
Python网页抓取(Beautiful Soup、Selenium和PhantomJS):只抓取整个页面的一部分

你好,我有麻烦试图刮数据从一个网站的建模目的(Fantsylabs dotcom)。我只是一个黑客,所以原谅我对comp sci行话的无知。我想完成的是...
>
使用selenium登录网站,导航到有数据的页面。
## Initialize and load the web page
url = "website url"
driver = webdriver.Firefox()
driver.get(url)
time.sleep(3)
## Fill out forms and login to site
username = driver.find_element_by_name('input')
password = driver.find_element_by_name('password')
username.send_keys('username')
password.send_keys('password')
login_attempt = driver.find_element_by_class_name("pull-right")
login_attempt.click()
## Find and open the page with the data that I wish to scrape
link = driver.find_element_by_partial_link_text('Player Models')
link.click()
time.sleep(10)
##UPDATED CODE TO TRY AND SCROLL DOWN TO LOAD ALL THE DYNAMIC DATA
scroll = driver.find_element_by_class_name("ag-body-viewport")
driver.execute_script("arguments[0].scrollIntoView();", scroll)
## Try to allow time for the full page to load the lazy way then pass to BeautifulSoup
time.sleep(10)
html2 = driver.page_source
soup = BeautifulSoup(html2, "lxml", from_encoding="utf-8")
div = soup.find_all('div', {'class':'ag-pinned-cols-container'})
## continue to scrape what I want
这个过程的工作原理是登录,导航到正确的页面,但是一旦页面完成动态加载(30秒),就把它传递给美丽的汤。我在表中看到大约300个实例,我想刮......然而,bs4刮刀只吐出了300个实例中的30个。从我自己的研究来看,这可能是通过javascript动态加载数据的问题,只有推送到html的内容才会被bs4解析?说明:使用Pythonrequests.get解析一次不加载的html代码
对于任何提供建议的人来说,在没有在网站上创建个人资料的情况下复制我的例子可能很难,但是使用phantomJS初始化浏览器是否就是“抓取”所有实例以捕获所有所需数据所需要的全部?
driver = webdriver.PhantomJS() ##instead of webdriver.Firefox()
任何想法或经验都将受到赞赏,因为我从来没有处理过动态页面/抓取javascript,如果这是我遇到的。
Alecs回复后更新:
下面是目标数据的屏幕截图(以蓝色突出显示)。您可以看到图像右侧的滚动条,它嵌入在页面中。我还提供了该容器中页面源代码的视图。
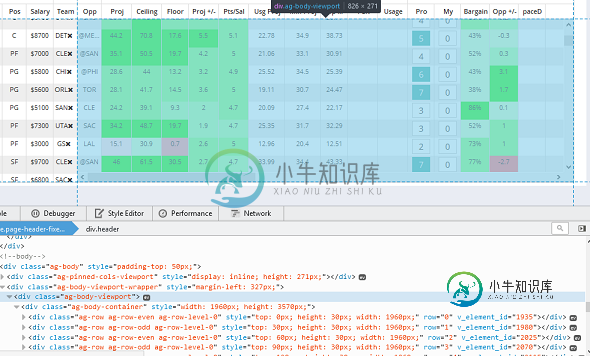
我已经修改了我提供的原始代码,试图向下滚动到底部并完全加载页面,但它无法执行此操作。当我将驱动程序设置为Firefox()时,我可以看到页面通过外部滚动条向下移动,但不在目标容器内。我希望这是有道理的。
再次感谢您的建议/指导。
共有1个答案

这不容易回答,因为我们没有办法重现这个问题。
一个问题是lxml不能很好地处理这种特定的超文本标记语言,您可能需要尝试更改解析器:
soup = BeautifulSoup(html2, "html.parser")
soup = BeautifulSoup(html2, "html5lib")
此外,首先可能不需要BeautifulSoup。您可以使用selenium以多种不同的方式定位元素。例如,在这种情况下:
for div in driver.find_elements_by_css_selector(".ag-pinned-cols-container'"):
# do smth with 'div'
也可能是当你将页面向下滚动时,数据是动态加载的。在这种情况下,您可能需要将页面向下滚动,直到您看到所需的数据量或滚动时没有更多的新数据加载。以下是相关线程与示例解决方案:
- 使用selenium python webdriver滚动网页
- 使用Python中的PhantomJS向下滚动到无限页面的底部
- 使用Selenium缓慢向下滚动页面
- 使用Python中的Selenium停止动态页面中的滚动
-
问题内容: 我正在使用Python从网站上抓取内容。首先,我用和Python的,但我看到,该网站有一个按钮,通过JavaScript创建的内容,所以我决定使用。 假设我可以使用Selenium等方法找到元素并获取其内容,那么当我可以对所有内容都使用Selenium时,有什么理由要使用? 在这种特殊情况下,我需要使用Selenium来单击JavaScript按钮,以便更好地使用Selenium进行解
-
我是python新手,正在尝试从以下站点获取数据。虽然这段代码适用于不同的站点,但我无法让它适用于nextgen stats。有人想知道为什么吗?下面是我的代码和我得到的错误 下面是我得到的错误 df11=pd。读取html(urlwk1)回溯(上次调用):文件“”,第1行,在文件“C:\Users\USERX\AppData\Local\Packages\PythonSoftwareFounda
-
问题内容: 基本上,我想使用来严格抓取网页上的可见文本。例如,此网页是我的测试用例。我主要想获取正文文本(文章),甚至在这里和那里甚至几个标签名称。我已经尝试过在这个SO问题中返回不想要的标签和html注释的建议。我无法弄清楚该函数所需的参数,以便仅获取网页上的可见文本。 那么,我应该如何查找除脚本,注释,CSS等之外的所有可见文本? 问题答案: 尝试这个:
-
本文向大家介绍python+selenium+PhantomJS抓取网页动态加载内容,包括了python+selenium+PhantomJS抓取网页动态加载内容的使用技巧和注意事项,需要的朋友参考一下 环境搭建 准备工具:pyton3.5,selenium,phantomjs 我的电脑里面已经装好了python3.5 安装Selenium pip3 install selenium 安装Phan
-
问题内容: 在网站上,有在标顶部的几个环节,,,和。如果按下以数字标记的链接,它将动态地将一些数据加载到content中。如果被按下,它会用标签页,,,和第4页中的数据显示。 我想从按下的所有链接的内容中抓取数据(我不知道有多少,一次只显示3个,然后) 请举一个例子。例如,考虑网站www.cnet.com。 请指导我下载使用selenium的一系列页面,并自行解析它们以处理漂亮的汤。 问题答案:
-
问题内容: 我正在尝试开发一个简单的网页抓取工具。我想提取没有代码的文本。我实现了这个目标,但是我发现在某些加载了的页面中,我没有获得良好的结果。 例如,如果一些代码添加了一些文本,则看不到它,因为当我调用 我得到的原始文本没有添加文本(因为在客户端执行了)。 因此,我正在寻找一些解决此问题的想法。 问题答案: 一旦安装了,请确保二进制文件在当前路径中可用: 例 举个例子,我用以下HTML代码创建