《就业》专题
-
AWS Glue Crawler将所有数据发送到Glue Catalog和Athena,而无需胶水作业
我刚接触AWS胶水。我正在使用AWS Glue Crawler从两个S3存储桶中抓取数据。我每个桶里有一个文件。AWS Glue Crawler在AWS Glue数据目录中创建了两个表,我还可以在AWS Athena中查询数据。 我的理解是,为了在雅典娜中获取数据,我需要创建粘合作业,这将在雅典娜中提取数据,但我错了。如果说Glue crawler将数据放置在Athena中而不需要Glue job
-
使用Apache Beam笔记本启动数据流作业时处理名称错误
当我运行Google Cloud Platform网站上可用的示例笔记本Dataflow_Word_count.ipynb时,我可以使用Apache Beam笔记本启动数据流作业,并且该作业成功完成。管道的定义如下。 如果我使用一个新函数重构提取单词的部分,如下所示 并运行笔记本我得到以下错误消息: 为了处理名称错误,我按照说明添加了以下行 但是当我运行笔记本时,出现了以下错误 有没有简单的方法来
-
谷歌云数据流:使用DirectPipelineRunner(本地作业)访问管道中的谷歌云发布/订阅?
我已经使用Google云数据流SDK编写了一个流式管道,但我想在本地测试我的管道。我的管道从Google Pub/Sub获取输入数据。 是否可以使用DirectPipelineRunner(本地执行,而不是在Google云中)运行访问发布/订阅(pubsubIO)的作业? 我在以普通用户帐户登录时遇到权限问题。我是项目的所有者,我正在尝试访问发布/子主题。
-
是否可以在本地运行/序列化数据流作业而不具有所有依赖关系?
我已经使用Apache Beam为Google Cloud Dataflow创建了一个管道,但是我不能在本地拥有Python依赖项。但是,远程安装这些依赖项没有问题。 是否可以在本地(开发)环境中运行作业或创建模板而不执行Python代码?
-
Spring批处理作业应用程序挂起与步骤分区
我们的应用程序是使用线程大小为4的spring batch step分区实现的。这意味着我们的步骤在4个线程中读取800万条记录,每个线程读取200万条记录。线程在代码的某个点上,基本上应用程序代码中最后一次调用等待的时间比预期的要长,大约40分钟,而不是5到10分钟。
-
在每个spring批处理作业运行中传递相同的参数
在表中,默认情况下传递和作业参数。当我使用REST endpoint launcher方法触发作业时,我没有看到这些参数在默认情况下被传递。 并且在每个作业运行中传递这两个参数的相同值。和。正如所料,它给出了以下异常。 我的问题是: 当我使用命令行触发作业时,为什么默认情况下传递此和作业参数? ,为什么每次运行作业时传递的两个参数的值都是一样的?即使我正在使用 方法是如何创建差异的?
-
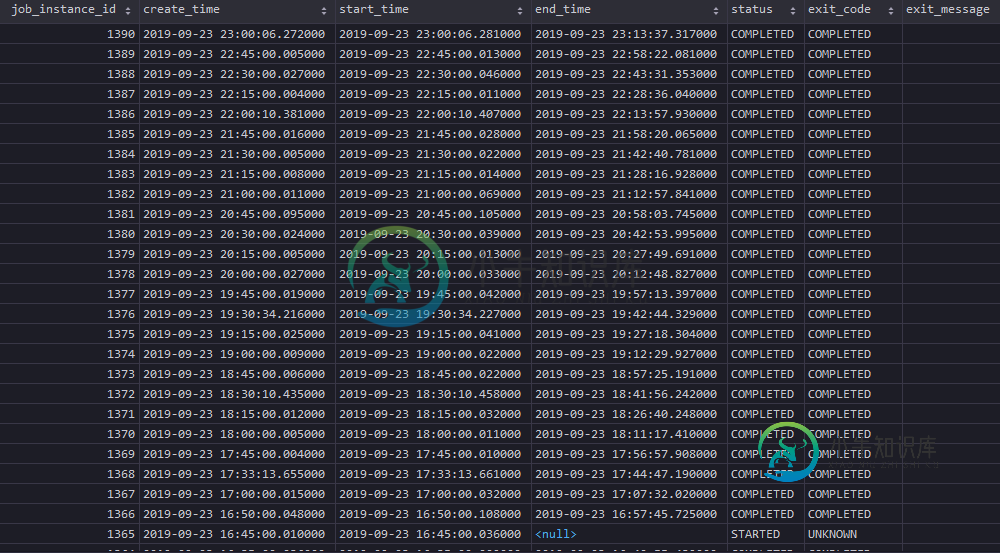 Spring批处理作业调度程序运行几次后停止执行
Spring批处理作业调度程序运行几次后停止执行在一个项目中,我们必须运行一个定期开始的作业(现在QA env上每5分钟开始一次),该作业处理40K用户的一些任务。我们决定使用Spring Batch,因为它非常适合,并且几乎用默认配置实现了它(例如,它使用)。好的,有一个工作由一个步骤组成: 开箱即用 在内存中执行轻量级计算的自定义 自定义,它通过多个JPQL和本机查询将数据保存到同一个PostgreSQL db。 作业本身是用调度的,并且每
