
Tensorflow:显示类似行为的损耗和精度曲线

我使用Keras和Tensorflow后端来训练修改的Resnet-50,它将对象分类为15个类别。我使用亚当优化器,我尝试了0.001和0.01的学习率,但得到了类似的结果。
我面临的问题是,损失和准确性都表现出类似的行为(在训练和验证数据集中)。它们都在相似的时间上升或下降,我希望随着损失的减少能得到更高的准确度。是什么导致了这种行为?
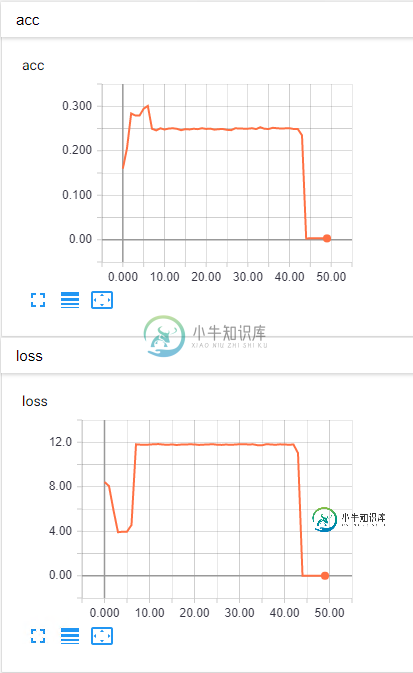
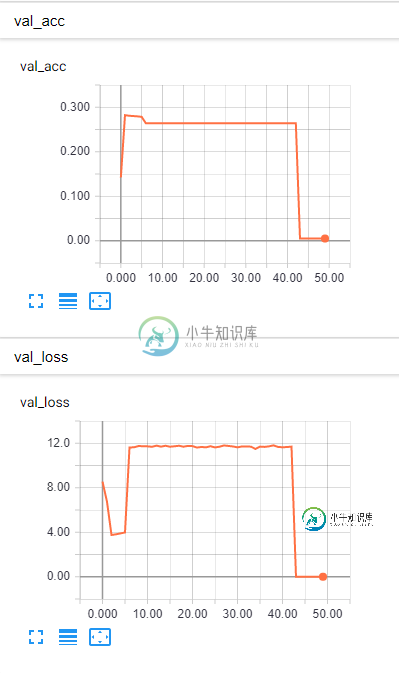
编辑:模型的代码如下所示:
#Model creation:
def create_model(possible_labels):
rn50 = ResNet50(include_top=True, weights=None)
layer_name = rn50.layers[-2].name
model = Model(rn50.input,
Dense(len(possible_labels))(rn50.get_layer(layer_name).output))
adam = Adam(lr=0.0001)
model.compile(loss='categorical_crossentropy',
optimizer=adam, metrics=['accuracy'])
checkpointer = ModelCheckpoint(filepath='the_best_you_ever_had',
verbose=1, save_best_only=True)
tensorboard = TensorBoard()
return model, [checkpointer, tensorboard]
model, checkpointers = create_model(labels)
#Dataset generation:
train_datagen = ImageDataGenerator(
featurewise_center=True,
featurewise_std_normalization=True,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True,
vertical_flip=True,
channel_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2
)
val_datagen = ImageDataGenerator()
train_generator = train_datagen.flow_from_directory(
'data\\train',
target_size=(224, 224),
batch_size=32,
class_mode='categorical'
)
val_generator = val_datagen.flow_from_directory(
'data\\validation',
target_size=(224, 224),
batch_size=32,
class_mode='categorical'
)
#Model training:
model.fit_generator(
train_generator,
steps_per_epoch=5000,
epochs=50,
validation_data=val_generator,
callbacks=checkpointers
)
共有1个答案

我在我的代码中发现了错误,事实上我只是在添加的最后一层中使用默认(线性)激活。通过在代码中执行以下操作,我将其切换为softmax激活(因为这是一个分类问题,而不是回归问题):
model = Model(rn50.input,
Dense(len(possible_labels), activation='softmax')
(rn50.get_layer(layer_name).output))
然后曲线开始按预期运行,我达到了96%的准确率。
-
我的团队正在Tensorflow中训练一个CNN对损坏/可接受部件进行二进制分类。我们通过修改cifar10示例代码来创建我们的代码。在我以前的神经网络经验中,我总是训练到损失非常接近于0(远低于1)。然而,我们现在在训练期间(在一个单独的GPU上)用一个验证集来评估我们的模型,看起来精度在大约6.7K步数后停止增长,而损失在超过40K步数后仍在稳步下降。这是因为过装吗?一旦损失非常接近于零,我们
-
我有一个只有完全连接/密集层的深度网络,形状为128-256-512-1024-1024所有层使用激活,没有,最后一层使用激活。 在第20次训练后,验证/测试损失开始逆转并上升,但测试精度也在继续提高。这怎么说得通?如果显示了新的数据,测试的准确性是否准确,或者是否存在某种假阳性? 我这样编译模型:
-
我正在训练一个张量流DNN模型,它会给出这样的结果, 我可以生成一个数据帧有纪元,损失,准确性,val_accuracy和val_loss? 喜欢
-
我正在学习如何使用Tensorflow,下面的一个示例构建了一个模型来执行方程y=mx c的线性回归。我生成了一个包含1999个样本的csv文件和一个模型,我可以在其中更改规范化(开/关)、层数、节点数和纪元数。我希望能够利用培训和评估的损失/准确性,在我事先不知道答案但对我的结果感到困惑的情况下,指导这些变量的选择,总结如下 规范化层节点时代开始损失结束损失精度 真正的1 200 5 0.602
-
问题陈述: 编写一个方法whatTime,它采用int,seconds,表示从某一天午夜开始的秒数,并返回一个格式为“:”的字符串。此处,表示自午夜以来的完整小时数,表示自上一完整小时结束以来的完整分钟数,以及自上一完整分钟结束以来的秒数。和中的每一个都应该是整数,没有额外的前导0。因此,如果秒为0,则应返回“0:0:0”,而如果秒为3661,则应返回“1:1:1” 我的算法: 以下是我的算法对输
-
问题内容: 我有一个关于精度损失的问题 我的任务是将数字打印为字符串 例如0.2 * 7 = 1.4000000000000001; 0.0000014 / 10 = 1.3999999999999998E-7 如何解决这个问题? UPD :主要问题是 字符串 输出格式。我不担心丢失约0.00000001的值。现在,我将其解析为String.format(“%f”,value),但我认为这不是一个
-
我在Pytorch中用LSTM-线性模块构建了一个分类问题(10个类)的模型。我正在训练模型,对于每个时代,我在训练集中输出损失和准确性。产出如下: 纪元:0开始 损失:2.301875352859497 会计科目:0.1138888889 时代:1开始<损失:2.2759320735931396 会计科目:0.29 时代:2开始<损失:2.2510263919830322 会计科目:0.4872
-
在这里我使用的是基于一维cnn的模型,我不理解模型的学习曲线,因为测试/验证精度曲线是波动的,而总体模型性能大约是70%,相反验证损失只是饱和和波动?我应该如何解释我的结果,我应该考虑什么变化? 我用过亚当优化器。