
如何将PyCharm与PySpark链接?

我是apache spark的新手,显然我在我的macbook中安装了apache spark with homebrew:
Last login: Fri Jan 8 12:52:04 on console
user@MacBook-Pro-de-User-2:~$ pyspark
Python 2.7.10 (default, Jul 13 2015, 12:05:58)
[GCC 4.2.1 Compatible Apple LLVM 6.1.0 (clang-602.0.53)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
16/01/08 14:46:44 INFO SparkContext: Running Spark version 1.5.1
16/01/08 14:46:46 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/01/08 14:46:47 INFO SecurityManager: Changing view acls to: user
16/01/08 14:46:47 INFO SecurityManager: Changing modify acls to: user
16/01/08 14:46:47 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(user); users with modify permissions: Set(user)
16/01/08 14:46:50 INFO Slf4jLogger: Slf4jLogger started
16/01/08 14:46:50 INFO Remoting: Starting remoting
16/01/08 14:46:51 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriver@192.168.1.64:50199]
16/01/08 14:46:51 INFO Utils: Successfully started service 'sparkDriver' on port 50199.
16/01/08 14:46:51 INFO SparkEnv: Registering MapOutputTracker
16/01/08 14:46:51 INFO SparkEnv: Registering BlockManagerMaster
16/01/08 14:46:51 INFO DiskBlockManager: Created local directory at /private/var/folders/5x/k7n54drn1csc7w0j7vchjnmc0000gn/T/blockmgr-769e6f91-f0e7-49f9-b45d-1b6382637c95
16/01/08 14:46:51 INFO MemoryStore: MemoryStore started with capacity 530.0 MB
16/01/08 14:46:52 INFO HttpFileServer: HTTP File server directory is /private/var/folders/5x/k7n54drn1csc7w0j7vchjnmc0000gn/T/spark-8e4749ea-9ae7-4137-a0e1-52e410a8e4c5/httpd-1adcd424-c8e9-4e54-a45a-a735ade00393
16/01/08 14:46:52 INFO HttpServer: Starting HTTP Server
16/01/08 14:46:52 INFO Utils: Successfully started service 'HTTP file server' on port 50200.
16/01/08 14:46:52 INFO SparkEnv: Registering OutputCommitCoordinator
16/01/08 14:46:52 INFO Utils: Successfully started service 'SparkUI' on port 4040.
16/01/08 14:46:52 INFO SparkUI: Started SparkUI at http://192.168.1.64:4040
16/01/08 14:46:53 WARN MetricsSystem: Using default name DAGScheduler for source because spark.app.id is not set.
16/01/08 14:46:53 INFO Executor: Starting executor ID driver on host localhost
16/01/08 14:46:53 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 50201.
16/01/08 14:46:53 INFO NettyBlockTransferService: Server created on 50201
16/01/08 14:46:53 INFO BlockManagerMaster: Trying to register BlockManager
16/01/08 14:46:53 INFO BlockManagerMasterEndpoint: Registering block manager localhost:50201 with 530.0 MB RAM, BlockManagerId(driver, localhost, 50201)
16/01/08 14:46:53 INFO BlockManagerMaster: Registered BlockManager
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 1.5.1
/_/
Using Python version 2.7.10 (default, Jul 13 2015 12:05:58)
SparkContext available as sc, HiveContext available as sqlContext.
>>>
我想开始玩,以便了解更多关于MLlib的信息。但是,我使用Py魅力在python中编写脚本。问题是:当我去Py魅力并尝试调用pyspark时,Py魅力找不到模块。我尝试将路径添加到Py魅力,如下所示:
然后我在博客上尝试了这个:
import os
import sys
# Path for spark source folder
os.environ['SPARK_HOME']="/Users/user/Apps/spark-1.5.2-bin-hadoop2.4"
# Append pyspark to Python Path
sys.path.append("/Users/user/Apps/spark-1.5.2-bin-hadoop2.4/python/pyspark")
try:
from pyspark import SparkContext
from pyspark import SparkConf
print ("Successfully imported Spark Modules")
except ImportError as e:
print ("Can not import Spark Modules", e)
sys.exit(1)
并且仍然无法开始使用PySpark与Py魅力,任何想法如何“链接”PyCharm与apache-pyspark?。
更新:
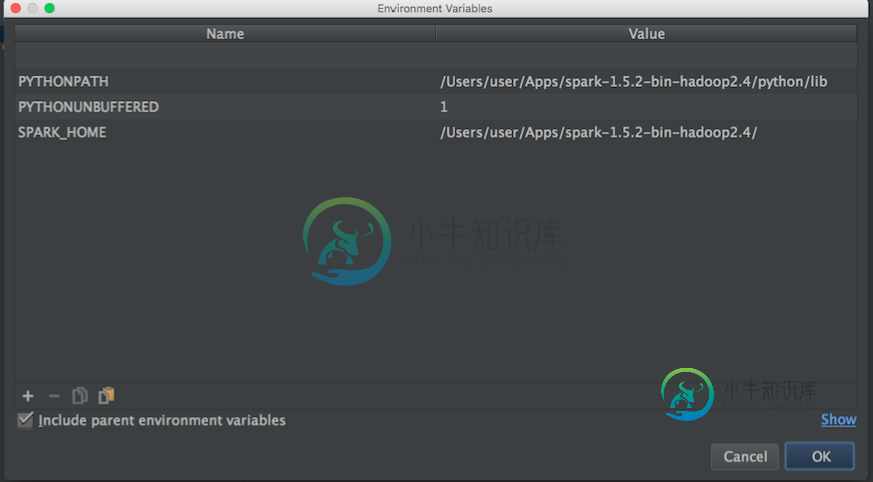
然后我搜索apache spark和python路径,以设置Pycharm的环境变量:
Apache-火花路径:
user@MacBook-Pro-User-2:~$ brew info apache-spark
apache-spark: stable 1.6.0, HEAD
Engine for large-scale data processing
https://spark.apache.org/
/usr/local/Cellar/apache-spark/1.5.1 (649 files, 302.9M) *
Poured from bottle
From: https://github.com/Homebrew/homebrew/blob/master/Library/Formula/apache-spark.rb
python路径:
user@MacBook-Pro-User-2:~$ brew info python
python: stable 2.7.11 (bottled), HEAD
Interpreted, interactive, object-oriented programming language
https://www.python.org
/usr/local/Cellar/python/2.7.10_2 (4,965 files, 66.9M) *
然后,根据上述信息,我尝试如下设置环境变量:

