《字节跳动面经》专题
-
 字节飞书后端面试(日常实习)
字节飞书后端面试(日常实习)一面(2024.1.3,85min) 自我介绍 项目(聊了蛮久) Redis Redis单线程结构 Kafka(项目中用到了) 架构说一下 consumer如何进行消费的过程 分布式当扩充新的机器,数据如何进行调整?(唯一没答出来的八股) 集群只用2个节点可以吗?为什么不行? MySQL B+树,B树与B+树区别?存相同的数据哪个树高? MySQL如何实现乐观锁? 不停机扩容如何实现? Dubbo
-
 字节24届提前批一面 数据库
字节24届提前批一面 数据库7.13面的 自我介绍 研究生期间做的内容 超卖和少卖 redis分布式锁的缺点(redlock的缺陷) zk分布式锁的缺点(强一致性,业务上更应该关注ap而非cp) zk配合mysql防止超卖和少卖 base是什么 强一致性和最终一致性 raft流程 强一致有什么用 linux内核有哪些锁 实现一个互斥锁需要那些字段(排队链表) 互斥锁队列如何选择谁持有锁(取队头,人为优先级,执行时间短优先)
-
 字节data大数据开发一面6.19-50min
字节data大数据开发一面6.19-50min1.问本科经历,对大数据的接触 2.问项目是否是真实项目或者实习项目,,不是demo 3.项目介绍,毕设项目讲了15分钟 4.where和having区别(having能单用) 5.Spark宽窄依赖 6.leftrightinnerjoin 7.sql写题,统计所有月销售额超过1w的员工 8.反问,ABtesting--是否是埋点-PVUV-灰度策略的流程
-
 字节-抖音-生活服务-后端-二面
字节-抖音-生活服务-后端-二面1. 自我介绍 2. 项目:项目数据链路,如果大量数据写入mq会怎样,哪里会成为瓶颈。 3. 八股: http https 签名验签 http thrift 对比 http body 格式 4. 算法: 数组里每一个数字的下一个更大的数
-
 字节-生活服务-后端实习-一面
字节-生活服务-后端实习-一面自我介绍 聊第一个项目 遇到了什么比较有挑战的部分? (慢SQL优化,介绍了用的几种优化方法) 还有呢? (并发抢单redis实现) 用了zset的话? zset的几种数据结构 第二个项目 内存trie树怎么实现的 (ac自动机) Ac自动机是怎么实现的?(trie+kmp) 具体解决了普通trie树的什么问题 八股 TCP与UDP 对堆和栈的理解?为什么不能只有堆or栈呢 Mysql都有什么索引
-
通过套接字Java发送字节数组、字符串和字节
我需要通过Java socket发送一个文本消息到服务器,然后发送一个字节数组,然后是一个字符串等等。到目前为止,我所开发的内容还在工作,但客户端只读取发送的第一个字符串。 从服务器端:我使用发送字节数组,使用发送字符串。 问题是客户机和服务器不同步,我的意思是服务器发送字符串然后字节数组然后字符串,而不等待客户机消耗每个需要的字节。 我的意思是情况不是这样的:
-
 字节后端24届实习 二面面经(高质量面试,但居然过了?)
