《求职交流聚集地》专题
-
使用两个提交按钮提交jQuery ajax表单
问题内容: 我有一个看起来像这样的表格: 当我绑定到表单的Submit()时,似乎无法访问用户单击的图像。因此,我试图绑定到单击图像本身(),该图像总是提交表单,无论我是否尝试 返回false; event.stopPropogation(); 要么 event.preventDefault(); 因为所有这些都是表单事件。 我应该将$ .post()附加到form.submit()事件上吗,如果
-
测试交易是否会拒绝信用卡交易?
我正在做一些开发使用我创建的payflow api测试仅payflow帐户。(事务处理模式=测试) 我的程序使用安全令牌与托管的签出页面。 当我在托管结账页面中提交信用卡信息时,我的程序的错误URL被调用,错误代码为“12”事务被拒绝。 我尝试手动测试支付到贝宝管理器-->虚拟终端-->单笔交易。我填满了所有的信息(连同实际的信用卡细节),我得到了同样的错误--结果代码=12。响应消息=谢绝。但当
-
脱链交易和链上交易有什么区别?
本文向大家介绍脱链交易和链上交易有什么区别?相关面试题,主要包含被问及脱链交易和链上交易有什么区别?时的应答技巧和注意事项,需要的朋友参考一下 回答:** 链上交易:这些交易在区块链上可用,并且对区块链网络上的所有节点都是可见的。它包括由一定数量的参与者对交易进行身份验证和确认。 链下交易:这些交易处理区块链外部的值,可以使用多种方法进行。
-
交互式经纪人Python API-执行多笔交易
我正在尝试为Python应用编程接口创建一个程序,以便一次下多个交易/市场订单。我在网上使用了一个教程来获取一些代码,并做了一些更改。但是,我不能一次下多个订单。我使用了2个列表1是用于符号,另一个是用于它们的数量。(例如:购买3只苹果股票)。我的代码只执行最后一个订单:即“购买3只客户关系管理股票”。有人能帮我弄清楚如何下多个订单吗? 下面是我的Python代码:
-
如何从众多提交中保留个别提交
如果说在众多提交中,已某个提交为基准,只保留上游众多提交中的某个或者某几个,可以使用 cherry-pick命令,具体是: git cherry-pick <commit id> 如果没有冲突,则回显示如下: Finished one cherry-pick. # On branch dev # Your branch is ahead of 'origin/dev' by 3 commits.
-
我提交了一个交易,但没有被开采。
我提交了一个交易,但没有被开采。 创建和发送交易后,会收到交易hash,但是调用eth_getTransactionReceipt却总是返回空值,指示交易未被挖掘,代码如下: String transactionHash = sendTransaction(...); // you loop through the following expecting to eventually get a
-
向emr提交本地spark作业
im关注亚马逊文档,向emr集群提交spark作业https://aws.amazon.com/premiumsupport/knowledge-center/emr-submit-spark-job-remote-cluster/ 在按照说明进行操作后,使用frecuent进行故障排除,它由于未解析的地址与消息类似而失败。 错误火花。SparkContext:初始化SparkContext时出错
-
带地图键的相交列表
我们有学生的地图记录
-
春季-mongodb-聚合-需要'cursor'选项
