
过滤数据的每一列。基于特定值的帧

考虑以下数据帧:
df <- data.frame(replicate(5,sample(1:10,10,rep=TRUE)))
# X1 X2 X3 X4 X5
#1 7 9 8 4 10
#2 2 4 9 4 9
#3 2 7 8 8 6
#4 8 9 6 6 4
#5 5 2 1 4 6
#6 8 2 2 1 7
#7 3 8 6 1 6
#8 3 8 5 9 8
#9 6 2 3 10 7
#10 2 7 4 2 9
使用dplyr,我如何在每一列(不隐式命名)上筛选所有大于2的值。
模拟假设的filter_each(funs(.
现在我正在做:
df %>% filter(X1 >= 2, X2 >= 2, X3 >= 2, X4 >= 2, X5 >= 2)
这相当于:
df %>% filter(!rowSums(. < 2))
注意:假设我只想过滤前4列,我会这样做:
df %>% filter(X1 >= 2, X2 >= 2, X3 >= 2, X4 >= 2)
或
df %>% filter(!rowSums(.[-5] < 2))
还有更有效的替代方案吗?
编辑:子问题
如何指定列名并模拟假设的过滤器(funs(。
基准子问题
由于我必须在大型数据集上运行它,因此我对建议进行了基准测试。
df <- data.frame(replicate(5,sample(1:10,10e6,rep=TRUE)))
mbm <- microbenchmark(
Marat = df %>% filter(!rowSums(.[,!colnames(.) %in% "X5", drop = FALSE] < 2)),
Richard = filter_(df, .dots = lapply(names(df)[names(df) != "X5"], function(x, y) { call(">=", as.name(x), y) }, 2)),
Docendo = df %>% slice(which(!rowSums(select(., -matches("X5")) < 2L))),
times = 50
)
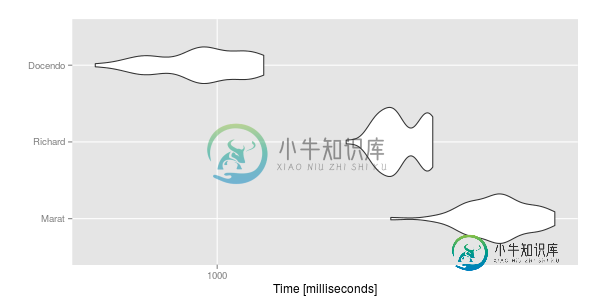
结果如下:
#Unit: milliseconds
# expr min lq mean median uq max neval
# Marat 1209.1235 1320.3233 1358.7994 1362.0590 1390.342 1448.458 50
# Richard 1151.7691 1196.3060 1222.9900 1216.3936 1256.191 1266.669 50
# Docendo 874.0247 933.1399 983.5435 985.3697 1026.901 1053.407 50
共有3个答案

这里有另一个带有切片的选项,在这种情况下可以类似于过滤器。主要区别在于,您为切片提供了一个整数向量,而过滤器则采用逻辑向量。
df %>% slice(which(!rowSums(select(., -matches("X5")) < 2L)))
我喜欢这种方法的地方在于,因为我们在rowSums中使用select,所以您可以使用select提供的所有特殊函数,例如匹配。
让我们看看它与其他答案的比较:
df <- data.frame(replicate(5,sample(1:10,10e6,rep=TRUE)))
mbm <- microbenchmark(
Marat = df %>% filter(!rowSums(.[,!colnames(.) %in% "X5", drop = FALSE] < 2)),
Richard = filter_(df, .dots = lapply(names(df)[names(df) != "X5"], function(x, y) { call(">=", as.name(x), y) }, 2)),
dd_slice = df %>% slice(which(!rowSums(select(., -matches("X5")) < 2L))),
times = 50L,
unit = "relative"
)
#Unit: relative
# expr min lq median uq max neval
# Marat 1.304216 1.290695 1.290127 1.288473 1.290609 50
# Richard 1.139796 1.146942 1.124295 1.159715 1.160689 50
# dd_slice 1.000000 1.000000 1.000000 1.000000 1.000000 50
编辑说明:更新了更可靠的基准,重复50次(次数=50L)。
有人评论说,基R的速度与切片方法相同(没有明确说明基R方法的确切含义),我决定使用与我的答案几乎相同的方法,通过与基R的比较来更新我的答案。对于基准R,我使用:
base = df[!rowSums(df[-5L] < 2L), ],
base_which = df[which(!rowSums(df[-5L] < 2L)), ]
基准:
df <- data.frame(replicate(5,sample(1:10,10e6,rep=TRUE)))
mbm <- microbenchmark(
Marat = df %>% filter(!rowSums(.[,!colnames(.) %in% "X5", drop = FALSE] < 2)),
Richard = filter_(df, .dots = lapply(names(df)[names(df) != "X5"], function(x, y) { call(">=", as.name(x), y) }, 2)),
dd_slice = df %>% slice(which(!rowSums(select(., -matches("X5")) < 2L))),
base = df[!rowSums(df[-5L] < 2L), ],
base_which = df[which(!rowSums(df[-5L] < 2L)), ],
times = 50L,
unit = "relative"
)
#Unit: relative
# expr min lq median uq max neval
# Marat 1.265692 1.279057 1.298513 1.279167 1.203794 50
# Richard 1.124045 1.160075 1.163240 1.169573 1.076267 50
# dd_slice 1.000000 1.000000 1.000000 1.000000 1.000000 50
# base 2.784058 2.769062 2.710305 2.669699 2.576825 50
# base_which 1.458339 1.477679 1.451617 1.419686 1.412090 50
与这两种基本R方法相比,实际上没有任何更好或可比的性能。
编辑注释#2:添加了带有基本R选项的基准。

