《无专业限制》专题
-
太多的重放。react限制呈现次数以防止无限循环。使用效果
有人能帮帮我吗?
-
太多的重放。React限制呈现次数以防止无限循环。本地反应
当GetCreatorLicense()被禁用时,programe运行良好,我试图在循环之外设置数据,但仍然得到‘错误:太多的重新呈现’。React限制呈现的次数,以防止无限循环。错误,然后我把这个函数放在useEffect下,我只得到控制台输出,但useState没有改变
-
在OPENQUERY无法使用EXECUTE时绕过字符限制
问题内容: 我目前正在使用SQL Server Management Studio 17连接到Oracle数据库实例,然后提取一些数据并将其插入到我拥有的SQL Server表中。 我尝试执行以下操作: 但是,SQL代码大约为9500个字符,因此失败,这在MSDN文章中得到了支持。 我引用了这些网站: -MSDN一 -MSDN二 并了解到我可以用来实现自己的目标。我尝试实现以下内容: 但是,我仍然
-
 解决TensorFlow程序无限制占用GPU的方法
解决TensorFlow程序无限制占用GPU的方法本文向大家介绍解决TensorFlow程序无限制占用GPU的方法,包括了解决TensorFlow程序无限制占用GPU的方法的使用技巧和注意事项,需要的朋友参考一下 今天遇到一个奇怪的现象,使用tensorflow-gpu的时候,出现内存超额~~如果我训练什么大型数据也就算了,关键我就写了一个y=W*x…显示如下图所示: 程序如下: 出错提示: 占用的内存越来越多,程序崩溃之后,整个电脑都奔溃了,因
-
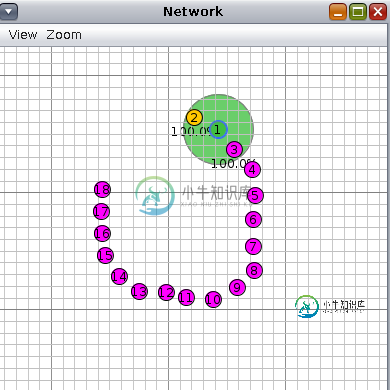 Contiki ng Cooja mote的无线电有效载荷限制
Contiki ng Cooja mote的无线电有效载荷限制考虑如下所示的RPL网络。在此网络中,节点1是DODAG的根。节点2是发送方,向接收方节点(节点3-18)发送单播UDP数据包。DODAG正在非存储模式下工作,我正在使用Contiki NG的Cooja mote来执行此模拟。 问题是数据包只能到达放置在最多12跳之外的节点(本例中为节点13)。例如,当发送者想要为节点16发送数据包时,我们得到了6lowpan的以下警告,数据包在根处被丢弃:“没有
-
用NodeJS进行续集无法限制表的连接
问题内容: 我正在尝试实现一个简单的查询,如下所示: 很简单:我想得到合并结果,然后限制为12。 在Sequelize中,我使用以下功能: 但是此代码生成以下sql: 这与我尝试执行的逻辑完全不同,因为在生成的sql中,它首先获取任何12个结果,然后尝试与entity_area联接,当然,随机的12个结果不一定与entity_area匹配,所以我我没有得到任何结果。 请建议我这样做的正确方法。属性
-
Spark无法使用java。lang.OutOfMemoryError:超出GC开销限制?
