
为什么saveAll()总是插入数据而不是更新数据?

Spring Boot 2.4.0,DB是MySql 8。
使用REST每15秒从远程获取数据并使用saveAll()将其存储到MySql DB。
它为所有给定的实体调用save()方法。
所有数据都设置了ID。
我希望如果DB中没有这样的id-它将被插入。
如果这样的ID已经在DB中呈现-它将被更新。
这里是从控制台剪下的:
Hibernate:
insert
into
iot_entity
(controller_ref, description, device_id, device_ref, entity_type_ref, hw_address, hw_serial, image_ref, inventory_nr, ip6address1, ip6address2, ip_address1, ip_address2, latlng, location, mac_address, name, params, status, tenant, type, id)
values
(?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
...
2020-12-05 23:18:28.269 ERROR 15752 --- [ restartedMain] o.h.e.jdbc.batch.internal.BatchingBatch : HHH000315: Exception executing batch [java.sql.BatchUpdateException: Duplicate entry '1' for key 'iot_entity.PRIMARY'], SQL: insert into iot_entity (controller_ref, description, device_id, device_ref, entity_type_ref, hw_address, hw_serial, image_ref, inventory_nr, ip6address1, ip6address2, ip_address1, ip_address2, latlng, location, mac_address, name, params, status, tenant, type, id) values (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
2020-12-05 23:18:28.269 WARN 15752 --- [ restartedMain] o.h.engine.jdbc.spi.SqlExceptionHelper : SQL Error: 1062, SQLState: 23000
2020-12-05 23:18:28.269 ERROR 15752 --- [ restartedMain] o.h.engine.jdbc.spi.SqlExceptionHelper : Duplicate entry '1' for key 'iot_entity.PRIMARY'
2020-12-05 23:18:28.269 DEBUG 15752 --- [ restartedMain] o.s.orm.jpa.JpaTransactionManager : Initiating transaction rollback after commit exception
org.springframework.dao.DataIntegrityViolationException: could not execute batch; SQL [insert into iot_entity (controller_ref, description, device_id, device_ref, entity_type_ref, hw_address, hw_serial, image_ref, inventory_nr, ip6address1, ip6address2, ip_address1, ip_address2, latlng, location, mac_address, name, params, status, tenant, type, id) values (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)]; constraint [iot_entity.PRIMARY]; nested exception is org.hibernate.exception.ConstraintViolationException: could not execute batch
下面是获取和保存的方法,如下所示:
@Override
@SneakyThrows
@Scheduled(fixedDelay = 15_000)
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void fetchAndStoreData() {
IotEntity[] entities = restTemplate.getForObject(properties.getIotEntitiesUrl(), IotEntity[].class);
log.debug("ENTITIES:\n{}", mapper.writerWithDefaultPrettyPrinter().writeValueAsString(entities));
if (entities != null && entities.length > 0) {
entityRepository.saveAll(List.of(entities));
} else {
log.warn("NO entities data FETCHED !!!");
}
}
此方法每15秒运行一次。
实体:
@Data
@Entity
@NoArgsConstructor
@EqualsAndHashCode(of = {"id"})
@ToString(of = {"id", "deviceId", "entityTypeRef", "ipAddress1"})
public class IotEntity implements Serializable {
private static final long serialVersionUID = 1L;
@Id
private Integer id;
// other fields
和存储库:
public interface EntityRepository extends JpaRepository<IotEntity, Integer> {
}
这是以JSON格式截取的iot实体:
2020-12-05 23:18:44.261 DEBUG 15752 --- [pool-3-thread-1] EntityService : ENTITIES:
[ {
"id" : 1,
"controllerRef" : null,
"name" : "Local Controller Unterföhring",
"description" : "",
"deviceId" : "",
...
所以ID是确定的。
此外,为项目启用了批处理。它不应该对保存有任何影响。
我不明白为什么它试图插入新实体而不是更新现有实体<为什么它不能区分新旧实体之间的区别?
更新:
实体实现的持久化:
@Data
@Entity
@NoArgsConstructor
@EqualsAndHashCode(of = {"id"})
@ToString(of = {"id", "deviceId", "entityTypeRef", "ipAddress1"})
public class IotEntity implements Serializable, Persistable<Integer> {
private static final long serialVersionUID = 1L;
@Id
private Integer id;
@Override
public boolean isNew() {
return false;
}
@Override
public Integer getId() {
return this.id;
}
但是,它失败了,有同样的例外-key'iot_entity的重复条目'1'。PRIMARY'
如果我将添加GeneratedValue,如下所示:
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
它不会失败。但是,它会自行更新ID值。
例如,它使用id=15获取:
[ {
"id" : 15,
"carParkRef" : 15,
"name" : "UF Haus 1/2",
并且应该像下面这样保存:
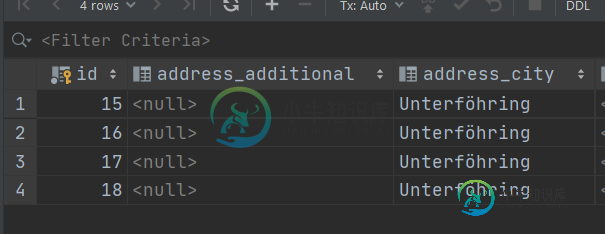
实际上,它的id为2:
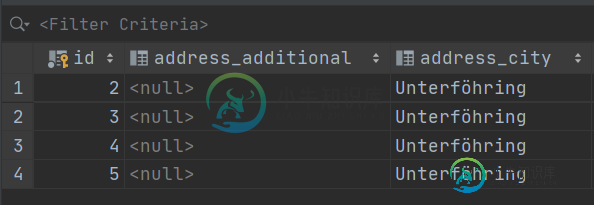
这是不正确的。
试图添加到存储服务:
private final EntityManager entityManager;
...
List.of(carParks).forEach(entityManager::merge);
失败并出现相同的异常(无论是否实现Persistable)。它尝试将值插入到。。。键“”的重复条目“15”。主要'
来自application.yml的片段:
spring:
# ===============================
# = DATA SOURCE
# ===============================
datasource:
url: jdbc:mysql://localhost:3306/demo_db
username: root
password: root
initialization-mode: always
# ===============================
# = JPA / HIBERNATE
# ===============================
jpa:
show-sql: true
generate-ddl: true
hibernate:
ddl-auto: update
properties:
hibernate:
format_sql: true
generate_statistics: true
在这里您可以看到pom文件内容。
如何解决此问题?
共有3个答案

