《蚂蚁集团》专题
-
 蚂蚁-数据研发-1面2面
蚂蚁-数据研发-1面2面CTO-数据产品与技术部 暑期实习 一面 自我介绍 是保研的吗 实习做了哪些工作 为什么想做数据开发 研究生的方向 本科学过哪些计算机专业课 栈和队列的区别,应用场景 二叉树了解吗, 平衡二叉树了解吗 了解哪些排序算法, 分别说下原理和时间复杂度 快排的最差时间复杂度, 为什么,怎么优化 TCP三次握手, 为什么不是两次 MapReduce运行流程说一下 udf,udaf,udtf区别 spark
-
 蚂蚁 产品经理面经回顾
蚂蚁 产品经理面经回顾内容: 1、自我介绍 2、分别用一句话概括你在这几段实习学到了什么 3、高考为什么选这个专业,出于什么考虑,研究生为什么不换一个专业呢? 4、做过最有价值的项目是什么 5、我看你的经历都是偏数据,但我们招的是产品啊,你最近一段策略产品也是做一些归因分析对吧 6、做的最有价值的一个项目是什么 7、列举一款这两年出现的现象级产品,并从产品、运营、市场等方面进行分析。 8、快手这类app的流行,请从产品
-
 蚂蚁集团-CTO线 数据研发工程师实习 一面(电话面)
蚂蚁集团-CTO线 数据研发工程师实习 一面(电话面)上来先是一道代码题 把字符串按照字符出现频率降序排列后重新输出字符串(HashMap然后排序) 然后开始问一堆问题 看了下项目,没问什么项目的具体内容 实习的内容 讲一下数据库索引 什么时候适用什么时候不适用(最左匹配) 索引创建的原则 Hadoop组成 讲一下MapReduce 讲一下Java中的进程和线程 进程间的通信方式 介绍一下Socket Java的反射 反射的优缺点 SpringBoo
-
如何升级eclipse中内置的蚂蚁?
问题内容: 我在所有构建版本中都使用ANT,并且还将eclipse用作我的IDE,我希望能够在我的eclipse中使用最新版本的ANT,通常eclipse附带的ANT是一个落后的发行版。所以我的问题是。 是否有一种简单的方法来使eclipse ant插件使用最新版本的ANT? 有什么简单的方法可以将额外的自定义ant库添加到内置eclipse ANT插件中,因为我希望能够将诸如subversion
-
蚂蚁需要tools.jar而无法找到它
问题内容: 我将一个Java程序的开发环境放在一起,并且在尝试使用Ant构建脚本进行第一次尝试后,出现了以下错误: 尽管通往jdk的路径是正确的,但tools.jar确实不存在。它实际上应该在那里吗?还是我弄错了一些配置/安装的东西? 问题答案: 它在我的机器上。我在Windows XP SP3上运行Sun JDK 1.6.0_21。 您确定您拥有JDK吗?是否只有JRE?
-
蚂蚁目标失败:Antlib或Ivy问题?
问题内容: 我正在尝试运行以下构建任务(): 运行时,我得到以下输出: 当我转到$ {ANT_HOME} / lib时,看不到任何标有“ antlib * .jar”的JAR。 所以我 猜 我下载了一个不包含Antlib的Ant版本,而现在我使用的是Ivy(使用Antlib),该版本是否令人窒息? 如果这是Antlib的问题,那么我相信我想在这里找到其中一个发行版。如果是这样,有人可以确认我应该使
-
 蚂蚁 区块链研发 电话一面
蚂蚁 区块链研发 电话一面面试官人很好,奈何自己略菜,估计凉了 1.先问了问区块链科研项目内容 2.估算一下自己的代码量 3.介绍区块链的算法内容 4.Pow工作原理 5.PoW的工作量计算细节 6.Kmeans算法,应用场景 7.职业规划 8.在校成绩 可能是自己有点菜😨,面试官问的不多 反问 蚂蚁现在的区块链团队构成 面试应届生对方哪些优势可以是明显加分项 秋招面试这种大厂还是很积累经验的,多学习多进步#秋招##面经
-
 蚂蚁Java开发一二三面挂经
