《求职交流聚集地》专题
-
流数和常数的流平均值
这是我的代码,它根据一个人所做测试的平均分数返回一个分数。 以下是CourseResult类供参考 和2种生成测试分数的方法。历史结果 和编程结果 所以每个人有3个测试分数。如果我使用编程生成分数,结果很好,因为只有3个编程测试,但是如果我使用历史生成分数,结果我也每个人得到3个测试分数,但是我应该把它当作第四个测试根本没有尝试,这意味着0分。我如何让我的定义标记方法得到收集的测试分数的平均值,而
-
使用Spring云流测试错误流
我已经使用Spring云流启动了一个小型微服务。 我只有两个流绑定,如下所示: 我用Serenity开发了组件测试,我将通道注入到我想要发送测试消息的地方: 哪里: 只是定义为字符串常量: 组件测试模块导入依赖项: 我发送的信息如下: 快乐流工作正常。但是,我想在侦听器无法处理消息时测试错误流。 这是一个监听器的例子: 从try/catch引发异常时,错误由服务激活器处理: 在没有Spring-C
-
Java将可选流转换为值流
本文向大家介绍Java将可选流转换为值流,包括了Java将可选流转换为值流的使用技巧和注意事项,需要的朋友参考一下 示例 您可能需要一个转换Stream发射Optional到一个Stream值,从现有的发射只值Optional。(即:没有null价值,不与之打交道)。Optional.empty()
-
从流和元素生成流 Java 8
我正在研究一些Java8流特性。我对FP相当熟悉,三十年前写过一些Lisp,我想我可能会尝试做一些新工具不真正针对的事情。不管怎样,如果这个问题很愚蠢,我很高兴知道我的错误。 我将给出一个具体的问题,尽管它实际上是我试图解决的一般概念。 假设我想从流的每三个元素中获取一个流。在常规FP中,我将(近似地)创建一个递归函数,该函数通过在删除两个元素之后将列表的第一个元素与列表的其余元素(调用thyse
-
与流行为不同的平行流
结果:1 2 3 有人能解释为什么会发生这种情况,以及我如何让非并行版本给出与并行版本相同的结果吗?
-
流是否使用流源的特征?
从这个问题 报告不可变或并发的拆分器保证不会抛出ConcurrentModificationException。当然,CONCURRENT排除了语义上的大小,但这对客户机代码没有影响。 事实上,这些特性在Stream API中没有任何用途,因此,不一致地使用它们永远不会在任何地方被注意到。 这也是为什么每个中间操作都有清除并发、不可变和非空特性的效果的原因:流实现不使用这些特性,其表示流状态的内部
-
将字符串流转换为长流
我有一个,我希望将其转换为。在Java8之前,我会通过循环,将每个转换为并将其添加到新的,如下所示。
-
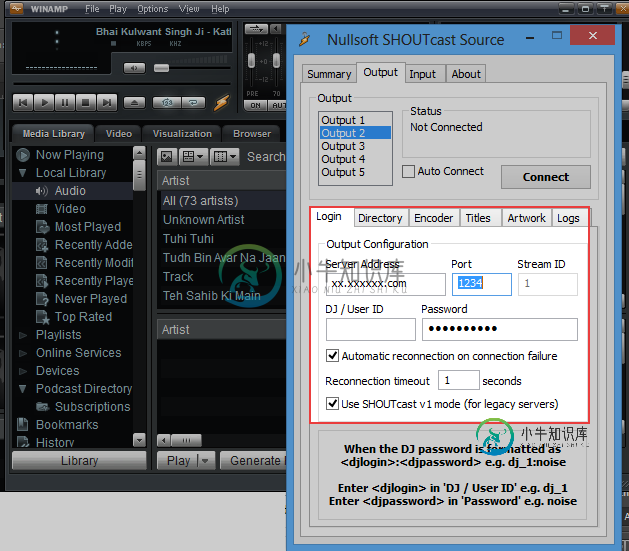 从Android设备流到shoutcast(上行流)
从Android设备流到shoutcast(上行流)感谢大家提前:) 我想在你开始阅读之前说清楚,我想开发一个基于Android的应用程序,使用Android设备作为广播公司,它使用麦克风记录声音,并将其发送到shoutcast服务器,类似于这样: 连接互联网的Android设备- 所以请不要在android上玩shoutcast流混淆,因为我不想开发一个播放器来玩流。如果你正在寻找开发一个播放器,然后从给定的链接下载源代码,它对我来说很好。点击下
-
如何将流动转换为流动?
我刚刚补充道 对这个项目。我有<code>suspend fun foo():Flow 我需要获得
-
Spark结构化流-比较两个流
我正在使用Kafka和Spark 2.1结构化流。我有两个json格式的数据主题,例如: 我需要比较Spark中基于标记的两个流:name,当值相等时,执行一些额外的定义/函数。 如何使用Spark结构化流来做到这一点? 谢谢
-
第7章 IO流 - IO流之File类
typora-copy-images-to: img 1. File类概述 File类用于封装一个路径,这个路径可以是从系统盘符开始的绝对路径,如:“D:\file\a.txt”,也可以是相对于当前目录而言的相对路径,如:“src\Hello.java”。File类内部封装的路径可以指向一个文件,也可以指向一个目录,在File类中提供了针对这些文件或目录的一些常规操作。 文件和目录路径名的抽象表示
-
流量管理 - 控制 Egress TCP 流量
如控制Egress流量告诉我们可以从服务网格内部应用访问外部(指在Kubernetes外的服务)的 HTTP 和 HTTPS 服务。默认情况下,支持 istio 的应用程序无法直接访问集群外部的 URL 。要启用这种访问,必须先定义 Egress 规则或者配置直接调用外部服务规则。 此任务描述如何配置 Istio 内应用如何访问 Istio 外部的应用。 开始之前 遵循安装指南设置Istio 启动
-
查找SQL中超集的子集的所有集
问题内容: 我正在考虑一个应用程序的设计,该应用程序的主要功能围绕着找到所有给定集合的子集的集合的能力而展开。 例如,给定输入集A = {1,2,3 … 50}和集合集B = {B1 = {3,5,9,12},B2 = {1,6,100,123,45}。 .. B500 = {8,67,450}},返回所有属于A子集的B。 我想它与搜索引擎类似,除了我并没有设置A小而B大的奢侈。在我的情况下,B通
-
收集Firestore收集和子收集文档数据
我的Ionic 5应用程序中有以下Firestore数据库结构。 书(集合) {bookID}(带有book字段的文档) 赞(子集合) {userID}(文档名称作为带有字段的用户ID) 集合中有文档,每个文档都有一个子集合。Like collection的文档名是喜欢这本书的用户ID。 我正在尝试进行查询以获取最新的,同时尝试从子集合中获取文档以检查我是否喜欢它。 我在这里做的是用每个图书ID调
-
Java 8中的流作为流的笛卡尔积(仅使用流)
问题内容: 我想创建一个方法,该方法创建元素流,这些元素流是多个给定流的笛卡尔积(由二元运算符最后汇总为相同类型)。请注意,参数和结果都是流, 而不是 集合。 例如,对于 {A,B} 和 {X,Y}的 两个流,我希望它产生值 {AX,AY,BX,BY}的流 (简单串联用于聚集字符串)。到目前为止,我想出了以下代码: 这是我想要的用例: 预期结果:。 另一个例子: 预期结果:。 但是,如果我运行代码