《原型》专题
-
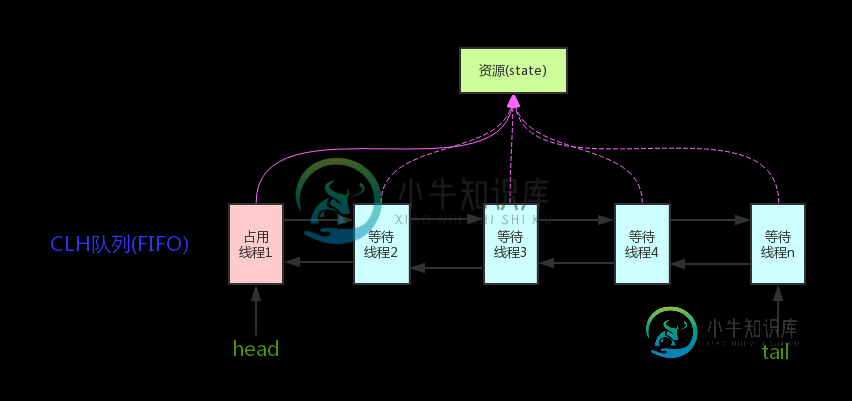 AQS 原理分析 ?
AQS 原理分析 ?本文向大家介绍AQS 原理分析 ?相关面试题,主要包含被问及AQS 原理分析 ?时的应答技巧和注意事项,需要的朋友参考一下 AQS核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制AQS是用CLH队列锁实现的,即将暂时获取不到锁的线程加入到队列中。
-
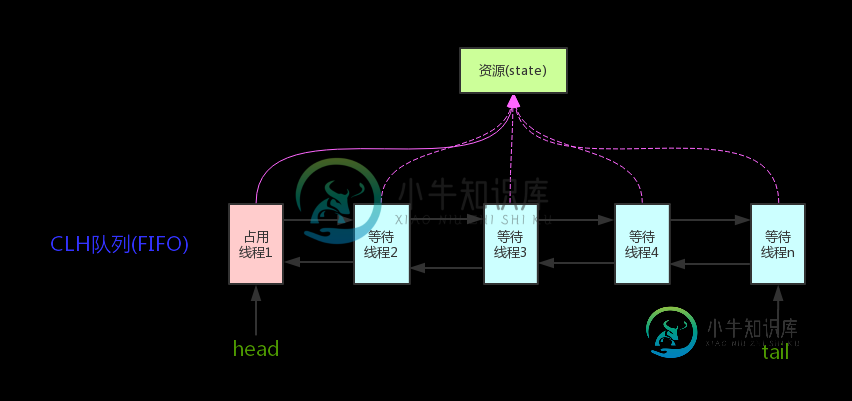 AQS 原理概览
AQS 原理概览本文向大家介绍AQS 原理概览 相关面试题,主要包含被问及AQS 原理概览 时的应答技巧和注意事项,需要的朋友参考一下 AQS核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制AQS是用CLH队列锁实现的,即将暂时获取不到锁的线程加入到队列中。 CL
-
原子编辑器
我试图使用bleikamp的处理包从Atom编辑器运行处理草图。软件包已正确安装,但运行草图会产生以下错误: “处理java”不被识别为内部或外部命令、可操作程序或批处理文件。 我已将处理目录的路径添加到环境变量中。有人能提出为什么这不起作用吗?
-
GraalVM原生映像
我正在尝试用GraalVM创建一个本地映像,我的代码是: 然后我把代码本身称为: 当我运行IDE或java-jar时,它可以正常工作,但当我尝试编译为本机映像时,会抛出一个错误。下面是用于编译本机映像的命令行。 错误: TypeError:invokeMember(打印)在JavaObject[com.compiler.commons.log]上。Console@113a2d320(com.com
-
原理和设计
原理和设计 比特币网络是一个分布式的点对点网络,网络中的矿工通过“挖矿”来完成对交易记录的记账过程,维护网络的正常运行。 比特币通过区块链网络提供一个公共可见的记账本,用来记录发生过的交易的历史信息。 每次发生交易,用户需要将新交易记录写到比特币区块链网络中,等网络确认后即可认为交易完成。每个交易包括一些输入和一些输出,未经使用的交易的输出( Unspent Transaction Outputs
-
ElasticSearch - 架构原理
本书作为 Elastic Stack 指南,关注于 Elasticsearch 在日志和数据分析场景的应用,并不打算对底层的 Lucene 原理或者 Java 编程做详细的介绍,但是 Elasticsearch 层面上的一些架构设计,对我们做性能调优,故障处理,具有非常重要的影响。 所以,作为 ES 部分的起始章节,先从数据流向和分布的层面,介绍一下 ES 的工作原理,以及相关的可控项。各位读者可
-
2.2 设计原则
通用一致的设计,可以减少认知负担带来流畅体验,也可以提升设计及开发效率。 搜索场景下的Web内容页涵盖生活各个方面,服务于大众用户,同时横跨多种系统和不同尺寸的设备,稳定直观的体验根基于通用一致的设计。根据一定的标准持续复用,才能让用户从陌生到熟悉,建立习惯与信任,这需要在界面布局,视觉风格、图标寓意、功能文案,交互逻辑等方面的通用一致体验。 通用一致的界面不仅方便于用户,第三方开发者根据自身需求
-
1.9 设计原则
本章节的设计原则摘录自梁飞在 javaeye 上发表的系列文章。
-
3.7 kube-dns - 原理
如下图所示,kube-dns由三个容器构成: kube-dns:DNS服务的核心组件,主要由KubeDNS和SkyDNS组成 KubeDNS负责监听Service和Endpoint的变化情况,并将相关的信息更新到SkyDNS中 SkyDNS负责DNS解析,监听在10053端口(tcp/udp),同时也监听在10055端口提供metrics kube-dns还监听了8081端口,以供健康检查使用 d
-
3.6 kube-proxy - 原理
kube-proxy监听API server中service和endpoint的变化情况,并通过userspace、iptables、ipvs或winuserspace等proxier来为服务配置负载均衡(仅支持TCP和UDP)。
-
3.3 kube-scheduler - 原理
kube-scheduler调度原理: For given pod: +---------------------------------------------+ | Schedulable nodes: | | | | +--
-
3.2 kube-apiserver - 原理
kube-apiserver提供了Kubernetes的REST API,实现了认证、授权、准入控制等安全校验功能,同时也负责集群状态的存储操作(通过etcd)。
-
2. 核心原理
介绍Kubernetes架构以及核心概念。
-
PrefixSpan算法原理
首先我们看看项集数据和序列数据有什么不同,如下图所示。 左边的数据集就是项集数据,在Apriori和FP Tree算法中我们也已经看到过了,每个项集数据由若干项组成,这些项没有时间上的先后关系。而右边的序列数据则不一样,它是由若干数据项集组成的序列。比如第一个序列<a(abc)(ac)d(cf)>,它由a,abc,ac,d,cf共5个项集数据组成,并且这些项有时间上的先后关系。对于多于一个项的项集
-
Apriori算法原理
什么样的数据才是频繁项集呢?也许你会说,这还不简单,肉眼一扫,一起出现次数多的数据集就是频繁项集吗!的确,这也没有说错,但是有两个问题,第一是当数据量非常大的时候,我们没法直接肉眼发现频繁项集,这催生了关联规则挖掘的算法,比如Apriori, PrefixSpan, CBA。第二是我们缺乏一个频繁项集的标准。比如10条记录,里面A和B同时出现了三次,那么我们能不能说A和B一起构成频繁项集呢?因此我