字节后端24届实习 二面面经(高质量面试,但居然过了?)字节二面(110+min 高质量面试) 说实话,这次面的问题真的很难,很多问题我都是要提醒一下才能回答上来,场景题很多、还有用场景结合八股的 有点措不及防,答的稀烂 但过了我是不太理解的 ,可能发面经真的有用,来还愿了(已约三面) 1、自我介绍 2、介绍一下做的比较好的项目(这里我介绍了RPC,被问题狂烂轰炸) RPC项目的问题 2.1 问我RPC中的线程模型,比如说主线程、工作线程,这些我是怎么
-
从字节数组中删除前16个字节
问题内容: 在Java中,如何获取byte []数组并从数组中删除前16个字节?我知道我可能必须通过将阵列复制到新阵列中来执行此操作。任何例子或帮助将不胜感激。 问题答案: 参见Java库中的类:
-
字节vs字节数组在Python 2.6和3中
问题内容: 我正在Python中测试vs。我不明白某些差异的原因。 一个迭代器返回的字符串: 给出: 但是迭代器返回s: 给出: 为什么会有所不同? 我想编写可以很好地转换为Python 3的代码。那么,Python 3中的情况是否相同? 问题答案: 在Python中,2.6字节只是str的别名 。 引入此“伪类型”是为了(部分地)准备要与Python 3.0转换/兼容的程序(和程序员!),在Py
-
jupyterlab互动情节
问题内容: 我正在使用Jupyter笔记本中的Jupyterlab。在我以前使用的笔记本中: 用于交互式地块。现在给我(在jupyterlab中): 我还尝试了魔术(安装了jupyter-matplotlib): 但这只是返回: 内联图 工作正常,但我想要交互式地块。 问题答案: 完成步骤 1. 安装nodejs,例如。 2. 安装ipympl,例如。 3. [可选,但推荐;更新JupyterLa
-
了解Java字节
问题内容: 因此,在昨天的工作中,我不得不编写一个应用程序来计算AFP文件中的页数。因此,我整理了我的MO:DCA规范PDF,找到了结构化字段及其3个字节的标识符。该应用程序需要在AIX机器上运行,所以我决定用Java编写它。 为了获得最大效率,我决定读取每个结构化字段的前6个字节,然后跳过该字段中的其余字节。这会让我: 因此,我检查字段类型,如果是,则增加页面计数器,如果不是,则不增加。然后,我
-
Concat字节数组
问题内容: 有人可以指出以下更有效的版本吗 每个变量都是一个字节片,大小不一 : 码: : 基准测试结果: 问题答案: 如果已经分配了内存,则x = append(x,a …)的序列在Go中非常有效。 在您的示例中,初始分配(制造)的成本可能比附加序列的成本高。这取决于字段的大小。考虑以下基准: 在我的盒子上,结果是: 系统地重新分配缓冲区(甚至是很小的缓冲区)会使此基准测试速度至少慢5倍。 因此
-
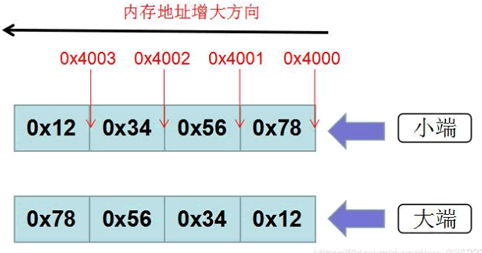 NumPy字节交换
NumPy字节交换主要内容:numpy.ndarray.byteswap()数据以字节的形式存储在计算机内存中,而存储规则可分为两类,即小端字节序与大端字节序。 小端字节序(little-endian),表示低位字节排放在内存的低地址端,高位字节排放在高地址段,它与大端字节序(big-endian)恰好相反。 对于二进制数 0x12345678,假设从地址 0x4000 开始存放,在大端和小端模式下,它们的字节排列顺序,如下所示: 图1:字节存储模式 小端存储后:0x
-
比较字节值?
问题内容: 我很好奇为什么,当我将一个数组与一个值进行比较时… …返回,而… …才不是?是一个数组 问题答案: 比较整数,因为0xFF是整数,此表达式 会将您的字节 扩展为int并将括号内的内容与第二int进行比较。至于你说的是,它将首先被调整为整数且相比于整数,所以这个作品。 将一个字节与int比较: 是一个字节(有符号),其值为。 不等于,因此这就是为什么在比较integer之前必须将data
-
 字节-测开(凉)
字节-测开(凉)+ 为什么考虑面试测试开发方式? :测试需要细心毅力个人兴趣 + 代表性技术优势项目? + 项目业务流实现流?实现层面、各个模块用到的关键技术点? (纯纯数据库CRUD怎么说哇我哭) + Redis基本数据类型、set和zset区别 + 缓存击穿是什么、与正常缓存未命中区别 + C++ const和define + C++多态典中典 + 数据结构堆排序排序过程? : 我说的是new一个优先队列,然