
用Python从电子商务Ajax站点抓取JSON数据

在此之前,我发布了一个关于如何从AJAX网站获取数据的问题,该网站来自以下链接:使用python抓取AJAX电子商务网站
我对如何使用chrome F12 in Network选项卡获得响应有点了解,并使用python进行一些编码以显示数据。但我几乎找不到它的特定API url。JSON数据不像以前的网站那样来自URL,但它位于Chrome F12中的Inspect元素中。
>
还有一个问题是,在我运行代码几次之后,JSON数据丢失了。我想网站会屏蔽我的IP地址。我如何解决这个问题?
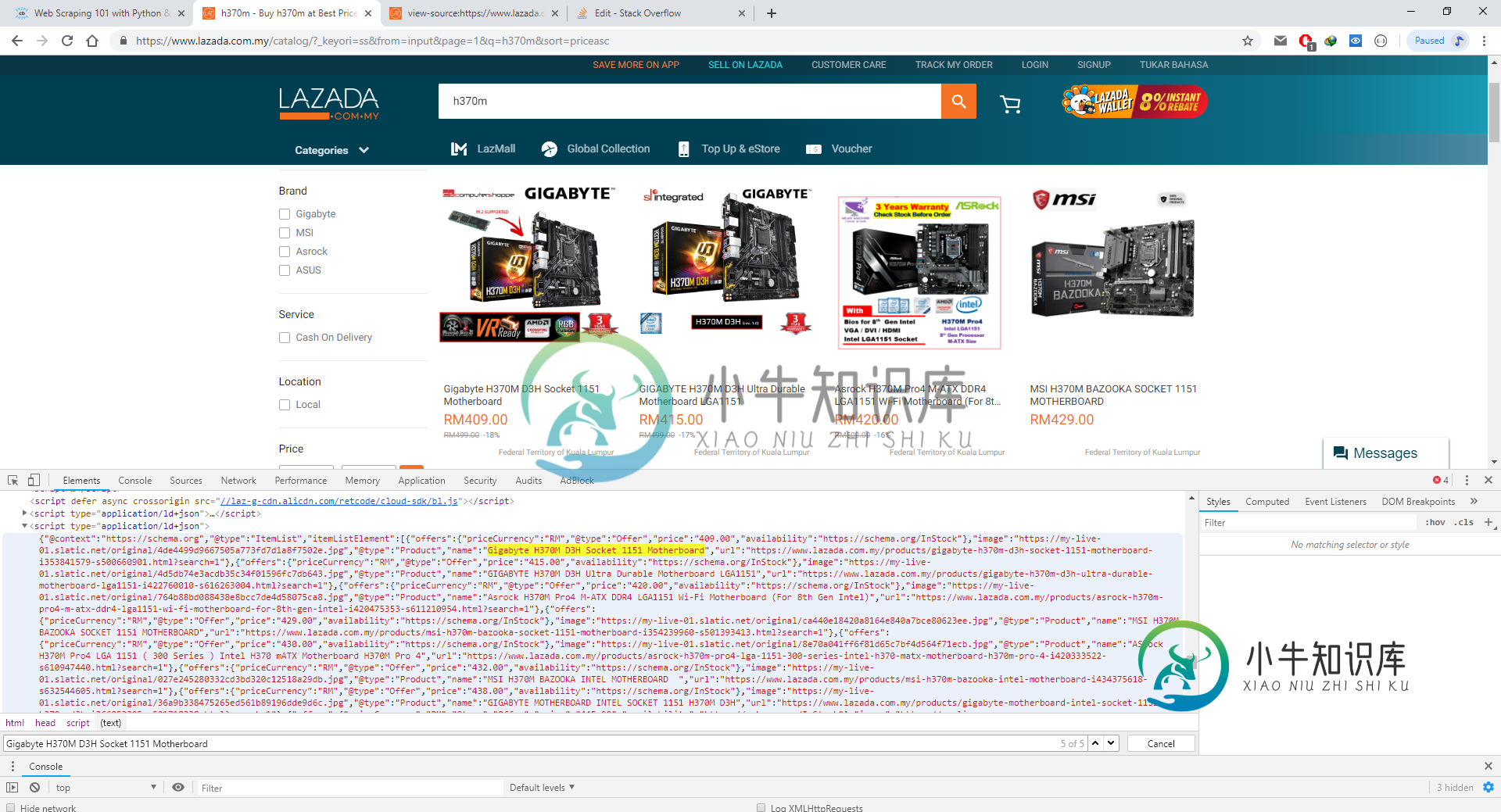
以下是网站链接:
https://www.lazada.com.my/catalog/?_keyori=ss
这是我的密码
从bs4导入组导入请求
页面链接https://www.lazada.com.my/catalog/?_keyori=ss
page_response=requests.get(page_link,超时=5)
page\u content=BeautifulSoup(page\u response.content,“html.parser”)
打印(第页内容)
共有3个答案