如何指定列名并模拟假设过滤器(funs(。
这可能不是最优雅的解决方案,但它完成了任务:
df %>% filter(!rowSums(.[,!colnames(.)%in%'X5',drop=F] < 2))
在排除多个列(例如X3、X5)的情况下,可以使用:
df %>% filter(!rowSums(.[,!colnames(.)%in%c('X3','X5'),drop=F] < 2))

这里有一个想法,可以让选择名称变得相当简单。您可以设置一个调用列表,发送到filter_()的. dots参数。首先是一个创建未计算调用的函数。
Call <- function(x, value, fun = ">=") call(fun, as.name(x), value)
现在我们使用filter_(),将调用列表传递到中。点参数,使用lappy(),选择所需的任何名称和值。
nm <- names(df) != "X5"
filter_(df, .dots = lapply(names(df)[nm], Call, 2L))
# X1 X2 X3 X4 X5
# 1 6 5 7 3 1
# 2 8 10 3 6 5
# 3 5 7 10 2 5
# 4 3 4 2 9 9
# 5 8 3 5 6 2
# 6 9 3 4 10 9
# 7 2 9 7 9 8
您可以使用
lapply(names(df)[4:5], Call, 2L)
# [[1]]
# X4 >= 2L
#
# [[2]]
# X5 >= 2L
因此,如果调整lappy()的X参数中的names(),应该可以。
-
使用Spark SQL,我有两个数据帧,它们是从一个数据帧创建的,例如: 我想过滤df1,如果它的“路径”的一部分是df2中的任何路径。所以如果df1有路径为“a/b/c/d/e”的行,我会找出df2中是否有路径为“a/b/c”的行。SQL应该是这样 其中udf是用户定义的函数,用于缩短df1的原始路径。简单的解决方案是使用JOIN,然后过滤结果,但这很慢,因为df1和df2都有超过10mil的行
-
用其他dataframe的列值替换dataframe的一列中的nan值时出现问题。下面是一个测试示例: 我想用其他dataframe中的特定值替换列名中的Nan值(如果其中有一些Nan值,则不是其他列),例如此dataframe中的Name2值: 我想得到的是: 这是此示例的测试代码: 然后我尝试了这三种方法,但都不起作用——我的数据帧始终保持Nan值。 你能告诉我哪里出错了吗?
-
我正面临这个问题,其中我有一个数据帧,比如: 和另一个数据帧: 现在我想要的是,将df2的列插入到df1的特定位置,这样df1就变成了(实际上一个新的df也会起作用): 我现在通过创建一个新的空df来实现这一点,然后迭代这两个df的列,然后依次添加每一列。这是低效的、丑陋的,并且违背了数据流的全部目的。所以我很想知道,这个已经有方法了吗?我不确定这样的问题是否已经在这里得到了回答,但我肯定我没有找
-
我有一个简单的问题: 这将返回如下结果: 但是现在我需要一种计算特定值的方法,这样我就可以返回不同事件类型中存在的许多结果 根据上面的结果,我想返回 有4个结果的event_type值为1等。
-
我每年使用许多场景来预测产品的需求。我有一个多索引的数据帧(模拟、年、月),需要按其中一个进行过滤(比如模拟)。 如何按模拟进行筛选? 仅按模拟编号1进行过滤的预期输出
-
我有一个类似这样的组对象 和如下所示的Item对象