
在ANTLR4中组合不同的解析器规则以简化TreeListener中的处理

这是我的语法文件的一部分:
paragraph
: TEXT? italic TEXT?
| TEXT? STAR TEXT?
| TEXT? labelRef TEXT?
| TEXT? BRACE_OPEN TEXT?
| TEXT? LABEL TEXT?
| ELEMENTPATH
| TEXT
;
段落规则应该“标记”我岛语法中的所有段落,因为我想围绕生成的段落元素生成p块。从技术上讲,所有不同的段落元素都可以识别。
问题是,不同的规则会导致侦听器中的段落调用不同。由于规则不同,这是完全合乎逻辑的,但这使得在侦听器中处理树非常困难。同一段落的两个不同条目(例如)可以在图1中找到。
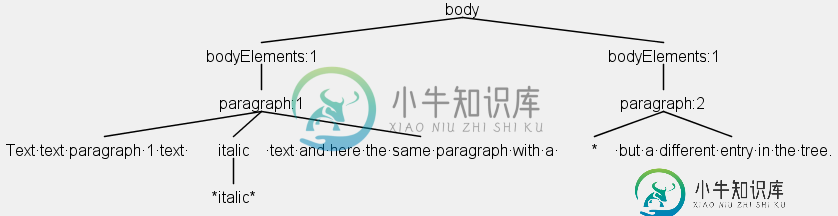
输入文本为:
Text text paragraph 1 text *italic* text and here the same paragraph with a * but a different entry in the tree.
只有一个段落,但如果我处理树,输出的HTML将包含两个段落。
有没有办法将这些不同的规则部分组合成一个段落调用?如果只有一个段落,解析树中不应该有两个不同的段落。
共有1个答案

您的段落规则设置为一次仅识别一个定义的字符串。因此,您的第一段是斜体文本,第二段是星形文本。
试试吧
paragraph
: ( TEXT? italic TEXT?
| TEXT? STAR TEXT?
| TEXT? labelRef TEXT?
| TEXT? BRACE_OPEN TEXT?
| TEXT? LABEL TEXT?
| ELEMENTPATH
| TEXT
)+
;
-
我对是否允许以下情况感到困惑: UPDATE:我知道当我在for循环中提供正确的声明类型时,它就会工作。问题是如果我不这样做会发生什么?
-
可能在内部使用的代码将在规则之后被取消,如下所示: ANTLR4就是这样做事的吗?
-
请考虑这个非常简化的示例,其中应该匹配以下形式的输入 如果您需要一个简单的实际应用程序,那么您可以考虑Java中的字符串。其中一些可能是需要用完全不同的解析器解析的regex。它类似于您可以在IDEA内部使用的注入语言。 问:在ANTRL4中是否有一种惯用的方法来用不同的语法解析特定的规则?最好的情况是,我可以在语法级别上指定它,以便生成的AST是包含注入语言的子树的外部语言的组合。
-
谢谢回复! 皮特
-
有什么方法可以让ANTLR4自动删除生成的解析树中的冗余节点吗? 更具体地说,我一直在试验GLSL的语法,由于自动处理操作符优先级所需的规则转发,您最终会在解析树中看到长的线性“表达式”序列。 大多数生成的树节点都只是简单地“转发到下一个优先级”,所以不要提供任何有用的语法信息--你只需要每个序列中最后一个表达式节点(即规则转发停止的点),或者它成为一个实际的树节点并拥有多个子节点的点(即在源中遇
-
我的语法在很大程度上必须忽略空格,除非在某些上下文中。这个问题的答案建议定义特定的lexer规则来处理我想要的异常。 问题是(我认为)我不能在lexer级别处理这种情况,因为它们似乎是在解析器级别被触发的。 更具体地说:我想认识一些东西,比如 记住我有一个WS- 在Xtext中,规则可以在规则范围的基础上指定在规则范围内应用哪些隐藏令牌: 但是我对antlr4一无所知。