容太少了。 1.自我介绍 2.代码题,模板用迭代器写快排。 3.你觉得这个快排有什么可以优化的地方吗? 我答随机数找 pivot,他问 random 函数是怎么实现的?不会。。。 4.你有看过 STL 源码吗? 答:看的不多,看了点 sort 那你介绍一下吧。 答:巴拉巴拉 为什么在数量少于 16 的时候要用插入排序呢? 5.你有个 Django 的项目,能简单介绍一
-
 4.24字节前端一面
4.24字节前端一面面了一堆八股,感觉面试官就是读题机器……语气也没啥感情 css八股题若干,webpack八股题若干,最后事件循环看代码题+找第k大的数算法 反问环节: 我:咱们这个部门是做啥的 面试官:自己去问HR ------------------------------------- 整个下来感觉就是不太好,刚开始面试官念题的时候就觉的是KPI了,原来字节就这样啊
-
 4.13字节后端一面
4.13字节后端一面全程一个小时多一点 自我介绍 说一下这个web-moba这个项目 你这个项目的游戏引擎是怎么设计的 thrift是干嘛的 LRU算法的原理,实现过程 你在项目里面要解决多线程的并发问题,怎么解决的?(上互斥锁) 锁有哪些 读写锁应用场景,它的底层实现是什么? 基础 指针和引用的区别 智能指针的用法 输入网址到展示的全过程 线程和进程的区别 多线程和多进程的应用场景 进程之间的通信方式 你最喜欢哪种
-
字节级别的操作
除了基本的读写操作, ByteBuf 还提供了它所包含的数据的修改方法。 随机访问索引 ByteBuf 使用zero-based 的 indexing(从0开始的索引),第一个字节的索引是 0,最后一个字节的索引是 ByteBuf 的 capacity - 1,下面代码是遍历 ByteBuf 的所有字节: Listing 5.6 Access data ByteBuf buffer = ...;
-
栈虚拟机字节码
虽然AST可以直接解释执行,实现也不复杂,但大部分语言,比如java,python,ruby(1.9版本之后)使用虚拟机解释字节码执行。字节码和AST的执行有很强的一致性,但字节码执行机制可以实现一些更细粒度的控制 这里的虚拟机是指执行一种低级语言字节码的虚拟机,这个限定可能强了些,比方说,前面说的一个AST解释器,也可以看做是一种虚拟机,因为理论上是可以有一个机器解释AST执行,但这里我们说的虚
-
字节码解释执行
字节码的解释执行和AST的解释执行有类似之处,而且更简单,因为树形结构已经展开成顺序了,以栈虚拟机为例,为方便起见,假设所有的指令都在一个指令数组里,每个元素是一个指令对象,有code和arg两个属性,解释器入口: Object execute(Inst[] inst_list, Object[] func_arg); 由于continue和break已经被jmp指令代替了,这里我们认为exec