-
配置火花应用参数的最佳开端是什么?
我很困惑我应该使用哪种方法来配置火花应用程序参数。 让我们考虑以下集群配置:10个节点、每个节点16个内核和每个节点64GB RAM(例如https://spoddutur.github.io/spark-notes/distribution_of_executors_cores_and_memory_for_spark_application.html0 根据上述建议,让我们为每个执行器分配5个
-
具有配置的资源“attr/tint”的值重复
我已经无法构建可以成功构建的android项目。 构建:同步 ../../.../..gradle/caches/transforms-1/files-1.1/appcompat-v7-27.1.0.aar/079f027781f9663d188d9dd5f4f897cd/res/values/values.xml 错误:配置为“”的资源“attr/tint”的值重复。错误:资源以前定义在这里。
-
Laravel:如何使用透视表从另一个表中检索信息?
问题是我有表格,我想得到它的所有成员。 我创建了一个表透视分组,它从表表单中检索form_id,并从表用户中user_id。但是当我试图检索信息时,我得到了这个:尝试读取bool上的属性“firstname”(视图:/.../资源/视图/分组/list.blade.php) 在我的模型中,我有:窗体: 用户: list.blade.php($表单对应于我之前在所有表单中创建的一个表单):
-
GSON:由于ExclusionStrategy错误,无法编译项目
我接手了一个项目,它不编译。当我构建它时,我得到了以下错误: 已存在的程序类型:com.google.gson.exclusionStrategy 下面是该项目的构建。gradle应用插件:'com.android.application'
-
为什么每个Spark任务都没有利用所有分配的内核?
假设我每个执行器有36个核心,每个节点有一个执行器,以及3个节点,每个节点有48个可用核心。我注意到的基本要点是,当我将每个任务设置为使用1个内核(默认值)时,我对workers的CPU利用率约为70%,每个执行器将同时执行36个任务(正如我所预期的那样)。然而,当我将配置更改为每个任务有6个内核时(conf spark.task.cpus=6),每个执行器一次会减少到6个任务(如预期的那样),但
-
D8MainDexList$MainDexListException
-
在2个字符串之间查找,但最后一个索引应该首先找到C#
大家好,我正在寻找解决方案,以找到文本字符串之间的两个短语,但例如,不是最后一个字符串,但第一次发现。哪里: 因为现在它返回我
-
在单独的机器上运行火花驱动器
目前,我正在群集模式(独立群集)下使用Spark 2.0.0,群集配置如下: 工作线程:使用了4个内核:总共32个,使用了32个内存:总共54.7 GB,使用了42.0 GB 我有4个奴隶(工人)和1台主机。火花盘有三个主要部件-主部件、驱动部件、工作部件(参考) 现在我的问题是,驱动程序正在其中一个工作节点中启动,这阻碍了我在其全部容量(RAM方面)中使用工作节点。例如,如果我在运行spark作
-
Spark内存/工作线程问题
5个节点各有4个内核和32GB内存,其中一个节点(节点4)有8个内核和32GB内存。 所以我总共有6个节点-28个核,192GB RAM。(我想使用一半的内存,但要使用所有的内核) 计划在集群上运行5个spark应用程序。 我的spark\u默认值。配置如下: 我想在每个节点上使用16GB max,并通过设置以下配置在每台机器上运行4个工作实例。所以,我希望(4个实例*6个节点=24个)集群上的工
-
python无法导入docx
我将声明,出于以下原因,我的目标只是写入docx文件 我正在编写一份学习指南,我认为在标签过程中实现一点自动化会更容易 我已经尝试了pip安装python-docx pip安装docx pip卸载python-docx pip卸载docx pi3安装python-docx pi3安装docx虽然我仍然得到一个ModuleNotFoundError错误消息,有人能想到接下来要尝试什么吗? 回溯(最近
-
为什么最后的加值是100?[副本]
当我在javascript中使用运算符时,为什么最后得到的值是100而不是101?我想知道javascript中运算符的详细信息?
-
了解mesos上spark作业的资源分配
我在Spark上从事一个项目,最近从使用Spark Standalone切换到使用Mesos进行集群管理。现在,我发现自己对在新系统下提交作业时如何分配资源感到困惑。 在独立模式下,我使用的是这样的东西(以下是Cloudera博客文章中的一些建议: 这是一个集群,其中每台机器有16个内核和大约32 GB RAM。 这样做的好处是,我可以很好地控制运行的执行器的数量以及分配给每个执行器的资源。在上面
-
如何执行Laravel嵌套查询
我有以下三张桌子 教室 注册学生 iduser_idclass_id 帖子 模型 Classroom.php 注册学生。php 邮递php 现在我需要获得某个班级的所有帖子,学生在该班级注册。 例如,一名学生注册了教室表中id号为1的班级。所以在registered_students表中会注意到,这个特定的用户是在这个特定的类下注册的。每个类在post表中可能有多个post。用户需要获得他类的所有
-
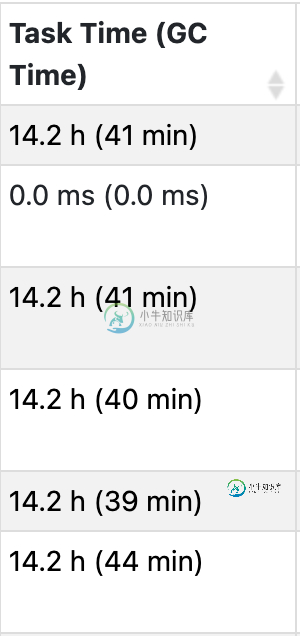 spark executor仪表板中的GC时间
spark executor仪表板中的GC时间在spark executor仪表板页面中, 这有点混乱 任务时间是指在这个执行器中运行的所有任务的总和。它不与内核数量加权。所以我机器中的14.2 / 8 ( 8内核)=1.75h等于执行器的正常运行时间(挂钟) 我想知道,对于前面提到的GC时间,这是执行器中每个线程的总和吗?我是否必须将其除以8才能粗略估计整个遗嘱执行人接受GC的时间? 由于我们使用ParallelGC,我们想知道我的执行器是
-
getBoundingClientRect返回了意外值
对于这些样式,如果我增加宽度,元素将从左侧增长。这意味着getBoundingClientRect()。在我调整宽度后,该元素的右边应该有相同的值。 但是当我使用javascript来增加宽度时,情况就不一样了。为什么不呢? 当鼠标在元素上移动时,我会增加宽度,如下所示: 每次的输出都是不同的。