
python为什么DFS中append到ans的结果不是预期的独立的列表?

求教做了一道OJ题目,调试发现ans的格式是ans: [[[0, 0], [0, 1], [0, 2], [0, 3]], [[0, 0], [0, 1], [0, 2], [1, 2]]]
为什么明明每次执行dfs的都是同级别的对path的append操作,会产生两个大的list.
和预期的每个都是独立元素的list不一致ans: [[0, 0], [0, 1], [0, 2], [0, 3], [0, 0], [0, 1], [0, 2], [1, 2]] 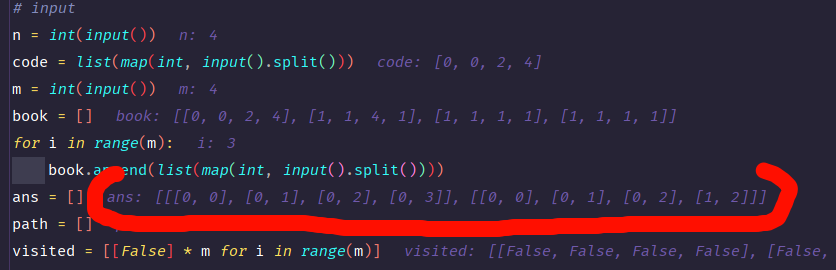
IR = [(0, 1), (1, 0), (0, -1), (-1, 0)]
# input
n = int(input())
code = list(map(int, input().split()))
m = int(input())
book = []
for i in range(m):
book.append(list(map(int, input().split())))
ans = []
path = []
visited = [[False] * m for i in range(m)]
#dfs
def dfs(code, index, path, visited, ans):
if index == len(code):
# ans.append("".join(map(str, path))
ans.append(path[:])
return
for direction in DIR:
x, y = path[-1][0] + direction[0], path[-1][1] + direction[1]
if 0 <= x < m and 0 <= y < m and not visited[x][y] and book[x][y] == code[index]:
path.append([x, y])
visited[x][y] = True
dfs(code, index + 1, path, visited, ans)
path.pop()
visited[x][y] = False
#map track
for i in range(m):
for j in range(m):
if book[i][j] == code[0]:
path.append([i, j])
visited[i][j] = True
dfs(code, 1, path, visited, ans)
path.pop()
visited[i][j] = False
#ans format
if len(ans) == 0:
print("error")
else:
res = []
for i in range(len(ans)):
new_list = []
for j in range(len(ans[i])):
new_list+=ans[i][j]
res.append(new_list)
res.sort()
print(" ".join(str(i) for i in res[0]))因为预期不同 所以改变了format部分 单纯是没想到为什么是这个格式
共有1个答案

ans.append(path[:]) -> ans.extend(path)
append 会把 path[:] 当成一个元素插入进去。extend 会把 path 中的每一个元素分别插入进去。差了一层。
-
问题内容: 为什么评估为无?我预计 问题答案: 这是因为append不返回任何内容(= )。
-
问题内容: 什么是%在计算?我似乎无法弄清楚它的作用。 例如,它算出计算的百分比吗:显然等于0。如何? 问题答案: (取模)运算符从第一个参数除以第二个参数得出余数。首先将数字参数转换为通用类型。右零参数引发ZeroDivisionError异常。参数可以是浮点数,例如3.14%0.7等于0.34(因为3.14等于4 * 0.7 + 0.34。)模运算符始终产生与第二个操作数具有相同符号的结果(或
-
问题内容: 看到这个游乐场:http : //play.golang.org/p/dWku6SPqj5 基本上,我正在使用的库将a作为参数接收,然后需要从字节数组中获取。在幕后,该参数是一个与字节数组的json结构匹配的结构,但该库没有对该结构的引用(但它确实具有对相应的reflect.Type through的引用)。 为什么json包无法检测基础类型?由于某种原因,它会返回一个简单的映射,而不
-
问题内容: 为什么这两个操作(分别)给出不同的结果? 在最后一种情况下,实际上存在无限递归。和一样。为什么与操作不同? 问题答案: 解释“为什么”: 该操作将数组元素添加到原始数组。该操作将数组(或任何对象)插入原始数组的末尾,从而导致对该点的 self引用 (因此无限递归)。 此处的区别在于,通过连接元素来添加数组时,+操作的作用是特定的(与其他数组一样重载,请参见本章的序列)。但是,appen
-
问题内容: 我知道yield将函数转换为生成器,但是yield表达式本身的返回值是多少?例如: 该函数执行时变量的值是什么? 我已经阅读了Python文档:http : //docs.python.org/reference/simple_stmts.html#grammar- token-yield_stmt, 并且似乎没有提及yield表达式本身的值。 问题答案: 您还可以将值赋给生成器。如果
-
问题内容: 我们正在重用一个使用spring java- config(使用@Configuration)定义其bean的项目,并且在一个此类中有一个init方法。 这里的预期行为是什么?何时调用此方法?关于豆子,那就是。即,此方法的行为是否完全像配置类是Bean一样(实际上是一个吗?) 我们观察到的是,根据操作系统的不同,可以在初始化进入配置类的Bean之前调用它,从而最终导致不完全依赖项的工作