《同花顺面试》专题
-
 58同城|测试面试
58同城|测试面试首先,面试官因为记错时间迟到了30分钟,等的我想。。。 然后开始面试,破系统,我换了两台电脑才把系统调好,一开始进去的测试都通过了,结果一进面试间,面试官听不到声音?我请问呢?我换了两台电脑,才勉强可以用。 手撕没撕出来,已经挂了! 把八股说一下! 1.基本的测试理论 2.测试工程师的主要任务 3.测试流程 4.springboot的核心配置文件 5.前端框架了解 6.java的基本数据类型 7.
-
保存为拼花文件在火花java
我是Spark的新手。我尝试在本地模式(windows)下使用spark java将csv文件保存为parquet。我得到了这个错误。 原因:org.apache.spark.Spark异常:写入行时任务失败 我引用了其他线程并禁用了spark推测 set("spark.speculation "," false ") 我还是会出错。我在csv中只使用了两个专栏进行测试。 输入: 我的代码: 请帮
-
在移动版本上以不同顺序引导
问题内容: 我在右列中有2列和嵌套行,如何使Bootstrap响应如下, 布局: 这是我的代码: 使用此代码,移动版本为1 3 2的订单为1 2 3。 问题答案: 因为Bootstrap 4使用的是flexbox,所以 列的高度总是相等的 ,因此您将无法获得所需的桌面(lg)布局。 一种选择 是禁用的flexbox 。使用 浮点数 ,以使1,3列自然向右拉,因为2更高。Flexbox 将在移动设备
-
使用不同的顺序按多个键排序
问题内容: 在Python 3中,使用多个键按字典顺序对对象列表进行排序非常容易。例如: 该参数使您可以指定是升序还是降序。但是,如果要按多个键进行排序,但是要对第一个键使用降序排序,而对第二个键使用升序排序,该怎么办? 例如,假设我们有一个具有两个属性的对象,而,其中an和is是。我们希望通过梳理这些对象的名单在 递减 顺序(使之与点的数量最多的对象是第一位的),但与同等数量的对象,我们要排序这
-
Elasticsearch按分页顺序搜索不同的记录
如何在按分页顺序聚合术语字段后获取记录。到目前为止,我有这个: 我对此进行了研究,有人说,通过使用复合聚合或分区,这是可能的。但我不知道我如何才能真正做到这一点。 我也查看了bucket\u sort,但我似乎无法使其发挥作用: 我对这件事很在行。请帮帮我。谢谢
-
使用两列按不同顺序排序Spark Dataframe
比如说,我有一张这样的桌子: 我想按列的升序排序,但在此范围内,我想按列的降序排序,如下所示: 我曾尝试使用orderBy(“A”,desc(“B”),但它给出了一个错误。 我应该如何在Spark 2.0中使用dataframe编写查询?
-
Java中的同步代码输出顺序错误
我目前正在学习Java,我已经达到同步的主题。 由于某些原因,下面的代码(基于完全参考JAVA-赫伯特·席尔特第七版,第239-240页的代码)没有给出所需的输出。 代码: 所需输出: 实际输出(我在2013年底使用Macbook Pro上的Eclipse): 我已经读到,所有这些主题的输出都因计算机而异。 有人能解释一下为什么这行不通吗?
