-
Python:如何阻止多线程的numpy?
问题内容: 我知道这似乎是一个荒谬的问题,但是我必须在与部门中其他人共享的计算服务器上定期运行作业,当我开始10个作业时,我真的希望它只占用10个核心而不是更多; 我不在乎每次运行一个内核所需的时间是否更长:我只是不想让它侵占其他人的领土,这将需要我放弃工作等等。我只想拥有10个坚实的核心,仅此而已。 更具体地说,我在基于Python 2.7.3和numpy 1.6.1的Redhat上使用Enth
-
如何使用Python和Numpy计算r平方?
问题内容: 我正在使用Python和Numpy计算任意次数的最佳拟合多项式。我传递了x值,y值以及要拟合的多项式的阶数(线性,二次等)的列表。 这很有效,但是我还想计算r(相关系数)和r- 平方(确定系数)。我正在将我的结果与Excel的最佳拟合趋势线功能及其计算的r平方值进行比较。使用这个,我知道我正在为线性最佳拟合(度等于1)正确计算r平方。但是,我的函数不适用于度数大于1的多项式。 Exce
-
使用numpy在python中进行向量化空间距离
问题内容: 我在python中有numpy数组,其中包含很多(10k +)3D顶点(坐标为[x,y,z]的向量)。我需要计算这些点所有可能的对之间的距离。 使用scipy很容易: 但是由于引入新依赖项的项目政策,我无法使用它。 所以我想出了这个天真的代码: vert_dist()计算两个顶点之间的3D距离,其余代码仅对1D数组中的顶点进行迭代,并且对于每个顶点,它都计算同一数组中彼此之间的距离并生
-
为某些值构造函数时,python / numpy中的AttributeError
问题内容: 我正在编写Python代码以生成和绘制“超高斯”函数,如下所示: 下面的代码只是作图。由于某种原因,我无法理解,当将默认值8用于或最多13时,此代码可以正常工作。当值为14或更高时,该函数崩溃并显示错误消息: 在函数定义的返回行。有任何想法吗?由于该行中唯一使用.exp的东西是错误消息,似乎暗示它被解释为浮点数,但仅适用于…的较大值。 我正在用numpy 1.7.1和scipy 0.1
-
查找数组中重复元素的索引(Python,NumPy)
问题内容: 假设我有一个整数的NumPy数组,如下所示: 我想找到数组的开始和结束索引,其中值的值大于重复的x倍(例如5倍)。因此,在上述情况下,其值为22和6。重复的22的开始索引为3,结束的索引为8。重复6相同。Python中是否有特殊的工具对您有所帮助?否则,我将遍历数组索引以获取索引,并将实际值与前一个进行比较。 问候。 问题答案: 使用@WarrenWeckesser在此处给出的和方法来
-
numpy数组是通过引用传递的吗?
问题内容: 我遇到了这样一个事实,数组在多个位置通过引用传递,但是然后当我执行以下代码时,为什么和的行为之间有区别 我正在使用python 2.7和numpy版本1.6.1 问题答案: 在Python中,所有变量名都是对values的引用。 当Python评估分配时,右侧的评估先于左侧。创建一个新数组;它不会就地修改。 使局部变量引用此新数组。它不会修改传递给的原始引用的值。变量名称仅绑定到新数组
-
使用SciPy / Numpy在Python中连接稀疏矩阵
问题内容: 使用SciPy / Numpy在Python中连接稀疏矩阵的最有效方法是什么? 在这里,我使用以下内容: 我想在回归中使用两个预测变量,但是当前格式显然不是我想要的格式。是否有可能获得以下信息: 它太大,无法转换为深格式。 问题答案: 您可以使用来连接行数相同的稀疏矩阵(水平串联): 同样,您可以用于将具有相同列数的稀疏矩阵进行串联(垂直串联)。 使用或将创建带有两个稀疏矩阵对象的数组
-
Python 2和3之间的numpy数组的Pickle不兼容
问题内容: 我正在尝试使用此程序加载在Python 3.2中链接到此处的MNIST数据集: 不幸的是,它给了我错误: 然后,我尝试在Python 2.7中解码腌制的文件,然后重新编码。因此,我在Python 2.7中运行了该程序: 它运行无误,因此我在Python 3.2中重新运行了该程序: 但是,它给了我与以前相同的错误。我该如何工作? 这是加载MNIST数据集的更好方法。 问题答案: 这似乎有
-
如何将熊猫系列或索引转换为Numpy数组?
