
Cassandra工具的使用cassandra-应力

我想用1、2、3和4个实例对我的Cassandra集群进行基准测试。所以我在其中一个节点上运行了cassandra应力工具。基准测试显示了奇怪的结果,见下图(--
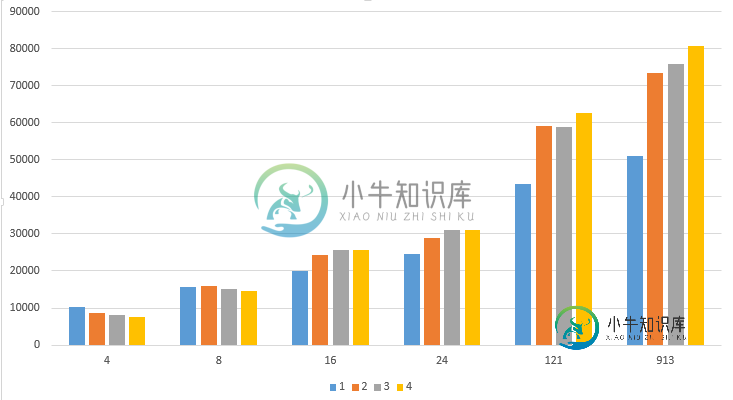
与这个基准网站的结果相比,我的结果似乎不正确。
我现在的问题是:如果在集群的一台机器上运行以下命令,是否正确使用该工具:
cassandra-stress write
我也试过了,但没有任何效果:
cassandra-stress write -node ip1,ip2,...
另见我的另一个问题。非常感谢。
--编辑:Jim的解决方案--
从C*-集群之外的其他EC2实例运行cassandra工具,但在同一LAN中(这样您就可以使用内部IPS10.x.x.x)。我启动了一个1/2/4节点集群,其中包含4个独立的基准调用方节点。他们每个人都收到了以下命令之一:
第一次写作:
cassandra-stress write n=1000000 cl=one -mode native cql3 -schema keyspace="keyspace1" -pop seq=1..1000000 -node ip1,ip2,ip3,ip4
cassandra-stress write n=1000000 cl=one -mode native cql3 -schema keyspace="keyspace1" -pop seq=1000001..2000000 -node ip1,ip2,ip3,ip4
cassandra-stress write n=1000000 cl=one -mode native cql3 -schema keyspace="keyspace1" -pop seq=2000001..3000000 -node ip1,ip2,ip3,ip4
cassandra-stress write n=1000000 cl=one -mode native cql3 -schema keyspace="keyspace1" -pop seq=3000001..4000000 -node ip1,ip2,ip3,ip4
然后用read命令读取这个数据:
cassandra-stress read n=1000000 cl=one -mode native cql3 -schema keyspace="keyspace1" -pop seq=1..1000000 -node ip1,ip2,ip3,ip4
cassandra-stress read n=1000000 cl=one -mode native cql3 -schema keyspace="keyspace1" -pop seq=1000001..2000000 -node ip1,ip2,ip3,ip4
cassandra-stress read n=1000000 cl=one -mode native cql3 -schema keyspace="keyspace1" -pop seq=2000001..3000000 -node ip1,ip2,ip3,ip4
cassandra-stress read n=1000000 cl=one -mode native cql3 -schema keyspace="keyspace1" -pop seq=3000001..4000000 -node ip1,ip2,ip3,ip4
这里是阅读的结果
1 Node cluster: 149,000 ops/sec
2 Node cluster: 348,000 ops/sec
4 Node cluster: 480,000 ops/sec
谢谢你,吉姆!
共有1个答案

如果您只在一个节点上运行cassandra-press,那么我认为这将是预期的结果。一台机器无法使四节点集群饱和,这将是一个瓶颈。
另外,如果您在其中一个cassandra节点上运行cassandra-应力,那么该节点将通过同时运行Cassandra和应力客户端而被双重加载。这将给该机器的CPU和网络连接带来额外的压力。
为了获得集群吞吐量的真实情况,您应该从集群外(但在同一局域网上)的多台计算机上运行压力测试。
-
我想知道是否有可能使用来运行一组预定义的查询而不是随机读取。 例如,假设我有一个带有表的keyspace 此表中的数据是从文件加载的,而不是使用压力工具 现在我想用一组预定义的查询来运行,例如 < code > SELECT * FROM log WHERE log _ severity = " WARN "; 我看到该工具有一个<code>--use prepared语句</code>选项,但我
-
文件中说: |格雷普·卡桑德拉·苏多杀戮 使用:ps auwx | grep cassandra 结果为50行或更多,如何选择正确的数字: /usr/lib/jvm/java-7-openjdk-amd64/bin/java -ea -javaagent:/usr/share/cassandra/lib/jamm-0.2.6.jar -XX: CMSClassUnloadingEnabled -X
-
谁能告诉我为什么火花连接器要花这么多时间插入?我在代码中做了什么错误吗?或者使用spark-cassandra连接器进行插入操作是否不可取?
-
主要内容:消息传递,处理高速应用,产品目录和零售应用程序,社交媒体分析和推荐引擎Cassandra可用于不同类型的应用。 以下是Cassandra应该是推荐的用例列表: 消息传递 Cassandra是一个很好的数据库,可以处理大量的数据。 因此,是提供移动和消息服务的公司是首选。 这些公司有大量的数据,所以Cassandra最适合他们。 处理高速应用 Cassandra可以处理高速数据,因此它是数据来自不同设备或传感器的数据速度非常快的应用程序的绝佳数据库。 产品目录和零售应
-
您好,可以使用LazyDataModel与Cassandra一起在数据表中延迟加载数据。我以前一直在使用Oracle。使用Cassandra时会出现任何问题,并且在“谈论”这个问题时,最好了解延迟加载是如何工作的?每次从一个页面到另一个页面发生更改时都会加载数据吗?还是数据只是加载一次?任何帮助是值得赞赏的。 谢谢
-
我有两台运行Cassandra的不同独立机器,我想将数据从一台机器迁移到另一台机器。 因此,根据数据税文档,我首先在机器1上拍摄了我的Cassandra集群的快照。 然后,我将数据移动到计算机 2,在那里我尝试使用 sstableloader 导入它。 注意:机器2上的keypsace(open_weather)和tablename(raw_weather_data)已创建,并且与机器1上的相同。
-
必须显式设置本地DC(请参阅配置中的basic.load-balancing-policy.local-datacenter,或使用SessionBuilder.WithLocalDatacenter以编程方式设置) 在localhost上运行单节点群集。 能够使用CQLSH查询cassandra键空间。 运行Cassandra版本:3.11.8 使用spring boot版本:2.3.4 cas