《开思时代科技》专题
-
 基于NodeJS的前后端分离的思考与实践(一)全栈式开发
基于NodeJS的前后端分离的思考与实践(一)全栈式开发本文向大家介绍基于NodeJS的前后端分离的思考与实践(一)全栈式开发,包括了基于NodeJS的前后端分离的思考与实践(一)全栈式开发的使用技巧和注意事项,需要的朋友参考一下 前言 为了解决传统Web开发模式带来的各种问题,我们进行了许多尝试,但由于前/后端的物理鸿沟,尝试的方案都大同小异。痛定思痛,今天我们重新思考了“前后端”的定义,引入前端同学都熟悉的NodeJS,试图探索一条全新的前后端分离
-
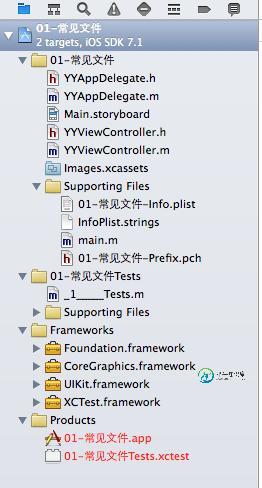 iOS开发中常见的项目文件与MVC结构优化思路解析
iOS开发中常见的项目文件与MVC结构优化思路解析本文向大家介绍iOS开发中常见的项目文件与MVC结构优化思路解析,包括了iOS开发中常见的项目文件与MVC结构优化思路解析的使用技巧和注意事项,需要的朋友参考一下 常见的项目文件介绍 一、项目文件结构示意图 二、文件介绍 1.products文件夹:主要用于mac电脑开发的可执行文件,ios开发用不到这个文件 2.frameworks文件夹主要用来放依赖的框架 3.test文件夹是用来做单元测试的
-
Android Studio的模拟器每隔几秒钟就开始“思考”,不让我调试
我尝试了两个不同的应用程序(其中一个是非常基本的教程,所以代码中没有错误),只是在没有应用程序的情况下使用模拟器,使用两个不同的虚拟设备(Nexus 5X API 27和Nexus S API 22),结果是一样的。 Android Studio版本3.1.2 我怎么才能让这一切不再发生?
-
火灾发生时,什么时候断开连接?
我将Firebase后端用于我的android应用程序。我想为我的聊天建立一个用户状态系统。为此,我采用了Firebase指南中的模式 麻烦的是我不知道什么时候会触发断开连接事件?! 每次我打开应用程序时,我都会将TRUE写入节点“用户/joe/连接”,但是当我关闭应用程序时,不会发生任何事情。当我关闭WIFI时,布尔参数也不会被删除。onDisconnect 事件仅在我强制停止应用程序或重新安装
-
 旷视科技AI产品经理offer|0实习文科人工智能offer
旷视科技AI产品经理offer|0实习文科人工智能offer具体面经 自我介绍 展开讲一下自己满意的一段工作经历? 三款机器人最熟悉的一款机器人? 这款机器人主要解决了什么问题? 送餐机器人是一定程度上替代服务员,目前机器人有什么难题? 你们这个机器人是怎样知道送到哪里的? 那识别地图不会有偏差?通过定位还是距离判断的? 上面的几个项目是怎么回事? 详细说明一下第二个Funny这个项目 场景化的讲一下你这个产品的用户使用过程 产品经理的核心能力 最喜欢的一
-
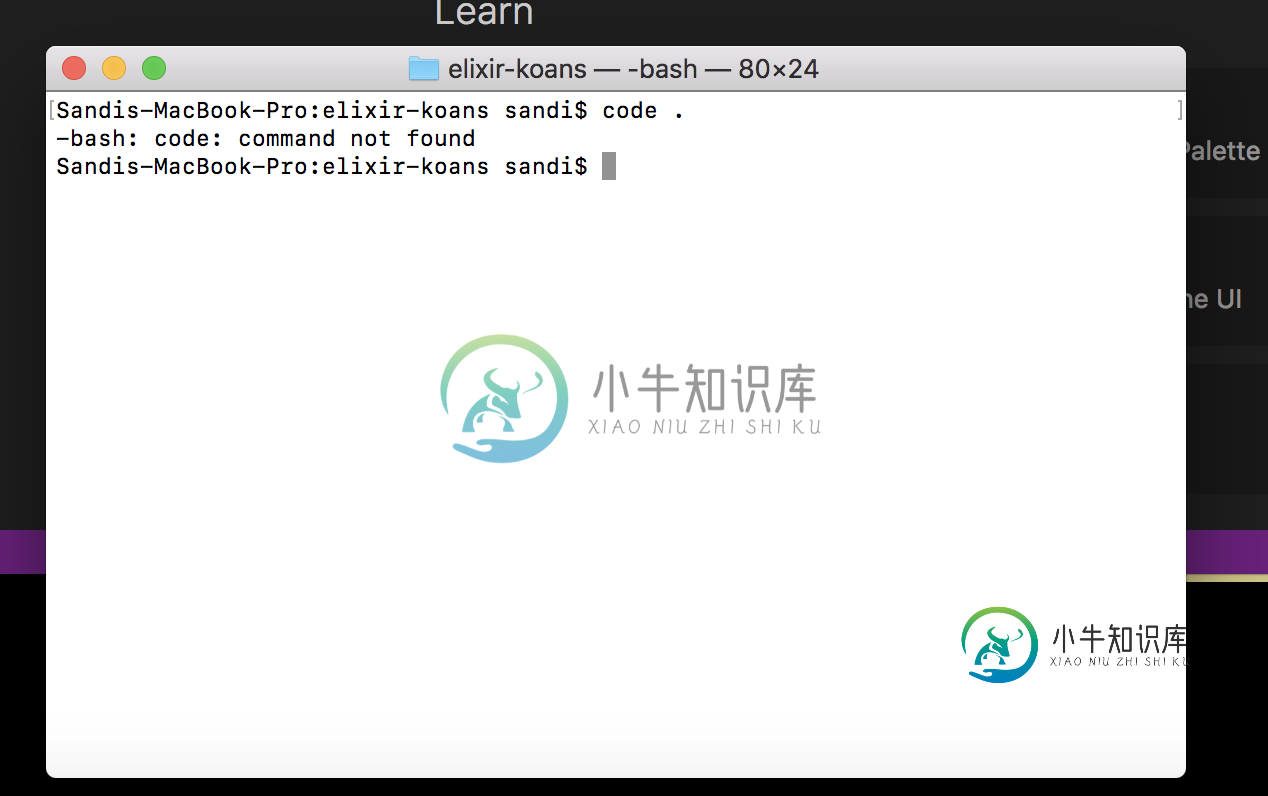 “代码。”命令无法从mac终端打开Visual Studio代码操作符
“代码。”命令无法从mac终端打开Visual Studio代码操作符“代码。”命令不能从mac终端打开Visual Studio代码操作符我不能通过键入“代码”从命令行打开Visual Studio代码编辑器。在终端
-
在区分源代码、目标代码、汇编代码和机器代码时,我感到困惑
