
如何检查两个数据集的匹配列之间的相关性?

如果我们有数据集:
import pandas as pd
a = pd.DataFrame({"A":[34,12,78,84,26], "B":[54,87,35,25,82], "C":[56,78,0,14,13], "D":[0,23,72,56,14], "E":[78,12,31,0,34]})
b = pd.DataFrame({"A":[45,24,65,65,65], "B":[45,87,65,52,12], "C":[98,52,32,32,12], "D":[0,23,1,365,53], "E":[24,12,65,3,65]})
如何创建y轴表示“a”,x轴表示“b”的相关矩阵?
目的是查看两个数据集的匹配列之间的相关性,如下所示:
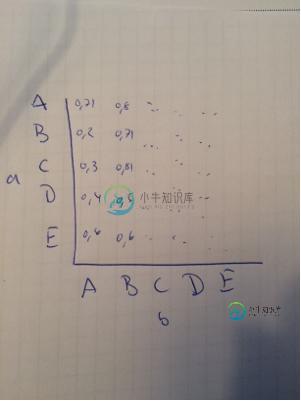
共有3个答案

我用这个函数把它和Numpy分解
def corr_ab(a, b):
a_ = a.values
b_ = b.values
ab = a_.T.dot(b_)
n = len(a)
sums_squared = np.outer(a_.sum(0), b_.sum(0))
stds_squared = np.outer(a_.std(0), b_.std(0))
return pd.DataFrame((ab - sums_squared / n) / stds_squared / n,
a.columns, b.columns)
演示
corr_ab(a, b)

这正是你想要的:
from scipy.stats import pearsonr
# create a new DataFrame where the values for the indices and columns
# align on the diagonals
c = pd.DataFrame(columns = a.columns, index = a.columns)
# since we know set(a.columns) == set(b.columns), we can just iterate
# through the columns in a (although a more robust way would be to iterate
# through the intersection of the two sets of columns, in the case your actual dataframes' columns don't match up
for col in a.columns:
correl_signif = pearsonr(a[col], b[col]) # correlation of those two Series
correl = correl_signif[0] # grab the actual Pearson R value from the tuple from above
c.loc[col, col] = correl # locate the diagonal for that column and assign the correlation coefficient
编辑:嗯,它完全达到了你想要的,直到问题被修改。尽管这很容易改变:
c = pd.DataFrame(columns = a.columns, index = a.columns)
for col in c.columns:
for idx in c.index:
correl_signif = pearsonr(a[col], b[idx])
correl = correl_signif[0]
c.loc[idx, col] = correl
c现在是:
Out[16]:
A B C D E
A 0.713185 -0.592371 -0.970444 0.487752 -0.0740101
B 0.0306753 -0.0705457 0.488012 0.34686 -0.339427
C -0.266264 -0.0198347 0.661107 -0.50872 0.683504
D 0.580956 -0.552312 -0.320539 0.384165 -0.624039
E 0.0165272 0.140005 -0.582389 0.12936 0.286023

如果您不介意基于NumPy的矢量化解决方案,请基于此解决方案将发布到计算两个多维数组之间的相关系数-
corr2_coeff(a.values.T,b.values.T).T # func from linked solution post.
样品运行-
In [621]: a
Out[621]:
A B C D E
0 34 54 56 0 78
1 12 87 78 23 12
2 78 35 0 72 31
3 84 25 14 56 0
4 26 82 13 14 34
In [622]: b
Out[622]:
A B C D E
0 45 45 98 0 24
1 24 87 52 23 12
2 65 65 32 1 65
3 65 52 32 365 3
4 65 12 12 53 65
In [623]: corr2_coeff(a.values.T,b.values.T).T
Out[623]:
array([[ 0.71318502, -0.5923714 , -0.9704441 , 0.48775228, -0.07401011],
[ 0.0306753 , -0.0705457 , 0.48801177, 0.34685977, -0.33942737],
[-0.26626431, -0.01983468, 0.66110713, -0.50872017, 0.68350413],
[ 0.58095645, -0.55231196, -0.32053858, 0.38416478, -0.62403866],
[ 0.01652716, 0.14000468, -0.58238879, 0.12936016, 0.28602349]])
-
我正在寻找一种方法来声明“2个依赖项之间的依赖项”。 例如,在我的模块中,我ivy.xml以下行: 我的问题是,日志经典 1.0.13 依赖于 slf4j-api 1.7.5,而我的模块依赖于 1.6.6(slf4japiversion 的值)。 我无法更改 slf4japiversion,但将来它可以由其他人升级。 有没有办法声明对logback的依赖关系,以检索与我的slf4j api版本兼容
-
假设我有以下几列: 现在我想验证数据是否与列名模式同步。对于,该列中的数据应该仅为。我在引用此链接后尝试了下面的代码,但它在我的代码的最后一行显示错误。 因此,它不接受代码的最后一行。映射{行= 我输入了一条无效记录(第三条),如下所示: 在本例中,我已经为id列输入了一个字符串值(应该是一个数字),因此在检查列架构及其数据后,它应该抛出一个错误,说明记录与列架构不匹配。
-
基本上,它应该在步骤中找到指标为43且步骤=1的行,然后将该值放在新列中,在这种情况下,它将是“Gross value Added”。任何帮助都将非常感谢!
-
问题内容: 在JavaScript中,如果窗口大小大于500px,我要告诉浏览器执行某些操作。我这样做是这样的: 这很好用,但是我想使用相同的方法,但是要有一定范围的数字。因此,如果窗口大小在500像素到600像素之间,我想告诉我的浏览器来做一些事情。我知道这行不通,但是这是我的想象: 在JavaScript中甚至可能吗? 问题答案: 测试是否大于或小于表示值或值本身均不会导致条件变为真。
-
问题内容: 关闭。 这个问题是题外话。它当前不接受答案。 想要改善这个问题吗? 更新问题,使它成为Stack Overflow的主题。 9年前关闭。 改善这个问题 我正在尝试将更改从DatabaseA复制到DatabaseB,但是我不完全知道这些更改是什么。 是否有一个SQL脚本可以找到数据库之间不同的对象,然后生成一个脚本来更新DatabaseB以匹配DatabaseA? 我正在使用SQL 20
-
我有两个具有多列的数据帧。 我想比较df1['id']和df2['id'],并返回一个新的df,其中列['correct_id']具有匹配值。例子: df1: df2 这是我的代码: 我得到的结果是: 预期输出: 我该怎么解决这个问题拜托