-
 23秋招-顺丰科技前端二面-面经
23秋招-顺丰科技前端二面-面经时间:9 月 16 日 时长:30 min 左右 base:深圳 并没有问项目相关的,而是从一个八股开始循序渐进,然后 GG。 为什么选择前端?(老生常谈的问题) 输入 URL 到页面显示的过程; TCP 三次握手的过程; 现在有一个 HTML 文件,其中有 13 个 JS 请求,每个 JS 请求耗时 1 s,请问所有的 JS 文件请求完,一共需要多少时间 这里应该分情况讨论,首先确定请求是 HT
-
 顺丰(大数据研发):一面+二面,凉经
顺丰(大数据研发):一面+二面,凉经### 一面 自我介绍+实习经历 (31608)### 二面 1. 自我介绍 2. 实习经历,我说了JVM的重用 3. JVM重用的底层原理 4. sql输出排名前七的学生 5. hive处理小文件的方式 6. hive组件,原理 7. hiveSQL转化为mapreduce的执行过程 8. hive执行过程中的优化 9. 为什么使用环形缓冲区 10. HDFS组件 11. secondnamen
-
 快手java一面已过,许愿二面顺利
快手java一面已过,许愿二面顺利面试官人很好,像个和蔼的大哥,项目拷打20min,接下来是八股,b+树为什么比b树矮,索引用法,优化,mvcc,讲一下可重复读和读已提交如何保证?redis持久化机制,内存淘汰机制,计算机网络tcp的可靠性,八股20min问得很细,算法:锯齿二叉树层次便利,a掉,反问问我如何看待新技术和如何接受语言转,很难以置信,简历golang技术栈,第二天一面给我过了,快手面试体验最好!!!!反观小红书面试一
-
TestNG执行顺序——它混合了来自不同类的测试
TestNG在执行时混合了来自不同类的测试。每节课都有一些测试。而不是像这样执行: > FirstTestClass firstTest 第一次测试第二次测试 第一班第三班 SecondTestClass firstTest 它是这样执行的,混合了来自每个类的测试: FirstTestClass firstTest 这是我的XML: 我所有的测试都设置了优先级参数。但它应该只影响类内的测试,而不是
-
雪花枢轴
-
花纹轮胎
概述 花纹轮胎通常与同步带轮90T一起使用。 参数 材质:硅胶 直径:68.5mm 宽度:22mm 搭建案例
-
 如何基于python实现画不同品种的樱花树
如何基于python实现画不同品种的樱花树本文向大家介绍如何基于python实现画不同品种的樱花树,包括了如何基于python实现画不同品种的樱花树的使用技巧和注意事项,需要的朋友参考一下 这篇文章主要介绍了如何基于python实现画不同品种的樱花树,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 动态生成樱花 效果图(这个是动态的): 实现代码: 飘落效果 效果图: 实现代码: 暗色效
-
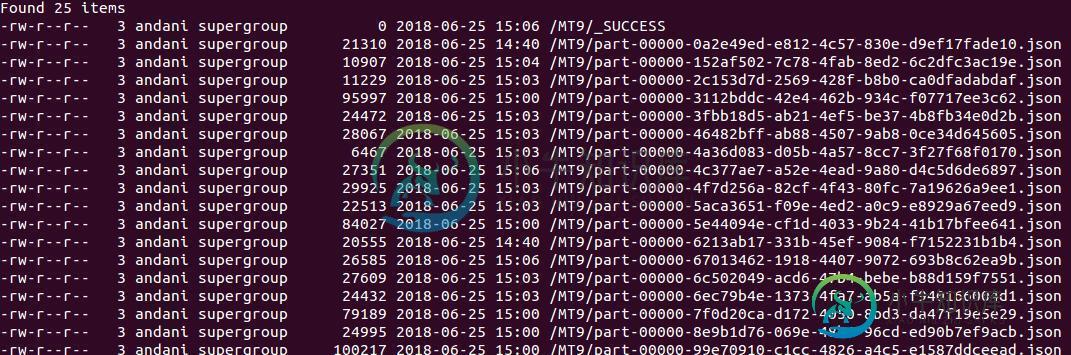 如何在HDFS中附加到相同的文件(火花2.11)
如何在HDFS中附加到相同的文件(火花2.11)我正在尝试使用SparkStreaming将流数据存储到HDFS中,但它会继续在新文件中创建附加到一个文件或几个多个文件中 如果它一直创建n个文件,我觉得效率不会很高 代码 在我的pom中,我使用了各自的依赖项: 火花-core_2.11 火花-sql_2.11 火花-streaming_2.11 火花流-kafka-0-10_2.11