《云和恩墨》专题
-
使用Django将目录从Google云存储桶递归复制到另一个Google云存储桶
我打算将包含所有文件和目录的整个目录从一个谷歌云存储桶递归复制到另一个谷歌云存储桶。 从本地到Google云存储桶,以下代码运行良好: 如何在同一个项目中将目录从一个bucket递归复制到另一个bucket?
-
使用Python API将文件从谷歌云数据实验室上传到谷歌云存储桶
我正试图使用Python应用编程接口将文件从笔记本中的数据实验室实例上传到我的谷歌存储桶,但我无法解决这个问题。谷歌在其留档中提供的代码示例似乎在数据实验室中不起作用。我目前正在使用gsutil命令,但想了解如何在使用Python应用编程接口时做到这一点。 文件目录(我想上传checkpoints文件夹中的python文件): 当前代码: 目前的工作解决方案:
-
撇开价格不谈,为什么选择谷歌云Bigtable而不是谷歌云数据存储?
如果我对海量数据存储和搜索能力都有一个用例,为什么我会选择Google Cloud Bigtable而不是Google Cloud Datastore? 我看到了一些关于“比较”Bigtable和Datastore的问题,但似乎归结为相同的非特定答案。 以下是我目前的知识和想法: 数据存储更昂贵。 在这个问题的背景下,让我们完全忘记定价。 Bigtable适用于大型数据集。 看来Datastore
-
如何在Google App Engine /云中运行Selenium?
问题内容: 我想在云端或在线远程执行Selenium脚本,并被告知Google App Engine是一种可能性。 任何帮助将不胜感激如何在Google App引擎或云上运行脚本。 任何其他有关在线运行脚本的想法也将受到欢迎。 问题答案: Google App Engine并不现实,因为它不支持创建线程,也不支持本机代码。浏览器同时需要。
-
阿里云mysql空间清理的方法
本文向大家介绍阿里云mysql空间清理的方法,包括了阿里云mysql空间清理的方法的使用技巧和注意事项,需要的朋友参考一下 今天收到阿里云磁盘告警通知,查看了一个100G的空间已达到80G的使用量,如果决定删除2018年1月1日之前的数据,可delete后,再去查看发现磁盘可用空间并没有减少,还飞速的上涨,这可把我急坏了,不一会儿数据库就锁死了。 敢忙找度娘,原来delete后,磁盘不会减少,还得
-
 在阿里云Centos下如何安装Nginx
在阿里云Centos下如何安装Nginx本文向大家介绍在阿里云Centos下如何安装Nginx,包括了在阿里云Centos下如何安装Nginx的使用技巧和注意事项,需要的朋友参考一下 Nginx("engine x")是一款轻量级的HTTP和反向代理服务器。相比于Apache、lighttpd等,它具有占有内存少、并发能力强、稳定性高等优势。它最常见的用途就是提供反向代理服务。 在Linux下我们需要下载Nginx的源代码包并且手动编译
-
Spring云配置服务器身份验证
将配置服务器用户名和密码存储为环境变量(在客户端和服务器中)还是使用密钥库更好?密钥库密码无论如何都存储为环境变量,那么为什么实际使用密钥库呢?还是有更好的方法在SpringCloudConfig服务器中实现身份验证?
-
春云网飞通过zuul提供服务
在 spring-cloud-netflix 设置中(一切都使用 feign、ribbon、eureka、zuul),是否有任何简单/优雅/开箱即用的方式(即基于 serviceId 与 URL 的发现)让 CompositeAB 通过 Zuul 与 ServiceA 和 ServiceB 通信?在我看到的所有示例中,CompositeAB 直接发现并调用 ServiceA,而不是通过 Servi
-
Spring云数据流-保留消息顺序
假设我有一个包含3个应用程序的流——一个源、处理器和接收器。 我需要保留从源收到的消息的顺序。当我收到消息A,B,C,D,我必须将它们作为A,B,C,D.发送到接收器(我不能将它们作为B,A,C,D)发送。 如果每个应用程序只有一个实例,那么一切都将按顺序运行,并且顺序将被保留。 如果我每个应用程序有 10 个实例,则消息 A、B、C、D 可能会在不同的实例中同时处理。我不知道这些消息的顺序是什么
-
春云流3.x-回放消息策略
我正在寻找一些关于利用Spring Cloud Stream 3 . x/Kafka binder实现的Kafka主题的重放消息策略的指导- > < li> 重播特定消息[例如通过时间戳窗口]。如何为消费者组中的所有或部分消费者重置补偿? 是否可以从主题的特定分区重播[如果我们知道我们有兴趣重放的消息的分区]? 一般来说,关于消息回放的最佳实践是什么。感谢您抽出时间。
-
Firebase云消息:通知一对一“重复”
如何通过firebase云消息将通知从一台android设备发送到另一台设备?我不想使用firebase的管理面板来发送通知,我只想从一个设备发送到另一个设备。
-
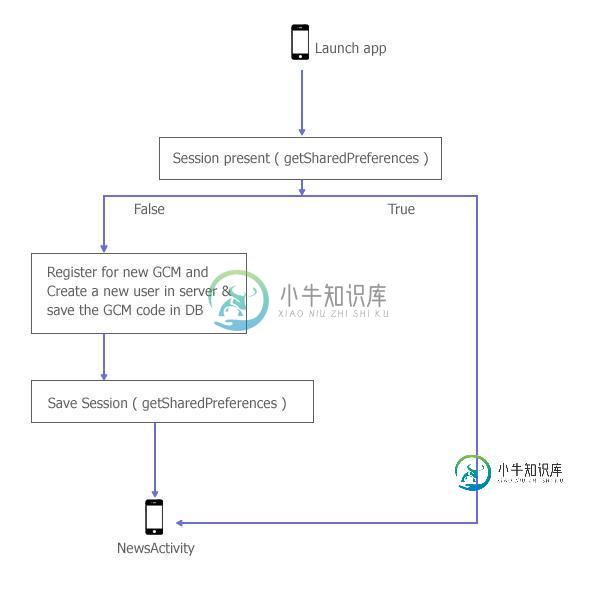 谷歌云消息逻辑解决方案
谷歌云消息逻辑解决方案请任何一个建议我对我的Android应用程序的逻辑怀疑。 我的应用程序不需要注册即可使用。但是我需要向所有用户发送推送通知(比如GCM)。所以我制作了一个数据库表,如下所示 因此,逻辑如下 现在的问题是 情况1:当用户在手机中“清除数据”并重新启动应用程序时,将发生另一个注册过程。因此,当我们发送消息推送时,用户将获得多次(自上次gcmrecd出现在我们的数据库中) 因为它是一个简单的新闻应用程序
-
Spring云流Kafka活页夹Ktable不工作
我正在尝试通过SCSt频道构建并获取KTable。但这并不奏效。输入KTable没有数据,但如果我尝试查看KSTream聚合(toStream()),我可以看到一些数据。我明白了,KTable是不可查询的,它没有可查询的名称。 类别: 绑定: application.yml:
-
故障云数据流管道的诊断
在大约14个工作小时后,我有一个云数据流管道失败,下面是一条神秘的日志消息: 谢了!
-
使用Kafka Binder在Spring云中打印JsonObject
我是春云和Kafka流的新手。我正在尝试使用 kafka 活页夹设置Spring云应用程序。我尝试在本地测试 kafka 流处理器,但我无法打印任何日志。 我的kafka消息将包含JSONObject。kafkaStreamListener类是: Application.properties: 问题:在调试模式下,断点直接到达过滤器步骤,然后不执行任何操作。它跳过了记录器和SOP。不知道可能是什么