《原型》专题
-
从物理文件还原MySQL数据库
问题内容: 是否可以从物理数据库文件还原MySQL数据库。我的目录具有以下文件类型: client.frm client.MYD client.MYI 但要多出约20张桌子 我通常使用mysqldump或类似的工具在1个SQL文件中获取所有内容,那么如何处理这些类型的文件呢? 问题答案: MySQL MyISAM表是三个文件的组合: FRM文件是表定义。 MYD文件是存储实际数据的位置。 MYI文
-
Java日期与时间类原理解析
本文向大家介绍Java日期与时间类原理解析,包括了Java日期与时间类原理解析的使用技巧和注意事项,需要的朋友参考一下 这篇文章主要介绍了Java日期与时间类原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 基础知识 日期: 类似于 2018-12-12 时间: 类似于 2018-12-12 12:12:12 时刻: 类似于 2018-12
-
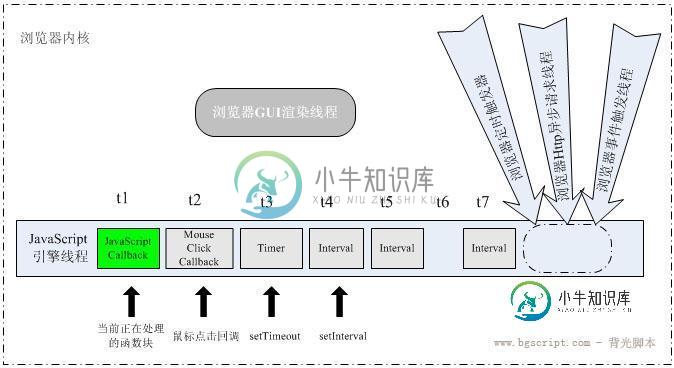 JavaScript定时器实现的原理分析
JavaScript定时器实现的原理分析本文向大家介绍JavaScript定时器实现的原理分析,包括了JavaScript定时器实现的原理分析的使用技巧和注意事项,需要的朋友参考一下 JavaScript中的定时器大家基本在平时的开发中都遇见过吧,但是又有多少人去深入的理解其中的原理呢?下面我们就来分析一下定时器的实现原理。 一、储备知识 在我们在项目中一般会遇见过这样的两种定时器,第一种是setTimeOut,第二种是setInter
-
判断instanceof的结果并解释原因
问题内容: 判断instanceof的结果并解释原因 [代码] 问题答案: 如果函数明确返回值,那么 运算符的结果将是这个值。 如果函数明确返回 non-primitive 值,那么 运算符的结果将是这个值。- 感谢 @xxf1996 指正 所以,原表达式相当于:。 运算符将检测右端值的 属性是否在左端值的原型链( 属性)上; 如果不在,则向上查找( 的 ,…),直到找遍左端值的整个原型链。 注:
-
请详细描述AJAX的工作原理
本文向大家介绍请详细描述AJAX的工作原理相关面试题,主要包含被问及请详细描述AJAX的工作原理时的应答技巧和注意事项,需要的朋友参考一下 AJAX是用于网页和服务器进行异步通信的技术。 基本原理是,通过XMLHttpRequest向服务器发送异步请求,获得服务器返回的数据,利用js更新页面。 其核心功能在于XMLHttpRequest对象。 创建一个ajax的步骤大致可以分为以下几步 创建XHM
-
如何将原生的ajax封装成promise?
本文向大家介绍如何将原生的ajax封装成promise?相关面试题,主要包含被问及如何将原生的ajax封装成promise?时的应答技巧和注意事项,需要的朋友参考一下 参考回答:
-
js事件委托以及冒泡原理?
本文向大家介绍js事件委托以及冒泡原理?相关面试题,主要包含被问及js事件委托以及冒泡原理?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 事件委托是利用冒泡阶段的运行机制来实现的,就是把一个元素响应事件的函数委托到另一个元素,一般是把一组元素的事件委托到他的父元素上,委托的优点是 减少内存消耗,节约效率 动态绑定事件 事件冒泡,就是元素自身的事件被触发后,如果父元素有相同的事件,如onc
-
 11.0 Zookeeper watcher 事件机制原理剖析
11.0 Zookeeper watcher 事件机制原理剖析主要内容:实例zookeeper 的 watcher 机制,可以分为四个过程: 客户端注册 watcher。 服务端处理 watcher。 服务端触发 watcher 事件。 客户端回调 watcher。 其中客户端注册 watcher 有三种方式,调用客户端 API 可以分别通过 getData、exists、getChildren 实现,利用前面章节创建的 maven 工程,新建 WatcherDemo 类
-
 朴素贝叶斯分类算法原理
朴素贝叶斯分类算法原理主要内容:多特征分类问题,朴素贝叶斯算法,朴素贝叶斯优化方法在《 通俗地理解贝叶斯公式(定理)》一节,我们基本认识了“贝叶斯定理”。在此基础之上,这一节我们将深入讲解“朴素贝叶斯算法”。 我们知道解决分类问题时,需要根据他们各自的特征来进行判断,比如区分“一对双胞胎不同之处”,虽然他们看起来相似,但是我们仍然可以根据细微的特征,来区分他们,并准确地叫出他们的名字。就像一句非常有哲理的话,“世界上没有完全相同的两片树叶”,因此被分类的事物会存在许多特征。 比
-
获取错误:WebSphere MQ原因代码2538?
当我搜索这个原因代码时,我明白这是一个主机不可用的错误。 有人能告诉我如何解决这个错误吗? 当我运行命令时,我总是以挂起告终。有人能告诉我如何启动一个听众吗?
-
Spark SQL Join:它的实际工作原理
我未能弄清楚Spark SQL join操作实际上是如何工作的。我读过相当多的解释,但它没有给一些问题带来光明。 例如,您有两个以Spark(parquet或任何其他格式)保存的数据库表。您必须根据一些列加入它们: 我将以的形式启动该查询 null 现在我必须连接大约50对巨大的表,它们中的每一个都应该被分成多个块(子集),比如说5个块。因此,我将获得块之间的筛选和联接操作,而不是
-
spark-cassandra-connector阅读器的工作原理
我有一个关于这个连接器的问题。如果我的Spark集群和Cassandra集群不在同一个集群上,读取如何工作?Spark是否将整个Cassandra表带入自己的集群并将其重新排列到Spark分区中?
-
我对承认的原则感到困惑
版本:2.1.11 问题:我有一些错误的参数配置:max.poll.records:500 max.poll.interval.ms:10000。但消耗大约需要25000秒。因此,它将遇到异常:org.apache.kafka.clients.consumer.CommitFailedException:提交无法完成,因为组已经重新平衡并将分区分配给了另一个成员。这意味着对poll()的后续调用之
-
如何实现Lollipop原料设计标高
对于按钮, 我如何在没有第三方库的情况下模拟Lollipop前版本的提升效果?
-
开移原点 - 配置最大容器数
我最近开始使用openshift,到目前为止看起来很有希望,但是我一直遇到问题,主要是找到过时的文档或查看完全错误的地方。 例如,我目前在几台服务器上安装了大约150个内核的openshift,其中一些节点只有4个内核,而其他节点有48个内核。 我想修改我的所有节点以具有 pods = 1.5 * 核心左右。 这可能吗? 我试图使用: oc编辑节点node0 并将 pod 从默认的 40 更改为