
将文本列转换为数字

我是数据分析新手。我正在尝试一些模型在Python SkLearning。我有一个数据集,其中一些列有文本列。像下面,
数据集
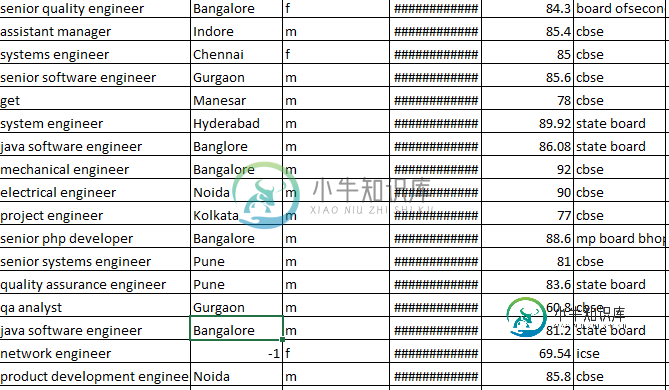
是否有办法将这些列值转换为pandas或Sklearn中的数字?。将数字分配给这些值是正确的?。如果测试数据中出现新字符串呢?。
请给我一些建议。
共有2个答案

您可以使用分类数据类型将它们转换为整数代码。
column = column.astype('category')
column_encoded = column.cat.codes
只要使用具有足够深树的基于树的模型,例如GradientBoostingClassifier(max_depth=10),您的模型就应该能够再次拆分类别。

考虑使用标签编码-它通过将每个类别指定为0和NothOfFi类别-1之间的整数来转换分类数据:
from sklearn.preprocessing import LabelEncoder
df = pd.DataFrame(['a','b','c','d','a','c','a','d'], columns=['letter'])
letter
0 a
1 b
2 c
3 d
4 a
5 c
6 a
申请:
le = LabelEncoder()
encoded_series = df[df.columns[:]].apply(le.fit_transform)
编码的U系列:
letter
0 0
1 1
2 2
3 3
4 0
5 2
6 0
7 3
-
问题内容: 我有大量文本字符串,这些字符串显然是PDF文件的原始数据,我需要将其重新制作为PDF。 目前,我正在将字符串读取到StringBuffer中,但是如果需要,可以更改它。从那里,我尝试将其写到文件中并更改扩展名(我真的希望这样做能起作用,但是我有点不知道),我尝试将其带入String,然后从中取出byte []。并将其写入文件,或使用DataOutputStream将字节放入文件中。这些
-
我有每月的列值编号。 <代码>df 我想将其转换为: 1月, 2月, 3月, 4月, 5月, 6月, 7月, 8月, 9月, 10月, 11月, 12月, 2月, 3月 有人能帮我吗? 提前感谢您抽出宝贵时间
-
问题内容: 我只想知道在Java或C#中是否有任何库或外部库中的构建允许我获取音频文件并对其进行解析并从中提取文本。 我需要创建一个应用程序,但是我不知道从哪里开始。 问题答案: 以下是您的一些选择: 微软演讲 光明 龙自然讲 狮身人面像4
-
在下面的示例中,我们试图将XML数据转换为HTML
-
谈到XSLT,我是一个完全的新手,所以我很难找到解决问题的方法。 我有以下来自PeopleSoft的XML: PeopleSoft"有益地"将所有文本数据放入CDATA部分,我想删除CDATA,并将字符串放在正常的文本节点中: 有人能在我需要创建我想要的输出的XSLT上给我一个正确的方向吗?非常感谢提前
-
通过使用Java8流: 从性能上看,哪个更好?