
将循环中的多个数组/组转换为单个数据帧

数据帧:
sample_data = [['USA', 'gdp', 2001, 10],['USA', 'avgIQ', 2001, 100],['USA', 'people', 2001, 1000],['USA', 'dragons', 2001, 3],['CHN', 'gdp', 2001, 12], ['CHN', 'avgIQ', 2001, 120],['CHN', 'people', 2001, 2000],['CHN', 'dragons', 2001, 1],['RUS', 'gdp', 2001, 11],['RUS', 'avgIQ', 2001, 105], ['RUS', 'people', 2001, 1500],['RUS', 'dragons', 2001, np.nan],['USA', 'gdp', 2002, 12],['USA', 'avgIQ', 2002, 105],['USA', 'people', 2002, 1200], ['USA', 'dragons', 2002, np.nan],['CHN', 'gdp', 2002, 14],['CHN', 'avgIQ', 2002, 127],['CHN', 'people', 2002, 3100],['CHN', 'dragons', 2002, 4], ['RUS', 'gdp', 2002, 11],['RUS', 'avgIQ', 2002, 99],['RUS', 'people', 2002, 1600],['RUS', 'dragons', 2002, np.nan],['USA', 'gdp', 2003, 15], ['USA', 'avgIQ', 2003, 115],['USA', 'people', 2003, 2000],['USA', 'dragons', 2003, np.nan],['CHN', 'gdp', 2003, 16],['CHN', 'avgIQ', 2003, 132], ['CHN', 'people', 2003, 4000],['CHN', 'dragons', 2003, 6],['RUS', 'gdp', 2003, 11],['RUS', 'avgIQ', 2003, 108],['RUS', 'people', 2003, 2000], ['RUS', 'dragons', 2003, np.nan],['USA', 'gdp', 2004, 18],['USA', 'avgIQ', 2004, 111],['USA', 'people', 2004, 2500],['USA', 'dragons', 2004, np.nan], ['CHN', 'gdp', 2004, 18],['CHN', 'avgIQ', 2004, 140],['CHN', 'people', 2004, np.nan],['CHN', 'dragons', 2004, np.nan], ['RUS', 'gdp', 2004, 15],['RUS', 'avgIQ', 2004, 103],['RUS', 'people', 2004, 2800],['RUS', 'dragons', 2004, np.nan], ['USA', 'gdp', 2005, 23],['USA', 'avgIQ', 2005, 111],['USA', 'people', 2005, 3700],['USA', 'dragons', 2005, 8],['CHN', 'gdp', 2005, 22], ['CHN', 'avgIQ', 2005, 143],['CHN', 'people', 2005, 6000],['CHN', 'dragons', 2005, 15],['RUS', 'gdp', 2005, 17],['RUS', 'avgIQ', 2005, np.nan], ['RUS', 'people', 2005, 3000],['RUS', 'dragons', 2005, 3]]
sample_df = pd.DataFrame(sample_data, columns = ['A','B','C','D'])
sample_df['C'] = sample_df['C'].astype(float)
sample_df.head()
Data columns (total 4 columns):
A 60 non-null object
B 60 non-null object
C 60 non-null float64
D 50 non-null float64
dtypes: float64(2), object(2)
from impyute.imputation.cs import mice
sample_group = sample_df.groupby(['A', 'B'])
for group_index, group in sample_group:
if group.isnull().values.any() == True:
group['D'] = ((mice(group.apply({'C': lambda x: x.values, 'D': lambda y: y.values})))[1]).values
print(group)
else:
print(group)
continue
A B C D
5 CHN avgIQ 2,001.00 120.00
17 CHN avgIQ 2,002.00 127.00
29 CHN avgIQ 2,003.00 132.00
41 CHN avgIQ 2,004.00 140.00
53 CHN avgIQ 2,005.00 143.00
A B C D
7 CHN dragons 2,001.00 1.00
19 CHN dragons 2,002.00 4.00
31 CHN dragons 2,003.00 6.00
43 CHN dragons 2,004.00 10.86
55 CHN dragons 2,005.00 15.00
A B C D
4 CHN gdp 2,001.00 12.00
16 CHN gdp 2,002.00 14.00
28 CHN gdp 2,003.00 16.00
40 CHN gdp 2,004.00 18.00
52 CHN gdp 2,005.00 22.00
A B C D
6 CHN people 2,001.00 2,000.00
18 CHN people 2,002.00 3,100.00
30 CHN people 2,003.00 4,000.00
42 CHN people 2,004.00 5,014.29
54 CHN people 2,005.00 6,000.00
A B C D
9 RUS avgIQ 2,001.00 105.00
21 RUS avgIQ 2,002.00 99.00
33 RUS avgIQ 2,003.00 108.00
45 RUS avgIQ 2,004.00 103.00
57 RUS avgIQ 2,005.00 104.50
A B C D
11 RUS dragons 2,001.00 3.00
23 RUS dragons 2,002.00 3.00
35 RUS dragons 2,003.00 3.00
47 RUS dragons 2,004.00 3.00
59 RUS dragons 2,005.00 3.00
A B C D
8 RUS gdp 2,001.00 11.00
20 RUS gdp 2,002.00 11.00
32 RUS gdp 2,003.00 11.00
44 RUS gdp 2,004.00 15.00
56 RUS gdp 2,005.00 17.00
A B C D
10 RUS people 2,001.00 1,500.00
22 RUS people 2,002.00 1,600.00
34 RUS people 2,003.00 2,000.00
46 RUS people 2,004.00 2,800.00
58 RUS people 2,005.00 3,000.00
A B C D
1 USA avgIQ 2,001.00 100.00
13 USA avgIQ 2,002.00 105.00
25 USA avgIQ 2,003.00 115.00
37 USA avgIQ 2,004.00 111.00
49 USA avgIQ 2,005.00 111.00
A B C D
3 USA dragons 2,001.00 3.00
15 USA dragons 2,002.00 4.25
27 USA dragons 2,003.00 5.50
39 USA dragons 2,004.00 6.75
51 USA dragons 2,005.00 8.00
A B C D
0 USA gdp 2,001.00 10.00
12 USA gdp 2,002.00 12.00
24 USA gdp 2,003.00 15.00
36 USA gdp 2,004.00 18.00
48 USA gdp 2,005.00 23.00
A B C D
2 USA people 2,001.00 1,000.00
14 USA people 2,002.00 1,200.00
26 USA people 2,003.00 2,000.00
38 USA people 2,004.00 2,500.00
50 USA people 2,005.00 3,700.00
我遵循了一个类似问题的解决方案:如何从for循环中构建和填充熊猫数据帧?
sample_group = sample_df.groupby(['A', 'B'])
d = []
for group_index, group in sample_group:
if group.isnull().values.any() == True:
group['D'] = ((mice(group.apply({'C': lambda x: x.values, 'D': lambda y: y.values})))[1]).values
d.append({'A': group.A.values, 'B': group.B.values, 'C': group.C.values, 'D': group.D.values})
else:
d.append({'A': group.A.values, 'B': group.B.values, 'C': group.C.values, 'D': group.D.values})
continue
d = pd.DataFrame(d)
d.head(10)

