《2022滴滴秋储实习》专题
-
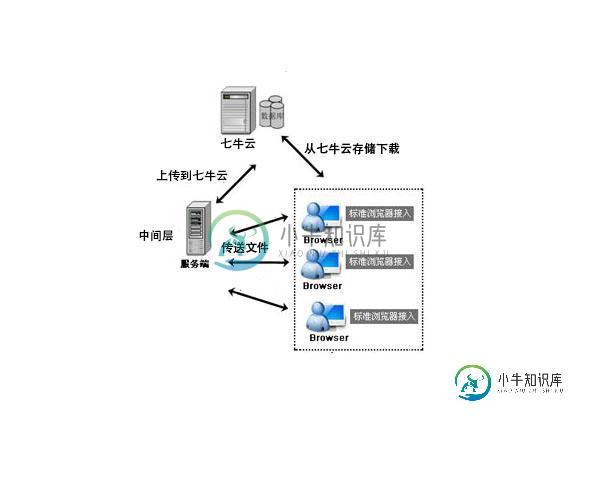 使用Plupload实现直接上传附件至七牛云存储
使用Plupload实现直接上传附件至七牛云存储本文向大家介绍使用Plupload实现直接上传附件至七牛云存储,包括了使用Plupload实现直接上传附件至七牛云存储的使用技巧和注意事项,需要的朋友参考一下 这个插件主要针对哪些用户? 1.空间小想做下载服务器的用户,既没有足够的带宽,又没有足够大的空间,我们这个怎么弄呢?将我们的网站做成中间层,然后用户上传到服务器其实就上传到了七牛云存储,下载也是等同于在七牛下载,即省了空间又省了带宽,解决了
-
mysql中的varchar(100)声明使用多少实际存储空间?
问题内容: 如果我有一个表,该表的字段声明为接受varchar(100),然后实际上插入单词“ hello”,那么在mysql服务器上将使用多少实际存储空间?即使声明了varchar(100),插入NULL也会导致不使用任何存储吗? 答案是什么,在不同的数据库实现中是否一致? 问题答案: 如果我有一个表,该表的字段声明为接受varchar(100),然后我实际上插入单词“ hello”,那么在my
-
自定义Jpa存储库错误,带有片段实现错误
我目前正在spring boot中编写一个应用程序,并正在构建自己的自定义存储库。 首先,这里是有问题的代码: 启动应用程序后,它会失败,并出现以下堆栈跟踪: 非常感谢您的帮助:) 注意:此设置以前与JPA存储库一起使用,因此这不是服务调用它的问题,而是新服务存储库的故障。
-
oracle 存储过程、函数和触发器用法实例详解
本文向大家介绍oracle 存储过程、函数和触发器用法实例详解,包括了oracle 存储过程、函数和触发器用法实例详解的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了oracle 存储过程、函数和触发器用法。分享给大家供大家参考,具体如下: 一、存储过程和存储函数 指存储在数据库中供所有用户程序调用的子程序叫存储过程、存储函数。 创建存储过程 用CREATE PROCEDURE命令建立存储
-
使用spring batch在地图上存储文件的最佳实践
我是Spring批处理的新手,我想找到使用用例的完美方法,如下所示: 我有多个csv文件,我想把它们存储在内存(作为集合存储...即列表地图),然后我想在我的逻辑业务的下一步/作业中使用/引用它们。 让我们举一个例子,一个对象XX和一个ItemWriter一起存储在地图上。 对象XX模型 对象X的itemReader 目标作者 正如你可以看到所有的记录都存储在地图与itemWriter,我做了一个
-
具有多个实体查找器的通用spring jpa存储库
我的应用程序有250多个表,每个表都有ID和name列。我正在尝试用Hibernate5+将我们的应用程序从Hibernate3迁移到Spring-JPA4.3。 在当前的hibernate层中,我有(选项1): 因此,如何在一个JPA存储库中执行以下操作:
-
没有封装实例的类型储蓄是可访问的java
我只是收到这样的信息:“没有可访问的类型savings的封闭实例。”从17号线开始。我不知道IDE是什么样的实例。我现在学习java已经两周了。 }
-
有没有办法将响应实体存储在redis缓存中?
