《贝壳找房》专题
-
前端 - git找不到node?
git commit 后提示 'node' 不是内部或外部命令,也不是可运行的程序 或批处理文件。 husky - pre-commit hook exited with code 1 (error) ,有node而且在命令行正确出来node的,网上什么删除最近的提交等等方法都不行 最后就删除了git,重新创建版本库,就正常了 提交了几次后,又突然提示找不到node了 那就再次删除,后面又重演上面
-
 25届找Java实习 Day03
25届找Java实习 Day03今天基本上Boss上和实习僧没刷到Base地可以投的一些岗位了,华为和阿里有几个岗位没写毕业时间要求,就打了招呼,结果都直接说要求24届。 今天又面了滴滴的另一个事业部,面试官真的是每一个方面的内容都会问几道,从基础、集合、多线程、JVM再到数据库缓存、计算机网络操作系统,最后面试官评价项目这块答的都还不错,但是有些问题还是需要深入去了解一下。最后还给了我很多建议、也聊了聊部门业务以及平时的加班情
-
提供R向量的查找列表作为RODBC查找的SQL表
问题内容: 我在R向量中有一个ID列表。 我想写一个RODBC sqlQuery并附上一个类似这样的子句 我是否必须读取整个表,然后将其合并到R中的idList向量?或者如何将这些值提供给RODBC语句,以便仅恢复我感兴趣的记录? 注意: 由于列表很长,因此无法将单个值粘贴到SQL语句中,如下面的答案所示。 问题答案: 您可以始终使用以下语句构造语句 显然,您需要为此添加更多内容以构造您的确切语句
-
Maven Compile插件找到依赖项,但Maven Javadoc插件没有找到
我试图用生成一个由多个子模块组成的项目的Java-API文档,但它不起作用,而起作用,它解决了所有依赖项,并成功编译<代码>mvn站点既不解析父pom文件(包括easymock)中所有子模块继承的依赖项,也不解析特定于某些子模块(包括SWT)的依赖项。 我获得以下错误消息:[ERROR]未能执行目标org.apache.maven.plugins:maven-site-plugin:3.7.1:站
-
 在Jupyter笔记本中未找到OpenCV,但在终端中找到[duplicate]
在Jupyter笔记本中未找到OpenCV,但在终端中找到[duplicate]我使用“conda-forge”在我的环境中安装了openCV。 它在我的终端工作 我正在使用Python 3.8。2.它显示在我的蟒蛇列表和蟒蛇的环境包列表上。请帮忙。
-
mySQL中“组合”查找表相对于单个查找表的缺点
仅使用一个组合查找表(mySQL数据库)来存储表之间的“链接”比使用单独的查找表有大的缺点(可能在查询速度等方面)吗?我之所以这么问,是因为在我的项目场景中,我最终会得到超过100个单独的查找表,我认为设置和维护这些表将会有很多工作。但为了更简单地举例,这里是一个仅包含4个表的简化场景: 表:教师 表:学生 表:类 表:languageSpoken ========================
-
找不到Java。Android Studio无法找到有效的JVM。(在Mac OS上)
我知道这个top已经有好几个帖子了,但是每个帖子都充斥着不同的方法,现在距离上一个帖子已经有一个月左右的时间了,现在有了Android Studio1.0.1,我想看看有没有人可以帮助我。 当我在安装应用程序并将其移动到我的应用程序文件夹后运行该应用程序时,我会得到以下消息--“Java Not found.Android Studio无法找到有效的JVM。” 我已经尝试了youtube和谷歌,甚
-
找不到MessageSource的ResourceBundle[messages]:找不到基本名称消息的bundle
我有两个问题: 问题1:我的消息文件位于web-inf/i18n目录下。它只包含两个文件:messages_en.properties和messages_hr.properties。 如果我尝试运行上面的代码,我会得到警告:“ResourceBundle[messages]not found for MessageSource:不能find bundle for base name message