- 您可以看到这些值都是准确的,但是它返回了每个索引的整个值列表
sample_group = sample_df.groupby(['A', 'B'])
d = pd.DataFrame()
for group_index, group in sample_group:
if group.isnull().values.any() == True:
group['D'] = ((mice(group.apply({'C': lambda x: x.values, 'D': lambda y: y.values})))[1]).values
temp = pd.DataFrame({'A': group.A.values, 'B': group.B.values, 'C': group.C.values, 'D': group.D.values})
else:
temp = pd.DataFrame({'A': group.A, 'B': group.B, 'C': group.C.values, 'D': group.D.values})
continue
d = pd.concat([d, temp])
d.head()
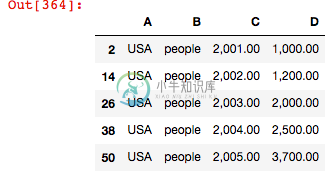
- 此输出看起来正确,但正如您所看到的,只返回第一组
共有1个答案

sample_group = sample_df.groupby(['A', 'B'])
d = pd.DataFrame([])
for group_index, group in sample_group:
if group.isnull().values.any() == True:
group['D'] = ((mice(group.apply({'C': lambda x: x.values, 'D': lambda y: y.values})))[1]).values
d = d.append(pd.DataFrame({'A': group.A.values, 'B': group.B.values, 'C': group.C.values, 'D': group.D.values}))
else:
d = d.append(pd.DataFrame({'A': group.A.values, 'B': group.B.values, 'C': group.C.values, 'D': group.D.values}))
continue
d.head(20)
索引在输出中看起来有点奇怪,但经过一个简单的。重置索引当时正下着雨。希望这能在将来的某个时候对某人有所帮助。
这非常有帮助:
在循环中使用熊猫. append
-
问题内容: 我有一个无缘无故的多维数组 我想将此数组转换为这种形式 任何想法如何做到这一点? 问题答案: 假设此数组可能是(也可能不是)冗余嵌套,并且您不确定它的深度,可以为您展平它:
-
问题内容: 假设我有; 我尝试转换; 我现在正在vstack上通过迭代来解决它,但是对于特别大的LIST来说确实很慢 您对最佳有效方法有何建议? 问题答案: 通常,您可以沿任意轴连接整个数组序列: 但你 也 必须对列表中的形状和每个阵列的维度担心(用于2维3x5的输出,你需要确保它们都是2维正由-5阵列的话)。如果要将一维数组连接为二维输出的行,则需要扩展其维数。 正如Jorge的答案所指出的那样
-
问题内容: 我发现了关于将两个数组列表交织在一起的类似问题,但在PHP中却是如此。我在面试中也被问到了这个问题,但无法解决,回到SO看看是否已经解决,但我只能找到这篇 论文 那么是否有任何指向伪代码或方法定义的指针? Big(O)限制:O(n)-时间成本和O(1)-空间成本 示例: a [] = a1,a2,…, a b [] = b1,b2,…,bn 将数组列表重新排列为a1,b1,a2,b2,
-
我有以下代码: 现在我想再组合一个数组和中的它的值。这是foreach语句中的三个数组。谁能帮我把它加进去。比如我们如何在foreach语句中添加多个。 例如,我想要以下内容: 但是上面的代码给出了。我得到的错误是 分析错误:语法错误,在/homepages/4/d864452909/htdocs/public_html/app/index.php第58行中,意外的“=>”(T_DOUBLE_AR
-
问题内容: 我正在尝试将此for循环重写为for每个循环。 这就是我尝试过的 谁能指出我正确的方向?谢谢。 问题答案: 我认为您想得太多… :)