《兴盛优选》专题
-
测量时间不能确认LinkedList优势
我正在阅读和之间的区别,在何时使用LinkedList而不是ArrayList?中指出了这一点。我开发了一个小示例applcation来测试的一个主要优点,但我获得的结果并没有证实在操作性能方面超过了: 我注意到元素的增加显著降低了的性能,而则表现得更好。我明白了什么假的吗?
-
Java最小堆优先级队列实现
我目前正在尝试实现min heap PQ,但是我在实现的正确性方面遇到了一些问题,我似乎无法找出我做错了什么——它没有输出最低优先级,也没有对它们进行正确排序。 使用以下测试数据: 我得到以下结果: 我希望结果是按升序排列的——起初我认为这可能是因为交换了错误的孩子,但最后一个输出是最大的优先级,所以这没有意义。我花了几个小时试图研究堆优先级队列,但我找不到任何帮助。 以下是CMP要求的更好的代码
-
WebSphere中的JMS队列优先级问题
要求:我需要我的消息驱动bean(MDB)能够从四个不同的JMS队列中读取消息,MDB应该根据队列的优先级读取消息。 我有4个JMS队列A、B、C和D,优先级分别为8(最高)、7、6和5。因此,如果队列C中有500条消息,而队列A和B是空的。我的MDB应该使用来自队列C的消息。但是当我在高优先级队列(A或B)中收到消息时,我的MDB应该停止从C读取消息,并从高优先级队列中消耗消息(直到队列是空的)
-
全局常数优化和品种介位
我在用gcc和clang做实验,看看它们是否可以优化 以返回中间常量。 事实证明,他们可以: 但是令人惊讶的是,移除静态输出会产生相同的汇编输出。这让我很好奇,因为如果全局变量不是< code>static,它应该是可插值的,用中间变量替换引用应该可以防止全局变量的插值。 的确如此: 产出 编译器可以用中间变量替换外部全局变量的引用吗?这些不也应该被干预吗? 编辑: Gcc 不会优化外部函数调用(
-
用Spark优化配置单元SQL查询?
我对这些技术的理解是否正确?
-
如何计算对象的最优分组?
我需要能够将一组已知大小的对象分配到3组。例如,给定一个像下面这样的有序列表,我想要找到两个除法或分离点,使三个组具有相似的和。 每组的总和必须大致相等,组2和组3的总和不能超过第一组的总和超过一个规定的量(例如10)。理想情况下,第一组比其他组稍大一些。无法更改项目的顺序。每个组由原始列表的连续元素组成。每个元素都放在一个组中。 在这种情况下,预期的解决办法是: 用例是预先计算(服务器端)按优先
-
VS:_BitScanReverse64内部的意外优化行为
以下代码在调试模式下工作良好,因为_BitScanReverse64被定义为如果未设置位则返回0。引用MSDN:(返回值为)“如果已设置索引,则为非零;如果未找到设置位,则为0。” 如果在发布模式下编译此代码,它仍然可以工作,但是如果启用编译器优化,例如\o1或\o2,则索引不为零,将失败。 这是故意的行为吗?我正在使用Visual Studio Community 2015,版本14.0.254
-
如何在python中对此进行优化?
我想找到配对的数量,一个很大的数字。如果我给数字n,并要求确定配对的数量,这样 <代码>S(x) 而constants是
-
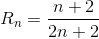 PHP解释器代码中的微优化
PHP解释器代码中的微优化由于在这个so线程上遇到了困难,我决定用PHP编写类似的测试。我的测试代码是这样的: 在PHP版本中运行与非常相似, 因此PHP解释器没有像Java中的JVM那样优化字节码 即使在我手动优化代码的时候--我也有~的加速比,而Java的版本有~的加速比。所以PHP版本的加速系数是Java代码的1/2。 我不想多说细节,但优化和未优化代码的乘法比是-> 1求和:3/4 2求和:4/6 3求和:5/8
-
Yen优化Bellman-Ford算法的正确性
我试图解决算法简介中的问题24-1,它指的是Yen对Bellman Ford algirithm的优化,我在wiki中找到了介绍,改进: Yen的第二个改进首先在所有顶点上分配一些任意的线性顺序,然后将所有边的集合划分为两个子集。第一个子集Ef包含所有边(vi, vj),使得i 不幸的是,我不能证明至少两个边松弛距离的方法如何匹配正确的最短路径距离:一个来自Ef,一个来自Eb。
-
 如何优化火花sql并行运行
如何优化火花sql并行运行我是spark新手,有一个简单的spark应用程序,使用spark SQL/hiveContext: 从hive表中选择数据(10亿行) 做一些过滤,聚合,包括row_number窗口函数来选择第一行,分组,计数()和最大()等。 将结果写入HBase(数亿行) 我提交的作业运行它在纱线集群(100个执行者),它很慢,当我在火花UI中查看DAG可视化时,似乎只有蜂巢表扫描任务并行运行,其余的步骤#
-
从优先级队列中删除元素
我正在尝试在滑动窗口中打印最大值。将窗口大小的元素,这里k=3放入优先级队列(Maxheap),然后查看值。”heap.Init(
-
队列sqaure根运行时的优先级
我正在进行数据结构考试,我正在准备一系列复习题。我的问题如下: “假设你的朋友来找你,声称他发明了一个超快速的基于优先级的比较队列。优先级队列的速度如下(n 是当前在优先级队列中的项目数):a. 在 O(sqrt(logn))时间插入新项目 b. 在 O(sqrt(logn)) 时间从队列中提取(删除并返回)最小项目。 解释为什么你的朋友一定在撒谎: 据我所知,标准优先级队列的运行时间是用于提取的
-
优酷数据 API 不断请求授权
我正在尝试制作一个简单的python程序,它使用Youtube数据API来检索基于Youtube搜索查询的结果。 我已经创建了我的OAuth凭证,并拥有一个client_secrets JSON。每次我运行我的python程序时,它总是要求我获得一个授权密钥,这样我就可以进行查询。我必须打开chrome,找到API给我的URL,登录我的谷歌账户,粘贴密钥。 有人能证明我如何使这个过程自动化吗?我在
-
优化。NET POCOs的JSON序列化性能
我一直试图优化要导入到MongoDB中的超过500k个POCO的JSON序列化,但除了头痛之外什么也没有遇到。我最初尝试了Newtonsoft json.convert()函数,但这花费了太长时间。然后,根据SO、NewtonSoft自己的站点和其他位置上的几篇文章的建议,我尝试手动序列化这些对象。但没有注意到太多,如果有任何业绩增益。 这是我用来启动序列化过程的代码...在每行上面的注释中,是给