
panda dataframe可视化数字列的不同存储箱中分类列的不同值的百分比

我有一个pandas数据框架,它有两列col1和class<代码>类是二进制的。我想绘制一个直方图,并可视化col1列的不同容器上class值的百分比。以下是我的尝试:
1-两个直方图,一个用于类列的每个值:
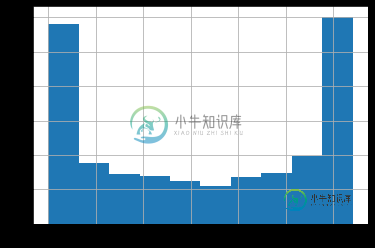
df.col1[df.class == 0].hist()
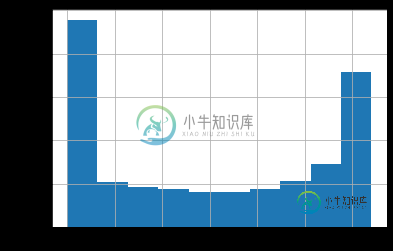
df.col1[df.class == 1].hist()
2-将它们(类的两个值)放在一个图表中
df.groupby('class').col1.hist(alpha=0.9)
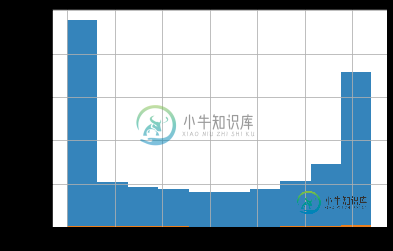
从前两张图中可以看出,那些class==1的行与另一个class==0的行相比是罕见的,当我们把它们放在一起时(第三张图),我们看不到它们的效果(看看图表中那些小的橙色区域)。一种解决方案是使用每个箱子中类的每个值的百分比。我试过这个:
df.groupby('class').col1.transform(lambda x: x/sum(x)).hist(alpha=0.9)

而且显然没有起作用。我正在寻找一种方法来可视化不同箱子中每个类值的百分比。
共有1个答案

由于每个类别的项目数量高度不平衡,因此无法将两个图都放在直方图的相同y轴上,如果两个类别在值之间具有相似的分布,则可以使用distplots对数据执行一些标准化:
uniques = df['class'].unique()
targets = [df.col1[df['class'] == val] for val in uniques]
for target in targets:
sns.distplot(target, rug=True)
-
我从S3读取PARQUET文件时出错,原因是“final_height”列在同一个分区中有String和Double类型。供参考,拼花文件中有20多列。我得到的错误是: 当"part1.gz.parquet"有X列的字符串数据,而"part2.gz.parquet"在同一列中有双精度数据时,找到了一些解决方案。但是当在同一分区中发现同一列中的不同类型时,它们不起作用。 试: 使用合并模式和推断模式
-
问题内容: 我可以在不枚举的情况下计算每列的不同值吗? 说我有一个表,,,并没有其他的列。在没有明确提及这些列的情况下,我希望得到与以下结果相同的结果: 我怎样才能做到这一点 ? 问题答案: 我认为使用普通SQL可以轻松完成的最好工作就是运行这样的查询,以生成所需的查询,然后运行该查询。
-
问题内容: 我进行了很多搜索,但没有找到解决我问题的合适方法。 我要怎么办 我在MySQL中有2个表格:-国家-货币(由于多对多关系,我通过CountryCurrency将它们连接在一起->) 参见以下示例:http : //sqlfiddle.com/#!2/317d3/8/0 我想使用联接将两个表链接在一起,但我想每个国家/地区仅显示一行(某些国家/地区使用多种货币,因此这是第一个问题)。 我
-
问题内容: 我是Oracle的新手。我有一个Oracle表有三列:,和。在第三列中的行具有值,或 。 我想使用count运行查询,以显示可维修的数量,正在维修的数量,针对每个项目类别的谴责数量。 我想运行类似的东西: 我无法在计数内运行内部查询。 这是我希望结果集看起来像的样子: 问题答案: 您可以在COUNT函数中使用CASE或DECODE语句。 输出:
-
本文向大家介绍PHP 不同类型的序列化,包括了PHP 不同类型的序列化的使用技巧和注意事项,需要的朋友参考一下 示例 生成值的可存储表示形式。 这对于存储或传递PHP值而不丢失其类型和结构很有用。 要再次将序列化的字符串转换为PHP值,请使用unserialize()。 序列化字符串 序列化双精度 序列化浮点数 浮点数被序列化为双打。 序列化整数 序列化布尔值 序列化null 序列化数组 序列化对
-
问题内容: 我正在尝试开发一种通用的表加载器,其架构在运行时是已知的。这需要具有包含不同类型的元素的列表,并支持各种get和诸如集方法的类,,。元素我考虑的类型有,,,和,和。每个元素的实际类型在运行时都是已知的,我将它们存储在一个List中,描述其架构以进行进一步处理。 我的问题是:我应该在或中存储这样的元素列表吗?还是有更好的方法来实现此类? 问题答案: 由于您的类的共同祖先是,并且由于不会使