-
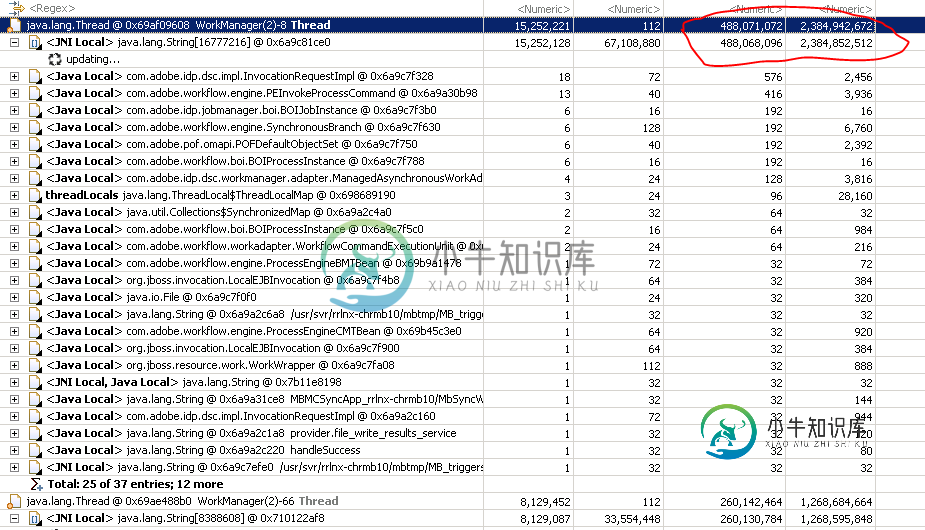 查找java.lang.OutOfMemoryError的根本原因:使用Eclipse MAT查找java堆空间
查找java.lang.OutOfMemoryError的根本原因:使用Eclipse MAT查找java堆空间我试图找出哪个方法/循环在我的应用程序中给了Java . lang . out of memory error:Java堆空间。我对使用Eclipse Memory Analyzer分析java应用程序还很陌生。 在图像中,很明显调用JNI本地具有最大保留堆,但我们的应用程序中没有任何JNI调用。 请检查并确认内存泄漏是由调用任何本机代码(JNI Local)还是使用任何字符串迭代或其他原因引起的
-
在Haskell中使用GNU / Linux系统调用`splice`进行零拷贝Socket到Socket的数据传输
问题内容: 更新:尼莫先生的回答帮助解决了这个问题! 下面的代码包含修复程序!请参见下面的和呼叫。 还有一个称为的新Haskell软件包(具有最著名的套接字到套接字数据传输循环的特定于操作系统的可移植实现) 。 我有以下(Haskell)代码: 注意: 上面的代码现在 可以正常使用! 感谢Nemo,下方不再有效! 我按照上面的定义使用两个开放和连接的套接字进行调用(已经使用套接字API 和调用将它
-
python检测文件夹变化,并拷贝有更新的文件到对应目录的方法
本文向大家介绍python检测文件夹变化,并拷贝有更新的文件到对应目录的方法,包括了python检测文件夹变化,并拷贝有更新的文件到对应目录的方法的使用技巧和注意事项,需要的朋友参考一下 检测文件夹,拷贝有更新的文件到对应目录 2016.5.19 亲测可用,若有借鉴请修改下文件路径; 学习python小一个月后写的这个功能,属于初学,若有大神路过,求代码优化~ newcopy.py: 检测文件夹中
-
使用scikit-learn在朴素贝叶斯分类器中混合分类数据和连续数据
问题内容: 我正在Python中使用scikit-learn开发分类算法,以预测某些客户的性别。除其他外,我想使用Naive Bayes分类器,但是我的问题是我混合使用了分类数据(例如:“在线注册”,“接受电子邮件通知”等)和连续数据(例如:“年龄”,“长度”成员资格”等)。我以前没有使用过scikit,但我想高斯朴素贝叶斯适用于连续数据,而伯努利朴素贝叶斯可以用于分类数据。但是,由于我想在模型中
-
赛贝斯ASE BulkCopy"不支持数据类型或函数"写入非空用户定义类型
我在将从Sql Server迁移到ASE(v16.0)中具有用户定义类型的的列时遇到问题。 我有简单的用户定义类型: 这在一个小表中使用: 我正在尝试使用。源值在SqlServer中定义为。我使用. net客户端进行ASE,我的应用程序代码是C#:
-
朴素贝叶斯算法和非结构化文本 - 非结构化文本的分类算法
在前几个章节中,我们学习了如何使用人们对物品的评价(五星、顶和踩)来进行推荐;还使用了他们的隐式评价——买过什么,点击过什么;我们利用特征来进行分类,如身高、体重、对法案的投票等。这些数据有一个共性——能用表格来展现: 因此这类数据我们称为“结构化数据”——数据集中的每条数据(上表中的一行)由多个特征进行描述(上表中的列)。而非结构化的数据指的是诸如电子邮件文本、推特信息、博客、新闻等。这些数据至
-
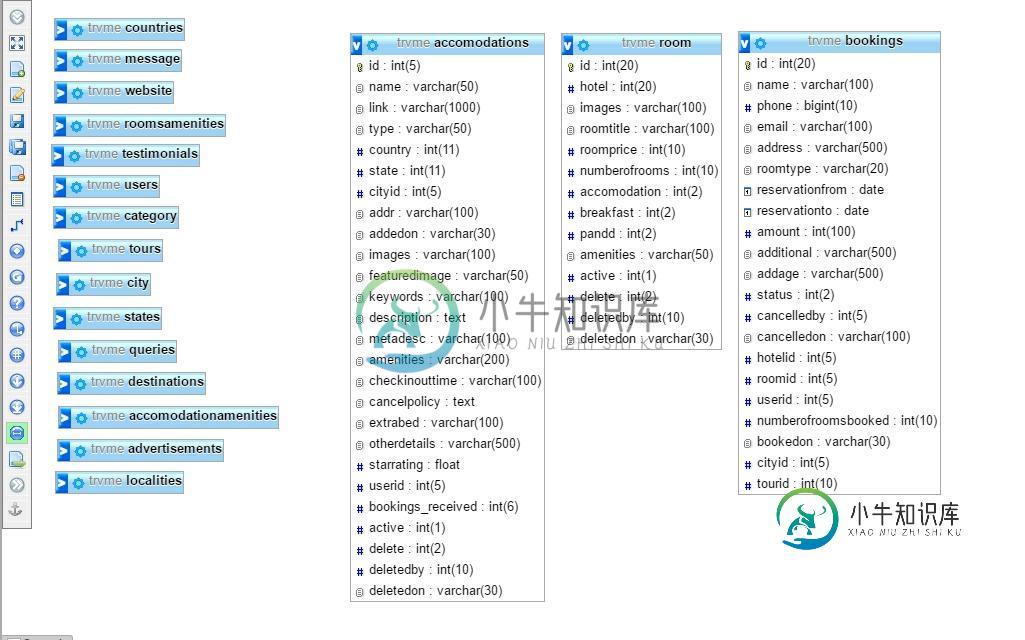 MySQL - 查找在特定日期有空房的酒店
MySQL - 查找在特定日期有空房的酒店我看过很多类似的问题,但还没能让它为我所用。我正在创建一个酒店预订系统,我希望列出在请求的预订日期至少有一个房间可用的酒店。 这是我到目前为止提出的问题 我是MySQL的新手,这真的失控了。这个想法是计算酒店的房间总数,减去给定日期范围内预订的房间总数。我能得到一些帮助吗? 子查询 它自己就能很好地工作,但这个不行。