问题内容: 执行以下聚合管道: 引发以下异常: 我不明白这里的光标选项是什么意思。该选项应在哪里配置? 编辑 这是一个示例用户文档 问题答案: 从文档。 MongoDB 3.4不建议使用不带游标选项的聚合命令,除非管道包括解释选项。使用聚合命令以内联方式返回聚合结果时,请使用默认批处理大小游标:{}指定游标选项,或在游标选项游标:{batchSize:}中指定批处理大小。 你可以通过与在春季蒙戈2
-
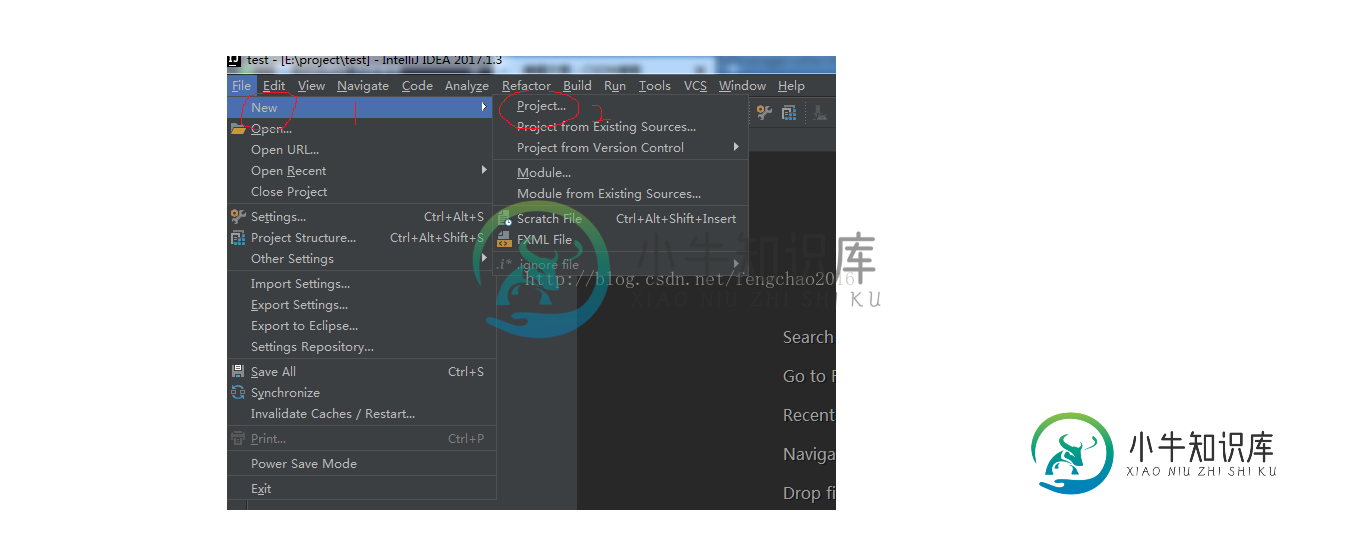 IDEA创建parent项目(聚合项目)
IDEA创建parent项目(聚合项目)本文向大家介绍IDEA创建parent项目(聚合项目),包括了IDEA创建parent项目(聚合项目)的使用技巧和注意事项,需要的朋友参考一下 关于聚合项目和父项目的概念有兴趣的可以去看《MAVEN实战这本书籍》,本篇描述使用IDEA工具创建继承和聚合项目的过程! 创建空白工程:作为存放项目的root目录 步骤一: 步骤2: 步骤3: maven继承:创建父-子项目 项目的结构示意图如下: 1.创
-
jq可以跨文件执行聚合
问题内容: 我正在尝试确定一个程序/软件,该程序/软件将使我能够有效地提取大量大型CSV文件(总计40+ GB),并输出具有导入到Elasticsearch(ES)所需的特定格式的JSON文件。 jq可以有效地获取如下数据: 按ID进行汇总(这样,多个文件中CSV行中的所有JSON文档都属于一个id条目),输出如下所示: 我用Matlab编写了一个脚本,但由于担心它的执行速度慢得多。我可能需要花费
-
深度嵌套类型的Elasticsearch聚合
问题内容: 示例文档中有一个简化的文档。这对我理解非嵌套类型与嵌套类型的聚合差异很有帮助。但是,这种简化掩盖了进一步的复杂性,因此我不得不在这里扩展这个问题。 所以我的实际文件更接近以下内容: 因此,我保留了,和的关键属性,但隐藏了许多其他使情况复杂化的内容。首先,请注意,与引用的问题相比,有很多额外的嵌套:在根和“项目”之间,以及在“项目”和“ item_property_1”之间。此外,还请注
-
Elasticsearch:可以处理聚合结果吗?
问题内容: 我使用SUM聚合计算服务过程的持续时间。执行过程的每一步都将保存在Elasticsearch中的调用ID下。 这是我监视的内容: 过滤: 这将返回该过程的完整持续时间,并且还告诉我该过程的哪一部分是最快的,而哪一部分是最慢的。 接下来,我要通过serviceId 计算 所有已完成过程 的平均 持续时间 。在这种情况下,我只关心每项服务的总时长,因此我可以提供帮助。 如何从total_d
-
ElasticSearch从数组字段过滤聚合
问题内容: 我正在尝试对数组中的值进行聚合,并且还过滤由前缀返回的存储桶。不知道这是否可行,或者我滥用过滤桶。 3份文件: 目的是获取带有字母B开头颜色的文档数量: 不幸的是,返回的结果包括Red。显然是因为带有红色的文档仍然按过滤器匹配,因为它们也具有蓝色和/或黑色。 有没有一种方法可以只过滤存储桶结果? 问题答案: 尝试此操作,它将过滤为存储桶本身创建的值:
-
ElasticSearch术语按整个字段聚合
问题内容: 如何编写一个将整个字段值而不是单个标记考虑在内的ElasticSearch术语聚合查询?比如,我想通过城市名聚集,但下面的回报,,并作为单独的水桶,不和的水桶预期。 问题答案: 您应该在映射中解决此问题。添加一个not_analyzed字段。如果您还需要分析的版本,则可以创建多字段。 现在在city.raw上创建聚合