《存储》专题
-
 OrientDB缓存
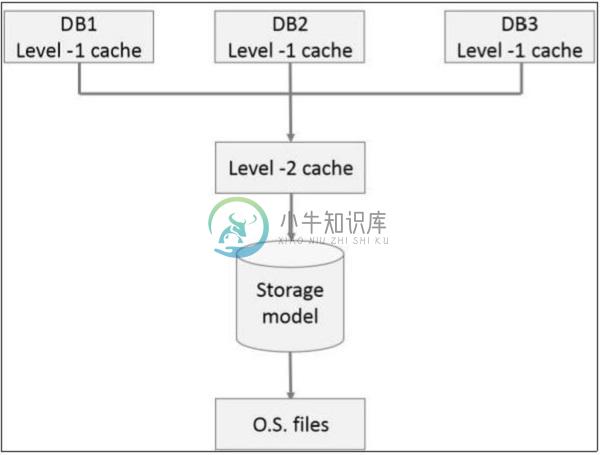
OrientDB缓存主要内容:OrientDB缓存工作原理,本地模式(嵌入式数据库),客户服务器模式(远程数据库)缓存是一个概念,它将创建数据库表结构的副本,为用户应用程序提供一个舒适的环境。 OrientDB在不同级别有多种缓存机制。 下面的插图给出了关于什么是缓存的说明。 在上图中,DB1,DB2,DB3是应用程序中使用的三种不同的数据库实例。 一级缓存是一个本地缓存,用于存储特定会话已知的所有实体。 如果您在此会话中有三笔交易,则它将持有所有三笔交易使用的所有实体。 当您关闭会话或执行“清除”方法时,此
-
Django缓存
主要内容:在数据库设置缓存,在文件系统设置高速缓存,设置缓存在内存中,缓存整个网站,缓存视图,缓存模板片段若要缓存一些昂贵的计算结果, 下一次你需要它时不需要再执行它。以下是解释缓存如何工作的伪代码− Django提供了自己的缓存系统,可以让您保存动态网页,为了避免在需要时重新计算它们。Django缓存架构的优点是,让你缓存 - 特定视图的输出 模板的一部分 整个网站 要使用在Django中使用高速缓存,首先要做的是设置在那里的缓存会保存下来。高速缓存框架提供了不同的可能性 - 高速缓存可以被保
-
HTTP 缓存
除了前面章节讲到的服务器端缓存外, Web 应用还可以利用客户端缓存 去节省相同页面内容的生成和传输时间。 通过配置 yii\filters\HttpCache 过滤器,控制器操作渲染的内容就能缓存在客户端。 HttpCache 过滤器仅对 GET 和 HEAD 请求生效, 它能为这些请求设置三种与缓存有关的 HTTP 头。 Last-Modified Etag Cache-Control Las
-
内存篇
链接 gcore + llnode heapdump memwatch-next cpu-memory-monitor
-
内存池
交易排序 目前,除了交易到达的顺序(通过 RPC 或来自其他节点)之外,没有其他交易的顺序。 因此,指定顺序的唯一方法是将它们发送到单个节点。 valA: tx1 tx2 tx3 如果交易被分割到不同的节点,则无法确保按照预期的顺序处理它们。 valA: tx1 tx2 valB: tx3 如果 valB 是提议人,排序可能是: tx3 tx1 tx2 如果 valA 是提议人,排序可能是: tx
-
1.6.2 缓存
配置 在 .env 文件中, 有个 CACHE_DRIVER 的选项, 用来配置使用哪个类型的缓存, Lumen 支持以下的几种: array file memcached redis database Note: 如果你需要使用 .env 来管理你的配置信息的话, 请在 bootstrap/app.php 文件里面把这一行去掉注释 Dotenv::load(). Memcached 如果你想使用
-
1.8.13.2.1 缓存
缓存配置参考。 filter.http.Buffer filter.http.Buffer proto { "max_request_bytes": "{...}", "max_request_time": "{...}" } max_request_bytes (UInt32Value) 在连接管理器停止缓冲并返回413响应之前,过滤器将缓冲的最大请求大小。 max_request_t
-
1.7.4.1 缓存
缓冲区配置概述。 { "name": "buffer", "config": { "max_request_bytes": "...", "max_request_time_s": "..." } } max_request_bytes (required, integer) 在连接管理器停止缓冲并返回413响应之前,过滤器将缓冲的最大请求大小。 max_reques
-
1.4.6.1 缓存
缓冲区过滤器用于并等待并缓冲的完整请求。这在特殊场景下会很有用,如:保护一些应用程序,不必关心和处理部分请求,及高网络延迟。 v1 API 参考 v2 API 参考 统计 缓冲过滤器输出统计信息以http.<stat_prefix>.buffer.命名空间。 stat_prefix来自拥有的HTTP连接管理器。 名称 类型 描述 rq_timeout Counter 等待完整请求超时的请求总数 返
-
1.4.7 缓存
LRU LRU是Least Recently Used的缩写,即最近最少使用,常用于页面置换算法,是为虚拟页式存储管理服务的。 好多种 LRU-K Multi Queue(MQ) Two queues(2Q) LRU 典型实现 memcache redis redis 5种数据类型 String——字符串 Hash——字典 List——列表(链表(redis 使用双端链表实现的 List)) Se
-
1.7.42 缓存
ReferenceConfig 实例很重,封装了与注册中心的连接以及与提供者的连接,需要缓存。否则重复生成 ReferenceConfig 可能造成性能问题并且会有内存和连接泄漏。在 API 方式编程时,容易忽略此问题。 因此,自 2.4.0 版本开始, dubbo 提供了简单的工具类 ReferenceConfigCache用于缓存 ReferenceConfig 实例。 使用方式如下: Ref
-
14.2 缓存
缓存 如果有很多张图片要显示,最好不要提前把所有都加载进来,而是应该当移出屏幕之后立刻销毁。通过选择性的缓存,你就可以避免来回滚动时图片重复性的加载了。 缓存其实很简单:就是存储昂贵计算后的结果(或者是从闪存或者网络加载的文件)在内存中,以便后续使用,这样访问起来很快。问题在于缓存本质上是一个权衡过程 - 为了提升性能而消耗了内存,但是由于内存是一个非常宝贵的资源,所以不能把所有东
-
32. 缓存
-
暂存区
Staging Area,暂存区 / 中间区。把对项目做的修改,先放到暂存区,然后再做提交。 用法 把对某个文件的所有修改添加到暂存区: git add <文件> 把在某个目录下做的所有修改添加到暂存区: git add <目录> 把做的所有修改还有新的文件添加到暂存区(不包含删除文件): git add . 把所有东西放到暂存区(修改,新文件,删除文件): git add -A 把做的所
-
缓存(Caching)
缓存是存储可重用响应的术语,以便使后续请求更快。 每个浏览器都附带一个HTTP缓存实现。 我们所要做的就是确保每个服务器响应都提供正确的HTTP头指令,以指示浏览器在何时以及浏览器缓存响应的时间和长度。 以下是在您的网络应用程序中包含缓存的一些好处 - 您的网络成本会降低。 如果您的内容已缓存,则您需要为每个后续请求发送较少的内容。 您网站的速度和性能会提高。 即使您的客户离线,您的内容也可用。