
Python,基于几个条件过滤数据帧

我有以下数据框:
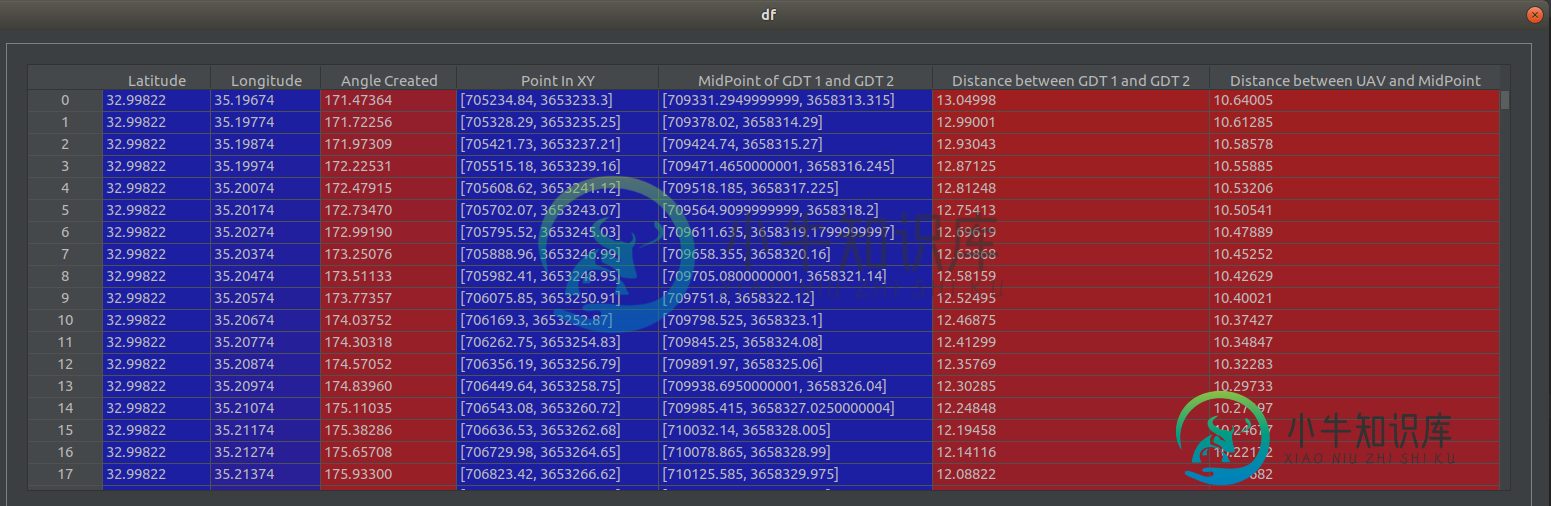
我想根据以下条件对其进行过滤:
创建的角度=范围(87-92)
GDT 1和GDT 2之间的距离
到目前为止我尝试了这个(最后一个方法):
class DataFrameToGeneratedList:
def __init__(self, lat_lon_list=None, lat_list=None, lon_list=None):
if lon_list is None:
lon_list = []
if lat_list is None:
lat_list = []
if lat_lon_list is None:
lat_lon_list = []
self.lat_lon_list = lat_lon_list
self.lat_list = lat_list
self.lon_list = lon_list
# Some unrelated methods here...
def create_points_df(self):
# Convert points list to xy coordinates.
xy_lat_lon_list = [convert_to_xy(l_xy) for l_xy in self.lat_lon_list]
# Midpoint between gdt1 and every point in xy.
midpoints_xy = [get_midpoint(gdt1_xy, point) for point in xy_lat_lon_list]
# Converted midpoints from xy to GeoPoints.
midpoints = [convert_to_lat_lon(xy_point) for xy_point in midpoints_xy]
# Distance from gdt 1 to every point.
distances = [get_distances(gdt1, geo_point) for geo_point in self.lat_lon_list]
# List of angles for every point in lat_lon_list.
angled_list = [angle_between_points(arrayed_gdt1, arrayed_uav, point) for point in xy_lat_lon_list]