我尝试了以下代码,但出现了错误-spring web ResponseEntity无法序列化。 org.springframework.data.redis.serializer.SerializationException:无法序列化;嵌套异常org.springframework.core.serializer.support.SerializationFailedException:无法使用
-
Kafka流-指向同一主题的所有实例本地存储
我们希望侦听特定的Kafka主题,并构建它的“历史”--所以对于指定的键,提取一些数据,将其添加到该键的现有列表中(如果不存在,则创建一个新的列表),并将其放到另一个主题中,该主题只有一个分区,并且高度压缩。另一个应用程序可以只听这个主题并更新它的历史列表。 我在想它如何适合Kafka流库。我们当然可以使用聚合: 它创建一个由Kafka支持的本地存储,并将其用作历史表。 问题是,如果我只是为每个正
-
如何在Spring boot的main方法中创建存储库实例?
它警告我,@Autowired在静态方法上是不允许的。当执行时,它给出null异常。我读过这个不能在Spring Boot应用程序的主方法中使用@Autowired JPA存储库 但它没有给出我如何做到这一点的任何信息。我不想使用属性文件。
-
JVM堆转储:内存积累在“java.util.concurrent.concurrentHashMap$segment”的一个实例中
我在JVM-heap上遇到了麻烦。 我们使用Apache HTTP服务器和Apache Tomcat应用服务器操作一个网站。 所有对Apache HTTP服务器的*.jsp请求都将重定向到Tomcat服务器(协议:ajp)。 以下是eclipse Mat的报告: 由“org.apache.catalina.loader.StandardClassLoader@0x7092C5148”加载的“org
-
Android Room:如何在实体类中存储多个相同响应
谢谢
-
在Spring Boot上创建存储库的最佳实践是什么?
我想创建一对多的映射,就像Post有很多评论一样。我有两种添加评论的解决方案。第一种解决方案是为评论创建一个存储库,第二种解决方案是使用PostRepository并获取post并将评论添加到帖子中。每个解决方案都有自己的挑战。 在第一种解决方案中,为每个实体创建存储库会过多地增加存储库的数量,并且基于DDD,应该为Aggregate Roots创建存储库。 在第二个解决方案中,存在性能问题。若要
-
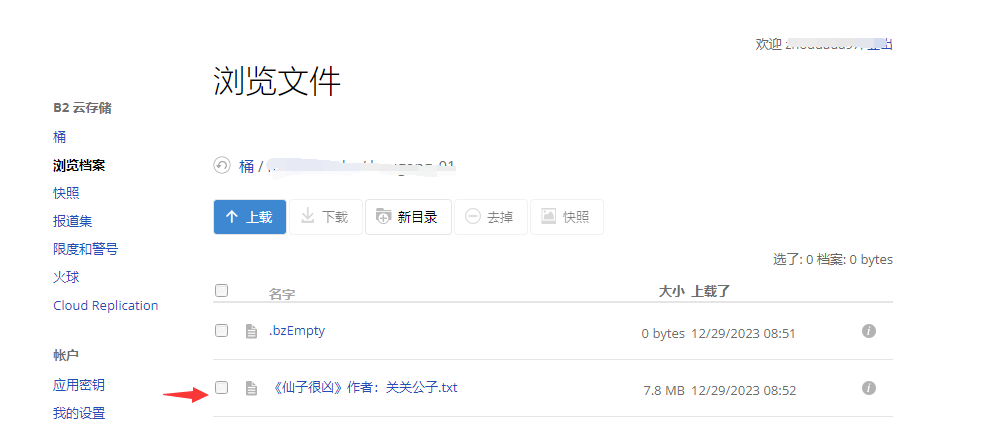 如何实现云存储 txt下载而不是直接打开?
如何实现云存储 txt下载而不是直接打开?把某txt文件上传到云存储,目前用的是backblaze。 得到一个URL,比如 域名/目录/a.txt。 复制URL到浏览器打开,如何实现下载txt,而不是直接打开? 目前只知道把URL转成迅雷URL,可以实现通过迅雷下载txt
-
返回实体 A 和实体 B 的连接,并在没有 JQL/HQL 的Spring JPA 中存储在实体 C 中
我有以下实体: 我想获得员工和帐户连接的分页结果,并将值存储在员工帐户记录类的对象中。此外,我还想将排序/过滤器传递给实现它的存储库。 这能在不用JPQL/HQL编写查询的情况下完成吗,可能使用JPA规范等,任何其他组件? 我使用Spring数据JPA和Hibernate。 非常感谢。 PS:结果对象仅使用联接值中结果集的子集。