这是我的java代码,我在其中使用Apache Spark sql从Hive查询数据。 当我运行此代码时,它抛出java.lang.OutOfMemoryError:超出GC开销限制。如何解决此问题或如何在Spark配置中增加内存。
-
缺少强制管辖权策略文件:无限制
与eclipse有关,因为我可以在cmd中成功运行代码。我在windows 10上使用标准oracleJava版本15和eclipse版本2020-12(4.18.0) 在上面的一行,我得到了如下粘贴的错误。 请注意:为null 异常在java.base/sun.net.www.protocol.https.HttpsURLConnectionImpl.(未知源)在java.base/sun.ne
-
 久邦世纪科技有限公司 游戏运营 业务面
久邦世纪科技有限公司 游戏运营 业务面#运营人求职交流聚集地# 1、久邦世纪科技有限公司,位于广州,是一家中小型互联网公司,主要业务在海外 2、投递了游戏运营和社交产品运营,两个岗位的面试题都不一样 3、面试流程主要是自我介绍,面试官提问,面试者反问,有一个比较有意思的是游戏运营会问你玩过什么游戏,社交产品运营会问你玩过什么社交软件,对这些的了解如何 4、面试官提问:对游戏运营的基本工作了解 用户基础信息字段和行为数据如何进行分析 如
-
无状态和有状态的企业Java Bean
问题内容: 我正在阅读Java EE 6教程,试图理解无状态会话bean和有状态会话bean之间的区别。如果无状态会话bean在方法调用之间没有保持其状态,为什么我的程序按原样运行? 客户端 我原本希望getNumber每次都返回0,但它返回1,并且在浏览器中重新加载servlet会使它更多。问题在于我对无状态会话Bean如何工作的理解,而与库或应用程序服务器无关。有人可以给我一个无状态会话bea
-
无业游民,码头工人,木偶,厨师
问题内容: 我什至不理解标题中服务之间的基本区别。这些服务仅仅是提供软件来帮助您配置/组织/管理VM,还是为VM运行提供物理基础设施?换句话说,它们只是开发人员与AWS,Rackspace和Azure之间的便捷接口吗? 问题答案: 不完全是。 Chef / Puppet是“相同的”,它们是配置管理。尽管您可以使用它们来管理虚拟机或公共/私有云,但是大多数人并不倾向于那样使用它们。它们是配置管理。它
-
kubernetes中的Flink部署无法启动作业
我按照以下指南在kubernetes创建了一个flink集群:https://ci.apache.org/projects/flink/flink-docs-release-1.11/ops/deployment/native_kubernetes.html 作业管理器正在运行。当作业提交给作业管理器时,它生成了一个任务管理器pod,但任务管理器无法连接到作业管理器。
-
如何让业务对象序列化无知?
我有以下业务对象 我有以下用于 json 序列化的接口和实现 这是我的客户代码 这里我不喜欢的是,员工知道它将使用特定的库进行序列化(因为JsonProperty属性)。因此,如果我决定使用另一个json序列化程序或编写自己的,我将需要遍历所有业务对象并修改它们。有可能使我的业务对象序列化变得无知吗?如果是,如何 XML序列化和XmlSerializer类也是一样的:我需要用一些属性标记业务对象中
-
MapReduce作业无法从HBase读取(抛出java.lang.NoClassDefoundError)
我的目标是在Cloudera集群上运行一个简单的MapReduce作业,该作业从虚拟HBase数据库读取并写入HDFS文件。 一些重要的注意事项:-我以前在这个集群上成功运行过MapReduce作业,这些作业将HDFS文件作为输入,并写入HDFS文件作为输出。-我已经将用于编译项目的库从“纯”HBase替换为HBase-cloudera jars-当我以前遇到这类问题时,我只是简单地将库复制到分布
-
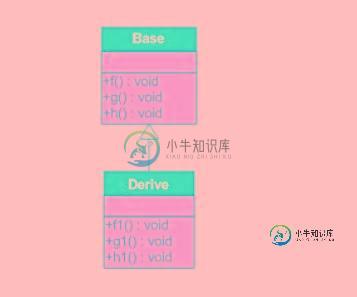 C++ 虚函数专题
C++ 虚函数专题本文向大家介绍C++ 虚函数专题,包括了C++ 虚函数专题的使用技巧和注意事项,需要的朋友参考一下 虚函数 基类中使用virtual关键字声明的函数,称为虚函数。 虚函数的实现,通过虚函数表来实现的。即V-table 这个表中有一个类,用于储存虚函数的地址。解决其继承,覆盖的问题,用于保证其真实反映的函数。这样有虚函数的实例,将会储存在这个实例的内存中。即用父类的指针,操作子类的时候,通过虚函数表