
更改seaborn直方图(或plt)中数据选择条的颜色

假设我有一个数据帧,如:
X2 = np.random.normal(10, 3, 200)
X3 = np.random.normal(34, 2, 200)
a = pd.DataFrame({"X3": X3, "X2":X2})
我正在做下面的绘图程序:
f, axes = plt.subplots(2, 2, gridspec_kw={"height_ratios":(.10, .30)}, figsize = (13, 4))
for i, c in enumerate(a.columns):
sns.boxplot(a[c], ax=axes[0,i])
sns.distplot(a[c], ax = axes[1,i])
axes[1, i].set(yticklabels=[])
axes[1, i].set(xlabel='')
axes[1, i].set(ylabel='')
plt.tight_layout()
plt.show()
这意味着:
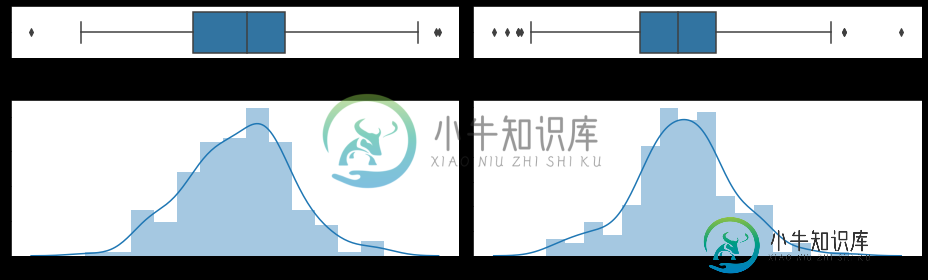
现在,我希望能够在数据帧a上执行数据选择。比如说:
b = a[(a['X2'] <4)]
并在张贴的直方图中突出显示从b中选择的内容。例如,如果对于X3,b的第一行是[32:0],对于X2,b的第一行是[0:5],则期望的输出将是:

使用上述for循环和sns是否可以实现这一点?非常感谢!
编辑:我也很高兴matplotlib解决方案,如果更容易。
编辑2:
如果有帮助,则类似于执行以下操作:
b = a[(a['X3'] >38)]
f, axes = plt.subplots(2, 2, gridspec_kw={"height_ratios":(.10, .30)}, figsize = (13, 4))
for i, c in enumerate(a.columns):
sns.boxplot(a[c], ax=axes[0,i])
sns.distplot(a[c], ax = axes[1,i])
sns.distplot(b[c], ax = axes[1,i])
axes[1, i].set(yticklabels=[])
axes[1, i].set(xlabel='')
axes[1, i].set(ylabel='')
plt.tight_layout()
plt.show()
其结果如下:
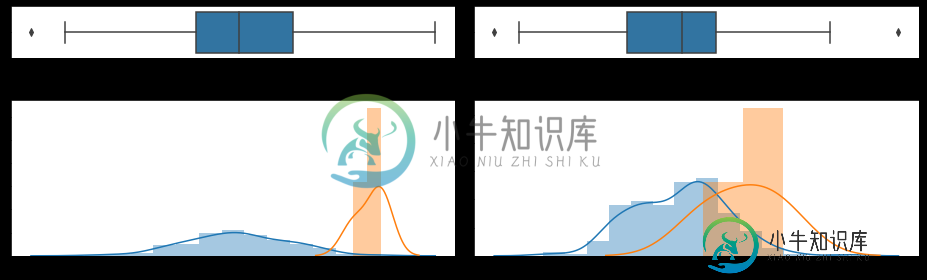
然而,我想能够只是颜色的第一个情节在不同的颜色这些酒吧!我还考虑将ylim设置为蓝色绘图的大小,这样橙色就不会扭曲蓝色分布的形状,但这仍然是不可行的,因为在现实中,我有大约10个直方图要显示,而设置ylim将与sharey=True几乎相同,这是我试图避免的,这样我就能显示出分布的真实形状。
共有2个答案

