
RQ并发与主管?

总之,我试图“强制”RQ工作人员使用supervisord同时执行。我的setup supervisord设置似乎工作正常,因为rq仪表板显示了3个worker、3个PID和3个队列(每个worker/PID一个)。Supervisord设置如下(仅显示worker 1设置,在此设置下定义了另外两个worker):
[program:rqworker1]
command = rqworker 1
process_name = rqworker1-%(process_num)s
numprocs = 1
user = username
autostart = True
stdout_logfile=/tmp/rqworker1.log
stdout_logfile_maxbytes=50MB
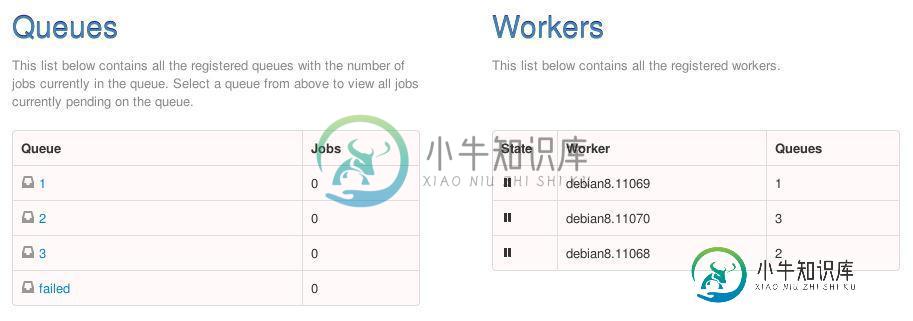
问题是当我同时发送3个作业时,运行的总时间是单个任务的x3(即,总时间与任务数量呈线性关系,这会扩展到x4、x5等...)。似乎没有并发可用。我还通过将新作业发送到具有最少开始排队作业的队列来实现原始负载平衡,这很好(观察到作业在队列中均匀分布)。
为什么这个设置不允许并发?
关于我错过的设置有什么考虑吗?
请注意,当我迁移到PY3时,rq-gevent-Worker包(以前工作得很好w. r. t并发/RQ)不再可用,并且PY3还不支持gevent本身。但这给了我一个线索,即并发是可能的。
共有1个答案

将我的评论从上面修改为答案。。。
使用supervisord并行运行多个rqworker进程是python rq中的一种预期模式,因此不要担心您是在“强制”它。你的想法其实是对的。
另一方面,编写自己的负载平衡算法是一种反模式:这正是python rq为您所做的。
如果您想在三个工作人员之间拆分工作,那么他们都应该监听同一个队列。尝试删除两个主管配置块,并在剩余的一个块中,将numProcs更改为3。如果您将三个作业快速提交到该队列,您应该会看到三个工作人员同时执行。
-
RQ (Redis Queue) 是一个简单的 Python 库用于将作业放到队列中并在后台统一执行,使用 Redis 做后端,可方便的跟 Web 前端集成。 示例代码: import requestsdef count_words_at_url(url): resp = requests.get(url) return len(resp.text.split()) Then, cre
-
Django-RQ 项目实现了 Django 框架和 RQ 消息队列之间的集成。 示例代码: from django_rq import job@jobdef long_running_func(): passlong_running_func.delay() # Enqueue function in "default" queue@job('high')def long_running_
-
RQ Scheduler 是一个小型的 Python 包,用来给 RQ 添加作业调度功能。 安装: pip install rq-scheduler 示例代码: from redis import Redisfrom rq_scheduler import Schedulerfrom datetime import datetimescheduler = Scheduler(connection=
-
我需要一个线程安全的并发列表,同时最适合迭代,并且应该返回精确的大小。我想存储物品的拍卖出价。所以我想能够 检索项目的确切出价数量 为项目添加出价 检索给定项目的所有出价。 移除商品出价 我打算把它放在
-
并发(Concurrently)和并行(Parallel)是两个不同的概念。借用Go创始人Rob Pike的说法,并发不是并行,并发更好。并发是一共要处理(deal with)很多事情,并行是一次可以做(do)多少事情。 举个简单的例子,华罗庚泡茶,必须有烧水、洗杯子、拿茶叶等步骤。现在我们想尽快做完这件事,也就是“一共要处理很多事情”,有很多方法可以实现并发,例如请多个人同时做,这就是并行。并行
-
我想创建一个并发的,它可以处理多个主题,每个主题都有不同数量的分区。 我注意到,对于大多数分区的主题,Spring Kafka每个分区只初始化一个使用者。 示例:我已经将并发设置为8。我得到了一个听以下主题的。主题A有最多的分区-5,所以Spring-Kafka初始化了5个消费者。我期望Spring-Kafka初始化8个消费者,这是根据我的并发属性允许的最大值。 主题A有5个分区 没有初始化更多消