《同花顺面试》专题
-
火花作业中的Kryo序列化错误
IOException:找不到键类'com.test.serializetest.toto'的序列化程序。如果使用自定义序列化,请确保配置“io.serializations”配置正确。在org.apache.hadoop.io.sequenceFile$writer.init(sequenceFile.java:1179)在org.apache.hadoop.io.sequenceFile$wr
-
OutofMemoryError用更多的阶段将DAG火花化
我有一个运行sql联接的火花作业。 我可视化的DAG和它创建+5阶段的每个加入。无论如何,在DAG有大约40个阶段的阶段之后,下一个步骤总是以异常失败,即在8次迭代之后,每个迭代有5个阶段。 每个节点3个实例(R3.2xLarge)=>12个执行器实例
-
无法从Amazon S3加载雪花外部表
我无法从亚马逊S3桶加载雪花中的外部表。外部表创建成功,但在运行select命令时,不会返回任何内容。奇怪的是COPY into命令对雪花中的同一个表起作用。 谢谢,纳维德
-
从Databricks中加载雪花改变表结构
我正在做一些POC来从Databrics中的dataframe中加载雪花表。我已经成功地加载了表,但是它改变了表的结构。 请注意,主键约束消失了,FNT_DT_PK字段不再为not NULL,最后,每个VARCHAR字段的数据类型长度都更改为16777216。 我在Databricks中的python代码非常简单: 你知道为什么在雪花中改变了表的结构吗?
-
火花2.1.1读/写EMR上的redshift时出错
尝试从/向redshift读/写(s3中的数据)。但在访问数据帧时会出现奇怪的错误。我可以看到正在创建数据帧,并且它能够访问数据,因为它输出表的列名
-
将函数应用于火花数据帧列
并将其应用于数据表的一列--这是我希望这样做的: 我还没有找到任何简单的方法,正在努力找出如何做到这一点。一定有一个更简单的方法,比将数据rame转换为和RDD,然后从RDD中选择行来获得正确的字段,并将函数映射到所有的值,是吗?创建一个SQL表,然后用一个sparkSQL UDF来完成这个任务,这更简洁吗?
-
火花启动-从机未连接到主机
当我尝试使用start-slave.sh连接到主服务器时,spark://master:port如这里所述 我正在得到这个错误日志 我尝试使用本地ip和本地名称访问主服务器(我设法同时使用和不使用密码ssh到主服务器、用户和root用户) 谢了!
-
CRF模型制作花费了太多时间
我遵循这个链接制作一个CRF模型。我使用以下命令制作模型。 模型制作成功,但我的训练数据非常多,花费了太多时间。当我仔细观察系统中发生的事情时。它只使用了我电脑的一个核心 我能否以使用计算机多个核心的方式运行此命令?看起来它是作为单个线程实现的。是否支持多线程?如果是,请分享。
-
火花设备上没有剩余的空间
我有一个EMR作业,它读取大约1TB的数据,过滤它并对它进行重新分区(重新分区后有一些连接),但是我的作业在重新分区时失败,错误为“设备上没有空间”。我很想更改“spark.local.dir”,但没有用。我的工作只在D2.4xLarge实例上完成,但在具有类似内核和RAM的R3.4xLarge实例上失败。我找不到这个问题的根本原因。如有任何帮助,不胜感激。 谢谢你抽出时间。
-
火花窗口聚合vs. Group By/Join性能
与group by/join相比,我对在窗口上运行聚合函数的性能特征感兴趣。在本例中,我对具有自定义帧边界或顺序的窗口函数不感兴趣,而只是作为运行聚合函数的一种方式。 请注意,我只对大小适中的数据量的批处理(非流式)性能感兴趣,因此我禁用了以下广播连接。 例如,假设我们从以下DataFrame开始: 假设我们想要计算每个名称出现的次数,然后为具有匹配名称的行提供该计数。 根据执行计划,窗口化看起来
-
火花2.0.2和2.1.1之间的缓存差异
如何在2.1.1中存档相同的行为? 谢谢你。
-
sbt封装在火花抛出下方错误
我试过在Spark中构建包,它会抛出以下错误。命令:sbt包 hduser@hduser-virtualbox:/usr/local/spark-1.1.0-bin-hadoop1/project$cat>simple.sbt name:=“简单项目” scalaVersion:=“2.9.2” libraryDependencies+=“org.apache.spark”%“spark-core
-
火花:将数据帧写入CSV时出错
我正在尝试使用Databricks的spark-csv2.10依赖关系将一个数据帧写入到HDFS的*.csv文件。依赖关系似乎可以正常工作,因为我可以将.csv文件读入数据帧。但是当我执行写操作时,我会得到以下错误。将头写入文件后会出现异常。 当我将查询更改为时,write工作很好。 有谁能帮我一下吗? 编辑:根据Chandan的请求,这里是的结果
-
无法识别雪花存储过程参数
关于如何使用传递的参数的任何线索。
-
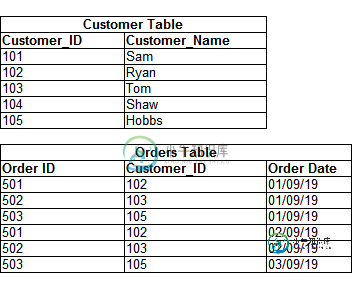 带有日期范围的雪花左联接
带有日期范围的雪花左联接我正在与一个带有日期范围的雪花数据库左联接查询作斗争。请在下面找到样表内容 我的雪花SQL查询:选择o.ORDER_DATE,大小写当ORDER_DATE为NULL时,则“no”否则“yes”结束为ORDER_PLACED,C.customer_id,C.name FROM CUSTOMER C左联接C.customer_id=o.customer_id和o.ORDER_DATE>=DATEADD