蚂蚁Java开发一二三面挂经一面 电话面 问了好多基础的,从语言最基础的面向对象、范型,到操作系统,到计算机网络,到数据结构,到设计模式。 最后写了一题,就是笔试的第一题,逐渐优化,然后问我为啥笔试只写了20分钟QAQ。 整体上没怎么问Java,好像面试官是刚转Java,更多的是计算机基础,也没问项目,中间也聊了开源经历,发现面试官也有参与过好多开源贡献 面试一个半小时,底裤都被扒光了。 面试体验是很好的,如沐春风的感觉。
-
 测开面经:京东,百度,蚂蚁,360
测开面经:京东,百度,蚂蚁,3608,9月找工作兵荒马乱,最终因为保研放弃了继续找工作,这几天还在陆陆续续收到京东和百度的面试,各种笔试邮件。 今天突然接到蚂蚁的二面电话,还是很有感触的,将之前的面经找出来 还是希望大家不论工作还是读研,都能有一个好的未来 京东初试8.30 数据库:写一个简单的select C++:深拷贝和浅拷贝 操作系统:进程和线程 测试:设计登陆页面的测试用例 代码:用O(n)写一个数组的第K大数 根据二叉树
-
 攒人品,许愿蚂蚁测开三面
攒人品,许愿蚂蚁测开三面二面: 个人背景,项目具体细节 字节和蚂蚁选哪个? 小姐姐大概讲了一些他们的工作概况
-
 蚂蚁网商测开一面面经 3.18
蚂蚁网商测开一面面经 3.18攒人品 面试官很和蔼 全程30+min(有些短因为我技术栈是c++ 问了会不会java) 电脑坏了..所以约的是电话面试 1.自我介绍 2.深挖项目,我第一个项目是自己开园参与的测试 第二个是不太相关的算法设计 3.快排的思路讲一下 复杂度 4.设计一个淘宝搜索的测试用例 从哪些方面思考 5.数据结构了解吗 6.python闭包是什么概念 然后是反问
-
蚂蚁常春藤后检索触发器
我正在尝试解决Ant/Ivy系统中的一些技术债务,我目前的任务之一是解决我们目前的一些检索后行为。默认情况下,我们的构建系统检索Ivy依赖项,然后将压缩工件(tar、tar.bz2、gzip、zip)提取到依赖文件夹,以便我们的项目具有一致的依赖位置: 提取发生在中,因此我们可以受益于一些元数据(路径、名称、类型等),所有这些都以'dep'为前缀。 我们目前有一个属性,可以设置为关闭 ivy.xm
-
蚂蚁-忽略/跳过丢失的目标?
这里我得到,因为不作为目标存在,这是意料之中的。但是有没有什么可以忽略或跳过未知的目标呢?或者将未知目标映射到已知目标(这对我来说是不可行的)? 但是对于旧的分支,还不存在。到目前为止,我们的解决方案是将添加为的依赖项(因为我们的build.xml受版本控制),但这意味着我们不能单独运行。 事后看来,我们应该创建一个代理目标,比如(我们已经对单元测试使用),它将委托给这两个目标。但是,除非对我最初
-
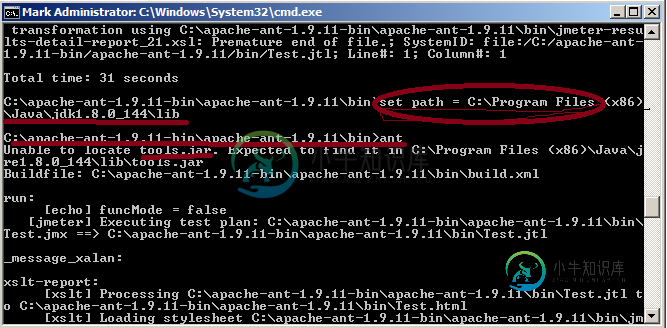 如何使用蚂蚁生成 html 报告
如何使用蚂蚁生成 html 报告我正在尝试使用ant生成html报告,因为我已经执行了以下步骤。在我的机器java和jeter中已经安装。我执行了以下步骤 > < li >下载Apache Ant并将其解压缩。将完整的解压缩文件夹复制到C:\apache-ant-1.9.11-bin < li >打开Jmeter文件夹,然后打开Jmeter文件夹中显示的Extras文件夹:C:\ Apache-Jmeter-4.0 \ Apac
-
 蚂蚁十面面经-大数据开发
蚂蚁十面面经-大数据开发1-4面为春招实习,很遗憾最终没有通过,5-8面为秋招投递同一个部门,hr面后通知说换了一个组加一轮技术面和hr面,总体来讲实习面试更侧重实验室项目,秋招面试会细聊实习工作,每一轮的面试官都很nice,也都是一次很好的学习经历,感恩这一年和蚂蚁的相遇~ 一面(技术面) 介绍项目 遇到了什么问题 怎么解决的 介绍一下大数据的发展历程 项目选型,为什么用这些组件 介绍另一个项目 除了准确率还用了什么指