# Get distance from uav to every midpoint created.
midpoints_to_uav = [get_distances(uav, midpoint) for midpoint in midpoints]
data_dict = {
'Latitude': self.lat_list,
'Longitude': self.lon_list,
'Angle Created': angled_list,
'Point In XY': xy_lat_lon_list,
'MidPoint of GDT 1 and GDT 2': midpoints_xy,
'Distance between GDT 1 and GDT 2': distances,
'Distance between UAV and MidPoint': midpoints_to_uav
}
unfilterd_df = pd.DataFrame(data_dict)
print(unfilterd_df)
return unfilterd_df
def filter_df_results(self, finished_df):
assert isinstance(finished_df, pd.DataFrame)
finished_df = finished_df
finished_df = (finished_df[(finished_df['Angle Created'] >= 88) & (finished_df['Angle Created'] <= 95) &
(finished_df['Distance between GDT 1 and GDT 2']) >= (
2 * finished_df['Distance between UAV and MidPoint'])])
print(finished_df)
if __name__ == '__main__':
a = DataFrameToGeneratedList()
a.generate_points_list(a.generate_pd())
df = a.create_points_df()
a.filter_df_results(finished_df=df)
此代码的输出是一个没有错误的空数据库。
Empty DataFrame
Columns: [Latitude, Longitude, Angle Created, Point In XY, MidPoint of GDT 1 and GDT 2, Distance between GDT 1 and GDT 2, Distance between UAV and MidPoint]
Index: []
共有1个答案

语法应该看起来像:
finished_df = (
finished_df[
(finished_df['Angle Created'] >= 88) &
(finished_df['Angle Created'] <= 95) &
(finished_df['Distance between GDT 1 and GDT 2'] >= (2 * finished_df['Distance between UAV and MidPoint']))]
)
每个条件都用括号括起来。
可以考虑为单独的条件创建掩码以简化筛选器语句。
-
如果我有一个清单,比如说 我如何才能获得一个名字不同的年龄最大的学生名单?在C#中,使用system.linq GroupBy然后比较,然后用select进行扁平化,这将非常简单,我不太确定如何在Java中实现同样的功能。
-
使用Spark SQL,我有两个数据帧,它们是从一个数据帧创建的,例如: 我想过滤df1,如果它的“路径”的一部分是df2中的任何路径。所以如果df1有路径为“a/b/c/d/e”的行,我会找出df2中是否有路径为“a/b/c”的行。SQL应该是这样 其中udf是用户定义的函数,用于缩短df1的原始路径。简单的解决方案是使用JOIN,然后过滤结果,但这很慢,因为df1和df2都有超过10mil的行
-
基于“SC”代码,我需要将SRCTable与RefTable-1或RefTable-2连接起来 条件:如果SC为“D”,则SRCTable在KEY=KEY1上与RefTable-1连接以获得值。否则,如果SC为“U”,则SRCTable与键=键2上的RefTable-2连接 这是输入spark数据帧。 预期产出: 注意:输入表将有数百万条记录,因此需要一个优化的解决方案
-
我有一个数据集,包含以下各列: 现在,我需要添加一个新的column类,并根据以下条件将其赋值为或: 我只在一个条件下完成了它,但我不知道如何在多个条件下完成它。 这里的wIat我已经尝试过: 我查看了所有其他类似的问题,但找不到解决问题的任何方法。我尝试了上述所有帖子,但仍坚持这个错误:
-
问题内容: 我试图根据多个条件对列表进行排序。 现在,如果我有一个清单,说 我怎样才能得到一个名字不同的最老的学生名单?在C#中,使用System.Linq GroupB进行比较非常简单,然后将其与select进行比较,然后进行展平,我不太确定如何在Java中实现相同的目标。 问题答案: 使用收集器: 说明 我们正在使用以下重载: 上面的函数用于提取映射键的值。 上面的函数用于提取地图值的值,其中
-
问题内容: 谁能向我解释为什么我对这两个表达式会得到不同的结果?我正在尝试在2个日期之间进行过滤: 结果:37M 与 结果:25M 它们有何不同?在我看来,他们应该产生相同的结果 问题答案: TL; DR 要传递多个条件或使用对象和逻辑运算符(,,)。请参见Pyspark:when子句中的多个条件。 您还可以使用 单个 SQL字符串: 实际上,在以下两者之间使用更有意义: 第一种方法甚至不是远程有