《蚂蚁集团》专题
-
在多个版本的类路径之间进行选择的蚂蚁脚本
我不熟悉蚂蚁脚本。 以下是需求描述 在我的工作区中,有各种各样的项目,我必须在RAD和eclipse IDE以及Websphere、tomcat和jboss环境中进行项目工作。。我已经做了特定于项目的设置,以使项目在RAD、websphere、eclipse和tomcat n jboss上工作。。 但是在一些文件中有一些变化,比如classpath n和一些配置文件。 这就给我留下了三个版本的工作
-
蚂蚁测试:异常在线程"main"java.lang.NoClassDefFoundError: com/beust/j指挥官/参数异常
测试(project-tests.jar): Util(存在于project.jar中): 假设日志已经在两个类中创建并可用。 建筑xml: 目标目录结构: {all-依赖}包括: 当我从IDE运行SampleTest时,它运行正常,但是当我尝试使用ant(ant-v test)运行它时,我遇到了以下错误: 我认为问题在于构建。xml(因为我可以在IDE中运行它),但无法找出这个错误的原因(jav
-
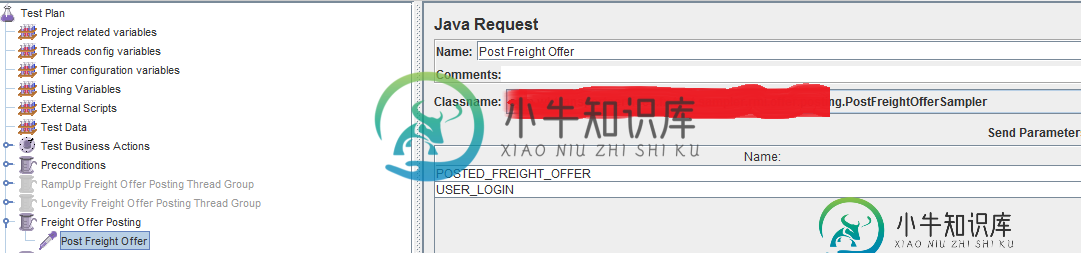 带有Not Gui模式的蚂蚁任务JMeter无法在从节点上运行
带有Not Gui模式的蚂蚁任务JMeter无法在从节点上运行我已根据本手册配置了 JMeter 集群测试 - JMeter 分布式测试分步 两台机器都是CentOS 6,禁用了防火墙,并且具有相同版本的JMeter。 项目是用JMeter的Java示例构建的: 所有的电话都会转到后端。如果要准确,请通过RMI电话。 主节点配置: 更新了与从IP 运行Jenkins工作- JDK 1.7.25 /蚂蚁1 . 9 . 4/JMeter 2.11; 从节点配置:
-
Jenkins Maven项目-无法初始化类组织。阿帕奇。工具。蚂蚁地方
我得到一个错误,因为它无法初始化ANT位置,尽管它是一个Maven项目。 詹金斯的工作。 可以在下面找到输出: [htmlpublisher]正在存档HTML报告。。。[htmlpublisher]项目级别C的存档:\Jenkins\workspace\Capybaras STAGE reg退OnDemand\target\dashboard报告至/home/scmbuildmaster/。jen
-
 5家大厂AIGC:百度/腾讯/科大/商汤蚂蚁AI产品面经汇总
5家大厂AIGC:百度/腾讯/科大/商汤蚂蚁AI产品面经汇总最近有些小伙伴,想要求职AI领域的产品经理,特别是AIGC的产品经理,但是不知道面试官会问哪些问题,也就不知道如何开始准备?该准备哪些东西?要准备到什么程度?最终导致迟迟不敢开始。 下面结合《AIGC产品实战特训营》中自己学生们最近的面试经历,总共5家大厂:百度&腾讯&科大讯飞&商汤&蚂蚁金服,均已拿到offer,面试问题罗列如下,仅供大家参考: 一、科大讯飞AI产品经理面经(已拿offer) 1
-
 蚂蚁金服软件测试工程师一面面试题(附答案)建议收藏
蚂蚁金服软件测试工程师一面面试题(附答案)建议收藏根据面试录音整理,真实有效。 面试时间:2021.4.17。 面试地点:西溪园区。 面试岗位:软件测试工程师。 一:基础部分: 1. 什么是软件测试? 答:软件测试就是发现软件当中存在的缺陷,提高软件的质量。它贯穿于软件工程整个生命周期中,跟开发一样,是一个不可或缺的技术方向。 2. 软件测试过程中会面向哪些群体? 答:如果你是Tester的,一般只与Leader交流就可以了。 如果你是Leade
-
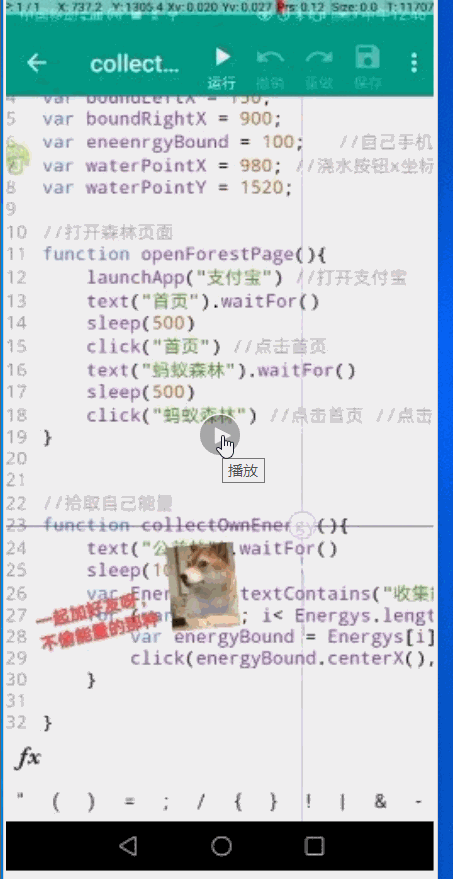 autojs 蚂蚁森林能量自动拾取即给指定好友浇水的实现方法
autojs 蚂蚁森林能量自动拾取即给指定好友浇水的实现方法本文向大家介绍autojs 蚂蚁森林能量自动拾取即给指定好友浇水的实现方法,包括了autojs 蚂蚁森林能量自动拾取即给指定好友浇水的实现方法的使用技巧和注意事项,需要的朋友参考一下 1、简介 定时 实现对蚂蚁森林能量的自动拾取,以及帮指定好友浇水 2、开发环境搭建 语言: javaScript 开发工具:vcCode. auto.js 1)、手机安装 auto.js 我们编写的脚本就是在这个上面
