
GoogleSheets-使用3列数据查找发生最多的内容

我一直在想方设法找出解决这个问题的最好办法。
我有一个包含3列的电子表格。
- 列
A是日期(每月明细) - 列
B包括时间(每小时细分) - 列
C包含特定日期该小时内发生的事件计数
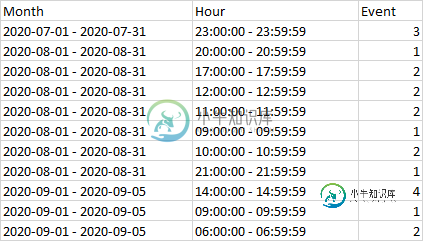
我想做的是找出事件发生的最常见时间。所以我并不需要日期,我只是想知道一天中最有可能发生事件的时间,这样我就可以从最好的时间到最坏的时间排序。
因此,我知道我需要以某种方式将与不同日期相匹配的小时数,以及它们的事件总数结合起来,但我不知道如何做到这一点。
共有2个答案

你提到:
...事件最有可能发生在一天中的哪一个小时,以便我可以从最好的时间到最坏的时间排序。
您还可以使用单个查询公式
=QUERY(B1:C,
"select B, sum(C) where B is not null group by B order by sum(C) desc label sum(C) 'Best ↓' ",1)
使用的功能:
查询

最好的方法是创建轴,但如果要使用公式,请使用SUMIF:
=SUMIF($B$2:$B$12;A16;$C$2:$C$12)
-
问题内容: 我有一个列的数据帧,。我需要创建一个列,以便为每个记录/行: 。 我应该怎么做呢? 问题答案: 您可以这样获得最大值: 所以: 如果您知道“ A”和“ B”是唯一的列,那么您甚至可以逃脱 我猜你也可以使用。
-
问题内容: 说我有以下三个常数: 我想将它们中的三个取走,并使用它们来查找三个中的最大值,但是如果我传递的值超过两个,那么它给我一个错误。例如: 请让我知道我在做什么错。 问题答案: 只需要两个参数。如果要最多三个,请使用。
-
我有一个商店对象列表,这些对象按其拥有的物品进行分组。 我怎样才能得到每个商品的3家最大商店(或n家最大商店)的列表?假设我有 我想返回按商品分组的前3家商店的列表。我对项目进行了分组,但不确定如何遍历给定的映射或入口集。。。
-
如何查找每个字符串在列表中出现的次数? 说我有这个词: 这在我的清单上大概有20次。我怎样才能发现它在我的列表中出现了20次?我需要知道这一点,以便将该数字显示为一种类型的答案。 例如: 我将如何以类似的方式显示它?:
-
问题内容: 请帮助我生成以下查询。说我有客户表和订单表。 客户表 订单表 我想找出连续三个月下订单的客户。(允许使用SQL Server 2005和2008进行查询)。 所需的输出是: 问题答案: 编辑: 摆脱或 那样似乎会削弱性能。
-
本文向大家介绍pandas使用apply多列生成一列数据的实例,包括了pandas使用apply多列生成一列数据的实例的使用技巧和注意事项,需要的朋友参考一下 如下所示: 以上这篇pandas使用apply多列生成一列数据的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持呐喊教程。