知道如何将Pycharm与pyspark正确链接吗?
然后当我使用上述配置运行python脚本时,我有这个例外:
/usr/local/Cellar/python/2.7.10_2/Frameworks/Python.framework/Versions/2.7/bin/python2.7 /Users/user/PycharmProjects/spark_examples/test_1.py
Traceback (most recent call last):
File "/Users/user/PycharmProjects/spark_examples/test_1.py", line 1, in <module>
from pyspark import SparkContext
ImportError: No module named pyspark
更新:然后我尝试了@zero323提出的这种配置
配置1:
/usr/local/Cellar/apache-spark/1.5.1/

出:
user@MacBook-Pro-de-User-2:/usr/local/Cellar/apache-spark/1.5.1$ ls
CHANGES.txt NOTICE libexec/
INSTALL_RECEIPT.json README.md
LICENSE bin/
配置2:
/usr/local/Cellar/apache-spark/1.5.1/libexec

出:
user@MacBook-Pro-de-User-2:/usr/local/Cellar/apache-spark/1.5.1/libexec$ ls
R/ bin/ data/ examples/ python/
RELEASE conf/ ec2/ lib/ sbin/
共有3个答案

这是适合我的设置(Win7 64bit,PyCharm2017.3CE)
设置Intellisense:
>
单击“文件”-
单击项目解释器下拉列表右侧的齿轮图标
单击“更多…”。。。从上下文菜单
选择解释器,然后单击“显示路径”图标(右下角)
单击图标二添加以下路径:
\python\lib\py4j-0.9-src。拉链
\bin\python\lib\pyspark。拉链
单击OK,OK,OK
继续测试您的新intellisense功能。

下面是我如何在mac osx上解决这个问题的。
>
export SPARK_VERSION=`ls /usr/local/Cellar/apache-spark/ | sort | tail -1`
export SPARK_HOME="/usr/local/Cellar/apache-spark/$SPARK_VERSION/libexec"
export PYTHONPATH=$SPARK_HOME/python/:$PYTHONPATH
export PYTHONPATH=$SPARK_HOME/python/lib/py4j-0.9-src.zip:$PYTHONPATH
将pyspark和py4j添加到内容根目录(使用正确的Spark版本):
/usr/local/Cellar/apache-spark/1.6.1/libexec/python/lib/py4j-0.9-src.zip
/usr/local/Cellar/apache-spark/1.6.1/libexec/python/lib/pyspark.zip