-
蚂蚁:如何在使用“筛选”复制 xml 文件时对属性值进行 xml 转义
这个问题最近出现了。我已经使用蚂蚁很久了,我知道我可以“破解”这个问题,但我想问:蚂蚁是否为这个用例提供了一个优雅的解决方案? 问题 当我使用ant复制xml文件并使用“filtering”属性“填充值”时,我如何才能使它自动转义&符号(以及其他xml“特殊字符”)? 上下文 我们让安装人员/实现人员在应用程序的根目录下编辑一个“build.properties”文件,而不是让他们手动编辑各种应用
-
如何在jenkins上跨多个项目构建作业管理通用的蚂蚁构建脚本?
问题内容: 我有一组Java项目,它们来自不同的git存储库,我想用Jenkins构建它们。 它们都共享相同的ant构建脚本,该脚本通过ant导入机制采用项目特定的配置部分(例如,编译类路径)。 目前,我手动进行此共享,但这在更改公共部分时非常容易出错。 所以我的问题是:在jenkins服务器上跨多个构建作业管理共享的ant构建脚本的好方法是什么? 问题答案: 几个想法… 将Ant脚本存储在您的单
-
TestNG测试套件中的“类”并行在TestNG蚂蚁任务中执行套件时不工作
我设置了Selenium grid2,它与以下并行TestNG测试套件配合得很好: 但是当我在TestNG蚂蚁任务中执行测试时,并行不再工作。 在我将测试套件文件中的并行模式更改为“tests”后,它再次工作,如下所示: 那么,这是否意味着TestNG ant任务不支持“类”并行测试套件?
-
AntSword 中国蚁剑
中国蚁剑是一款开源的跨平台网站管理工具,它主要面向于合法授权的渗透测试安全人员以及进行常规操作的网站管理员。任何人不得将其用于非法用途以及盈利等目的,否则后果自行承担! 设计思想 中国蚁剑采用了Electron作为外壳,ES6作为前端代码编写语言,搭配Babel&&Webpack进行组件化构建编译,外加iconv-lite编码解码模块以及superagent数据发送处理模块还有nedb数据存储模块
-
使用蚂蚁从源代码构建 ANTLR v4 时出现问题 :[java] 错误 (7):找不到或打开文件: *.g
我试图从源代码构建ANTLR版本4,因为我从官方网站下载了它,但我不能使用蚂蚁来做。我下载了antlr-3.5-完全-no-st3.jar作为构建的/lib文件夹.xml说,但是当我运行蚂蚁时,它返回: [mkdir]创建目录:/…/antlr/antlr4-master/build/producated-source/antlr3/org/antlr/v4/parse[java]错误(7):找不
-
模拟退火,蚁群对比
本文向大家介绍模拟退火,蚁群对比相关面试题,主要包含被问及模拟退火,蚁群对比时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 模拟退火算法:退火是一个物理过程,粒子可以从高能状态转换为低能状态,而从低能转换为高能则有一定的随机性,且温度越低越难从低能转换为高能。就是在物体冷却的过程中,物体内部的粒子并不是同时冷却下来的。因为在外围粒子降温的时候,里边的粒子还会将热量传给外围粒子,就可能导致局
-
Spring安全中的多重蚁群
代码似乎工作正常,除了管理部分-它不工作,但返回访问被拒绝异常。
-
如果你现在是蚂蚁花呗的产品负责人,你要怎么做才能把花呗的营业额提升一倍?
本文向大家介绍如果你现在是蚂蚁花呗的产品负责人,你要怎么做才能把花呗的营业额提升一倍?相关面试题,主要包含被问及如果你现在是蚂蚁花呗的产品负责人,你要怎么做才能把花呗的营业额提升一倍?时的应答技巧和注意事项,需要的朋友参考一下 首先,先进行数据分析,分析营业额中用户群体的分布,该用户群体有什么特点,针对不用的用户群体推出不同的方案。 1.对于白领人员,可能对于一些奢侈品,家居服务,租房等等有较高需