问题内容: 您是否知道如何以NumPy数组或python列表的形式获取DataFrame的索引或列? 问题答案: 要获取NumPy数组,应使用以下属性: 这样可以访问数据的存储方式,因此无需进行转换。 注意:此属性也可用于其他许多熊猫的对象。 要将索引作为列表获取,请致电: 同样,对于列。
-
如何将字符串数组转换为numpy中的浮点数组?
问题内容: 如何转换 至 在NumPy中? 问题答案: 好吧,如果您以列表的形式读取数据,则可以这样做(或等效地,使用列表理解)。(在Python 3,你需要调用的,如果你使用的返回值,因为现在返回一个迭代器)。 但是,如果已经是一串Numpy的字符串,则有更好的方法。使用。
-
线性和分配算法的性能[重复]
问题内容: 由于分配问题可以以单个矩阵的形式提出,我想知道NumPy是否具有解决此类矩阵的功能。到目前为止,我什么都没有找到。也许你们当中的一个知道NumPy / SciPy是否具有分配问题解决功能? 编辑: 同时,我在http://software.clapper.org/munkres/找到了Python(不是NumPy / SciPy)实现。我还是认为NumPy / SciPy的实现会快得多
-
更改给定numpy数组的数据类型
本文向大家介绍更改给定numpy数组的数据类型,包括了更改给定numpy数组的数据类型的使用技巧和注意事项,需要的朋友参考一下 除了python的本机数据类型外,Numpy数组还支持多种数据类型。创建数组后,我们仍然可以根据需要修改数组中元素的数据类型。用于此目的的两种方法是array.dtype和array.astype array.dtype 此方法为我们提供了数组中元素的现有数据类型。在下面
-
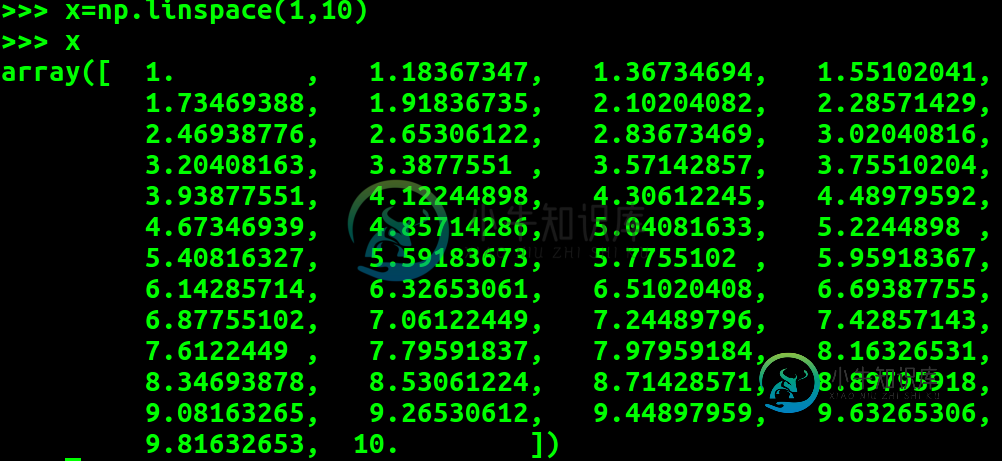 浅谈numpy中linspace的用法 (等差数列创建函数)
浅谈numpy中linspace的用法 (等差数列创建函数)本文向大家介绍浅谈numpy中linspace的用法 (等差数列创建函数),包括了浅谈numpy中linspace的用法 (等差数列创建函数)的使用技巧和注意事项,需要的朋友参考一下 linspace 函数 是创建等差数列的函数, 最好是在 Matlab 语言中见到这个函数的,近期在学习Python 中的 Numpy, 发现也有这个函数,以下给出自己在学习过程中的一些总结。 (1)指定起始点 和
-
错误或功能:使用切片克隆numpy数组
问题内容: 遵循David Morrissey关于“如何在python中克隆列表? ”的回答。‘我正在运行一些性能测试,并在使用numpy数组时遇到意外行为。我知道可以/应该克隆一个numpy数组w / 要么 但是错误地认为切片也可以解决问题。然而: 是否存在这种轻微不一致的充分原因,还是应该提交错误? 问题答案: 在numpy中,切片是原始数组上的引用或“视图”,因此它们不是副本。那是设计使然,
-
将张量转换为Tensorflow中的numpy数组?
问题内容: 将Tensorflow与Python绑定一起使用时,如何将张量转换为numpy数组? 问题答案: 急切执行默认情况下 处于启用状态,因此只需调用Tensor对象即可。 有关更多信息,请参见NumPy兼容性。值得注意的是(来自文档), Numpy数组可以与Tensor对象共享内存。 对一个的任何更改都可能反映在另一个上。 大胆强调我的。副本可以返回也可以不返回,这是基于数据是在CPU还是