-
Spring Batch:终止当前正在运行的作业
在浏览了spring文档之后,在我的代码中。 我面临的问题是,有时工作的终止是发生在预期和其他时间终止工作是不发生的。实际上,每次调用joboperator上的stop时,它都在更新BATCH_JOB_EXECUTION表。当终止成功发生时,作业的状态将通过杀死批处理过程中的jobExecution更新为STOPPED。其他失败的时候,它会完成批处理的其他不同流,并将BATCH_JOB_EXECU
-
如何基于特定批处理作业定义spring批处理云任务
我们目前正在将一个复杂的spring boot batch+admin UI系统迁移到一个spring-cloud-task基础设施中,该基础设施将被管理云数据流。 作为POC的第一阶段,我们必须能够将所有Spring批处理作业打包在同一个部署JAR下,并且能够使用自定义作业参数一个接一个地运行它们,并且支持某种REST API远程执行作业/任务。 我们删除了所有spring-batch管理依赖项
-
如何在服务器停机后恢复spring批处理作业
问题是关于批处理作业的自动恢复策略。表示服务器由于未知原因关闭,当时有几个作业正在运行(状态为“开始”,结束时间为null)。当我们再次启动服务器时,我们如何恢复所有这些作业。 在我的情况下,我编写了自己的作业启动程序来接收请求并将它们保存到DB队列中。然后,我运行自己的作业调度程序轮询来自DB的请求并执行作业。为了将这些作业的状态从“已开始”更改为“已开始”,以便再次被我的计划程序接收,我的当前
-
导致作业退出状态的Spring批处理条件流失败
null 鉴于以下MVE: 执行代码时,“Continue”流运行良好,但“Completed”流总是以失败的作业状态退出。 如何使作业在状态已完成的情况下完成?换句话说,我在流的编码上做错了什么?
-
为什么我的Spring批处理作业在完成后没有退出
-
Camel FTP2消费者与quartz2调度器-如何获得等价的有状态作业?
所以我有我需要的东西(我不认为我需要任何Quartz特定的功能),但是这两个调度器有不同的行为似乎是一个问题。有人知道默认行为应该是什么吗?这里有窃听器吗?
-
Quartz调度器在集群模式下的所有节点上触发cron作业
我有一个应用程序,使用Quartz作为作业调度程序。有两种情况 null > 应用程序的两个实例都将启动并连接到数据库。两者都报告它们已成功群集并连接到数据库。 当我根据场景1调度作业时,在作业执行时,只有一个应用程序执行作业。 场景2,即每10秒执行一次的cron作业,由两个应用程序同时执行。 任何帮助或指导将非常感谢!
-
即使计划时间已过,石英作业仍会激发
我正在使用一个使用Java的Quartz调度器。即使计划的时间已经过了,它也不会抛出调度器异常,而是现在运行作业。例如,我确认了一个作业是10月10日,今天是10月30日,如果我保存信息,它现在就运行作业本身 此外,我还使用JobListener实现手动触发一个作业,以便以后在同一时间点运行其他作业的情况下对其进行调度。 请帮忙。