随着SPARK-1267的合并,您应该能够通过在PyCharm开发使用的环境中安装SPARK来简化流程。
>
单击安装包按钮。
创建运行配置:
>
>
SPARK_HOME-它应该指向安装了Spark的目录。它应该包含诸如bin(带有spack-递交、spack-shell等)和conf(带有spark-defaults.conf、spark-env.sh等)之类的目录。PYTHONPATH-它应该包含$SPARK_HOME/python和可选的$SPARK_HOME/python/lib/py4j-some-version.src.zip如果没有其他可用。
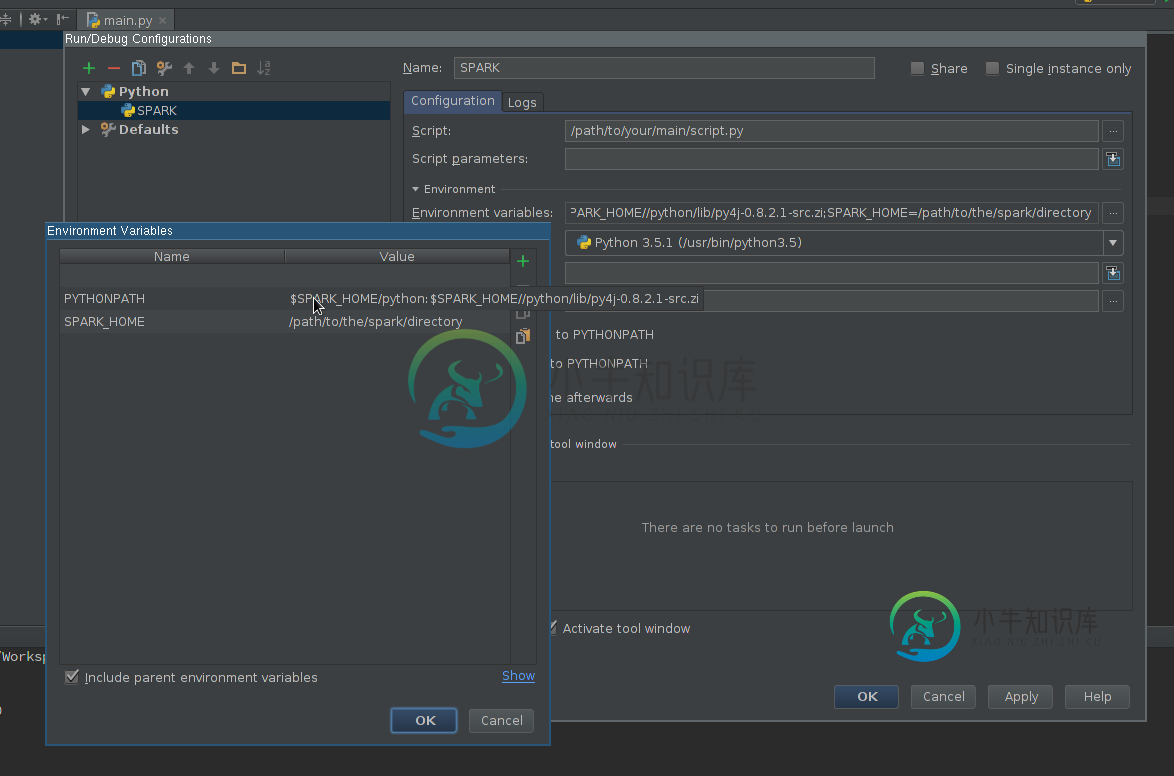
应用设置
将PySpark库添加到解释器路径(代码完成所需):
- 转到文件-
- 安装或添加到与已安装的Spark版本匹配的路径类型注释,以更好地完成和静态错误检测(免责声明-我是该项目的作者)
使用新创建的配置运行脚本。
-
我想在PyCharm中运行ROS,但是找不到。应该在其中进行更改的桌面文件。此外,我想使用为< code>PyTorch创建的相同环境,不想更改解释器。有人能帮我一下吗? 问候。
-
我希望使用标题中列出的两种服务制作一个聊天机器人。Watson assistant用于为聊天机器人创建对话框,而Watson discovery允许在大量文档中查找信息,例如。html。pdf文件。我想制作一个使用这两种服务的聊天机器人。 聊天机器人的工作方式是,当用户对聊天机器人说了什么时,它将通过watson discovery并运行该查询,然后将结果返回给用户。 我目前知道如何使用沃森发现和
-
我正在使用ros框架开发一个机器人。作为ide,我使用PyCharm。但是我不能将ros导入其中。在ros网站上有一篇关于ide的文章http://wiki.ros.org/IDEs.有关于将ros与pyCharm一起使用的信息。我必须修改.桌面文件,但是我使用软件中心的一个快照安装了PyCharm。我在哪里可以找到快照应用程序的.桌面文件?可以有另一种方法将ros导入PyCharm吗? 编辑:@
-
问题内容: 我的盒子上正在运行以下Docker容器… 我的目标是让kibana链接到我的elasticsearch容器,但是当我点击kibana时,它告诉我我没有任何文档存储。我知道这是不对的,因为我肯定在Elasticsearch中有文件。我猜我的链接命令是错误的。 这是我用来启动kibana容器的docker命令。 有人可以告诉我我做错了什么吗? 谢谢 问题答案: 首先,链接是旧功能,首先创建
-
我用Vscode(HTML、SASS和JS)编写了前端,并用Intellij中的Springboot构建了后端。如何将它们链接在一起?还是将前端代码复制到Intellij中?我不知道Springboot是否支持sass。我需要你的帮助。
-
问题内容: 我在Elasticsearch中使用Pyspark。我注意到,当您创建RDD时,不会在任何收集,计数或任何其他“最终”操作之前执行该RDD。 当我将转换后的RDD的结果用于其他事情时,是否还有执行和缓存转换后的RDD的方法。 问题答案: 就像我在评论部分所说的那样, Spark中的所有转换都是 惰性的 ,因为它们不会立即计算出结果。相反,他们只记得应用于某些基本数据集(例如文件)的转换