我想我从前面的答案和这段视频中得到了灵感,找到了解决方案:
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
np.random.seed(2021)
X2 = np.random.normal(10, 3, 200)
X3 = np.random.normal(34, 2, 200)
a = pd.DataFrame({"X3": X3, "X2":X2})
b = a[(a['X3'] < 30)]
hist_idx=[]
for i, c in enumerate(a.columns):
bin_ = np.histogram(a[c], bins=20)[1]
hist = np.where(np.logical_and(bin_<=max(b[c]), bin_>min(b[c])))
hist_idx.append(hist)
f, axes = plt.subplots(2, 2, gridspec_kw={"height_ratios":(.10, .30)}, figsize = (13, 4))
for i, c in enumerate(a.columns):
sns.boxplot(a[c], ax=axes[0,i])
axes[1, i].hist(a[c], bins = 20)
axes[1, i].set(yticklabels=[])
axes[1, i].set(xlabel='')
axes[1, i].set(ylabel='')
for it, index in enumerate(hist_idx):
lenght = len(index[0])
for r in range(lenght):
try:
axes[1, it].patches[index[0][r]-1].set_fc("red")
except:
pass
plt.tight_layout()
plt.show()
对于b=a[(a['X3']
我想我会把它留在这里——虽然利基,可能会在将来帮助别人!

我创建下面的代码是为了理解您的问题的目的是根据在特定条件下提取的数据向直方图添加不同的颜色。使用np。histogram()获取频率数组和存储箱数组。获取与针对特定条件提取的第一行数据的值最接近的值的索引。使用检索到的索引更改直方图的颜色。同样的方法也可用于处理其他图形。
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
np.random.seed(2021)
X2 = np.random.normal(10, 3, 200)
X3 = np.random.normal(34, 2, 200)
a = pd.DataFrame({"X3": X3, "X2":X2})
f, axes = plt.subplots(2, 2, gridspec_kw={"height_ratios":(.10, .30)}, figsize = (13, 4))
for i, c in enumerate(a.columns):
sns.boxplot(a[c], ax=axes[0,i])
sns.distplot(a[c], ax = axes[1,i])
axes[1, i].set(yticklabels=[])
axes[1, i].set(xlabel='')
axes[1, i].set(ylabel='')
b = a[(a['X2'] <4)]
hist3, bins3 = np.histogram(X3)
idx = np.abs(np.asarray(hist3) - b['X3'].head(1).values[0]).argmin()
for k in range(idx):
axes[1,0].get_children()[k].set_color("red")
plt.tight_layout()
plt.show()
-
是否可以动态更改Gnuplot脚本中条的颜色?我有以下脚本 这将生成此绘图: 有没有可能使零度以下的色条变成红色? 谢谢, 斯文
-
我正在用GnuplotPy绘制一些直方图,我想更改直方图条的颜色。(默认情况下,条形图为红色。)这篇StackOverflow文章中的答案给出了几个在普通Gnuplot中如何更改直方图条颜色的选项,但是我还无法让这些解决方案在GnuplotPy中工作。 以下是我使用的基本设置: 上面的代码没有尝试设置直方图条的颜色,它生成了一个带有红色条的直方图: 我尝试了几种方法将直方图条颜色更改为蓝色,但都没
-
问题内容: 在浏览器中选择文本时,大多数情况下选中的文本后面的背景会变为蓝色。如何将这种颜色更改为另一种颜色? 问题答案: 您正在寻找伪元素。 另外,作为旁注。如果你计划在所有使用文本的影子在你的网站,我建议将你的造型。正如你可以看到在这个小提琴,它的眼睛真的很辛苦。
-
我试图显示一个图像的直方图,只显示一些颜色。我已经用JFreeChart和createXYLineChart实现了这一点,并通过遍历所有像素来获取所有数据。 为了加快速度,我尝试用“createhistogram”来完成它。我遵循了这个准则。 为了用新值更新图表,我使用了以下两种方法: setHistogram是一种方法,它根据激活的复选框(布尔红色、绿色和蓝色)返回HistogramDatase
-
我正在使用gnuplot绘制条形图。 问题是:我希望每个酒吧都有不同的颜色。例如:红色的MSA-GA ACO和蓝色的MSA-GA PACO。 我该怎么做呢? 以下是我使用过的命令: “data.dat”:
-
我正在制作一个应用程序,它需要一些数据来制作一个条形图,但条形的颜色必须与它所代表的数据相关。 想象一下我有这种数据:香蕉430水梅隆300 现在我要做一个条形图,我想用黄色颜料画BANANA酒吧,用绿色颜料画WATER MELLON酒吧。我正在使用java中的JFreeChart库。我的研究使我制作了自定义渲染器,但如果我制作自定义渲染器的话,颜色会随机出现在条形图上。有什么解决办法吗?