尝试:
import requests
response = requests.get(url)
data = response.json()

您必须从Soup手动解析HTML中的数据,因为其他网站将从其他方限制其json API。
你可以在这里找到更多的细节留档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/

您只需使用find方法,将指针指向您的
然后可以使用json包在dict中加载值
下面是一个代码示例:
from bs4 import BeautifulSoup as soup
import requests
import json
page_link = 'https://www.lazada.com.my/catalog/?_keyori=ss&from=input&page=1&q=h370m&sort=priceasc'
page_response = requests.get(page_link, timeout=5)
page_content = soup(page_response.text, "html.parser")
json_tag = page_content.find('script',{'type':'application/json'})
json_text = json_tag.get_text()
json_dict = json.loads(json_text)
print(json_dict)
编辑:我的错,我没有看到您搜索type=application/ld jsonattr,因为它似乎有几个
from bs4 import BeautifulSoup as soup
import requests
import json
page_link = 'https://www.lazada.com.my/catalog/?_keyori=ss&from=input&page=1&q=h370m&sort=priceasc'
page_response = requests.get(page_link, timeout=5)
page_content = soup(page_response.text, "html.parser")
json_tags = page_content.find_all('script',{'type':'application/ld+json'})
for jtag in json_tags:
json_text = jtag.get_text()
json_dict = json.loads(json_text)
print(json_dict)
-
问题内容: 我无法在Shopee(电子商务网站)上拉低产品的价格。 我看了@dmitrybelyakov解决的问题)。 该解决方案帮助我获得了产品的“名称”和“ historical_sold”,但我无法获得产品的价格。我在Json字符串中找不到价格值。因此,我尝试使用Selenium通过xpath提取数据,但似乎失败了。 电子商务网站的链接:https : //shopee.com.my/sea
-
我正在考虑建立一个电子商务网站,并想知道支付方面的事情。 经过一些搜索,我看到了Stripe,它似乎非常类似于贝宝和谷歌结账。 我有几个关于Stripe和电子商务的问题。 Stripe的优势/劣势是什么,有没有我应该了解的竞争对手? 谢谢
-
用WordPress构建电子商务网站已经是一个流行的解决方案,与oscommerce、prestashop相比,WordPress更适合构建小型电商网站,显然WordPress对资源的消耗使其难以胜任大型电子商务网站,但博客式营销的模式以及WordPress的CMS特性也让它有胜过大型电商网站的地方——搭建更容易、费用低、管理简单,非常适合那些卖的产品不多的人。今天介绍的是一款新兴的WordPre
-
我正试图浏览一个网站。我尝试过使用两种方法,但都没有提供完整的网站源代码,我正在寻找。我正试图从下面提供的网站URL中获取新闻标题。 URL:"https://www.todayonline.com/" 这是我尝试过但失败的两种方法。 请帮忙。我试着抓取其他新闻网站,这要容易得多。谢谢你。
-
大家好! 我今天正在做一个电子商务网站的项目(练习给我的学习)。我目前正在控制管理员可以制作的不同条目(创建一个产品,一个品牌等) 为了创建控件,我使用express-validator,下面是不同的表及其参数: 客户: 用户名 电子邮件 密码 产品: 产品名称 说明 价格 图像URL 产品数量 品牌ID 品牌ID: 品牌名称 徽标URL 和更多 我想知道什么是常见的验证数据的有效性插入从一个电子
-
问题内容: 我最近一直在学习Python,并全力以赴来构建网络抓取工具。一点都不花哨。其唯一目的是从博彩网站上获取数据并将其放入Excel。 大多数问题都是可以解决的,我周围有些混乱。但是,我在一个问题上遇到了巨大的障碍。如果站点加载一张马表并列出当前的投注价格,则此信息不在任何源文件中。提示是该数据有时是活动的,并且明显从某个远程服务器更新了这些数据。我PC上的HTML只是有一个漏洞,他们的服务