我读了我们编写源代码的每一个地方(高级语言),编译器将其转换为机器代码(低级语言)。然后我读到有一个汇编程序,它将汇编代码转换为机器代码。然后在区分编译器和解释器时,我读到编译器首先将整个代码转换为目标代码,而解释器通过跳过目标代码直接转换为机器代码。现在我有困惑,我想到了以下问题: 从汇编代码出来的地方,编译器是否直接将源代码转换为机器代码? 目标代码和机器代码有什么区别? 谁将源代码转换为汇编
-
通过合同设计(DBC)违反了利斯科夫替代原则(LSP)?
现在,让我们来看看“燃料”类: 以上是完成的所有抽象类,现在让我们看看具体的实现。首先,fuel的两个具体实现,包括一些贫血接口,以便我们可以正确地键入-提示/嗅探它们: 最后,我们有了车辆的具体实现,它确保使用正确的燃料类型(接口)为特定的车辆类别加油,如果不兼容则抛出异常: null
-
 学科网 面经
学科网 面经java后台,技术面 项目 项目的二级缓存当时是基于什么情况(遇到什么问题)而这样设计的? redis list怎么用,应用场景? hash和string在存储内存方面,什么情况下一定要用hash,而不是string? mysql设计表时,需要注意什么? 框架 Spring注解核心都有什么? @Autowired和@Resource的区别是? 前者通过byType注入,后者通过byName注入;
-
 科力锐一面
科力锐一面C++岗 主要还是根据和项目问吧 自我介绍, 一些八股linux、计网和项目,还有一些杂七杂八的, 不太好的就是要996吧,普通话不是很好,应该又要寄了,答不出来 #深圳市科力锐科技有限公司#
-
 中科创达Java
中科创达Java# 中科创达()Java(22年9.5) 自我介绍 1.Java的基础数据类型有哪些? 2.string和stringbffer区别与联系 3.什么样的程序叫线程安全,举个例子说线程不安全 4.怎么解决线程不安全的问题? 5.讲一下单例模式? 6.static修饰的变量是否能改变? 7.static放在哪个区间里面的? 8.成员变量和局部变量能否命名一样?(有些不记得:作用域范围不一样) 9.浮点
-
马尔科夫链
1. 马尔科夫链概述 马尔科夫链定义本身比较简单,它假设某一时刻状态转移的概率只依赖于它的前一个状态。举个形象的比喻,假如每天的天气是一个状态的话,那个今天是不是晴天只依赖于昨天的天气,而和前天的天气没有任何关系。当然这么说可能有些武断,但是这样做可以大大简化模型的复杂度,因此马尔科夫链在很多时间序列模型中得到广泛的应用,比如循环神经网络RNN,隐式马尔科夫模型HMM等,当然MCMC也需要它。 如
-
一、数据科学
什么是数据科学 数据科学是通过探索,预测和推断,从大量不同的数据集中得出有用的结论。探索涉及识别信息中的规律。预测涉及使用我们所知道的信息,对我们希望知道的值作出知情的猜测。推断涉及量化我们的确定程度:我们发现的这些规律是否也出现在新的观察中?我们的预测有多准确?我们用于探索的主要工具是可视化和描述性统计,用于预测的是机器学习和优化,用于推理的是统计测试和模型。 统计学是数据科学的核心部分,因为统
-
 Python 科学计算
Python 科学计算Numpy 是 Python 科学工具栈的基础。它的目的很简单:在一个内存块上实现针对多个条目(items)的高效操作。了解它的工作细节有助于有效的使用它的灵活性,使用有用的快捷方式,基于它构建新的工作。
-
 Python 数据科学
Python 数据科学数据是新的石油。该声明显示了如何通过捕获,存储和分析满足各种需求的数据来驱动每个现代IT系统。无论是为商业做出决定,预测天气,研究生物学中的蛋白质结构还是设计营销活动。