Spring数据JPA使用@version@Id字段的组合来决定是合并还是插入。
- 空@id和空@版本意味着新记录,因此插入
因为你有@id和@version丢失,它试图插入,因为underlysing系统决定这是新的记录,当运行sql u得到错误。

看来我找到了这种行为的根源。
主应用程序启动器如下所示:
@AllArgsConstructor
@SpringBootApplication
public class Application implements CommandLineRunner {
private final DataService dataService;
private final QrReaderServer qrReaderServer;
private final MonitoringService monitoringService;
@Override
public void run(String... args) {
dataService.fetchAndStoreData();
monitoringService.launchMonitoring();
qrReaderServer.launchServer();
}
所有3个步骤都有严格的执行顺序。如果需要,必须重复第一个步骤以在本地更新数据。另外两个仅用于存储数据的服务器。
其中第一种方法如下所示:
@Scheduled(fixedDelay = 15_000)
public void fetchAndStoreData() {
log.debug("START_DATA_FETCH");
carParkService.fetchAndStoreData();
entityService.fetchAndStoreData();
assignmentService.fetchAndStoreData();
permissionService.fetchAndStoreData();
capacityService.fetchAndStoreData();
log.debug("END_DATA_FETCH");
}
此外,还计划了此执行。
当应用程序启动时,它尝试执行此提取两次:
2020-12-14 14:00:46.208 DEBUG 16656 --- [pool-3-thread-1] c.s.s.s.data.impl.DataServiceImpl : START_DATA_FETCH
2020-12-14 14:00:46.208 DEBUG 16656 --- [ restartedMain] c.s.s.s.data.impl.DataServiceImpl : START_DATA_FETCH
两个线程以相同的捕获和存储并行运行-尝试插入数据。(每次启动时都会重新创建表)。
所有后续的回迁都很好,它们只由指定的线程执行。
如果注释已被调度,它将正常工作,没有任何异常。
解决方案:
向服务类添加了其他布尔属性:
@Getter
private static final AtomicBoolean ifDataNotFetched = new AtomicBoolean(true);
@Override
@Scheduled(fixedDelay = 15_000)
@Order(value = Ordered.HIGHEST_PRECEDENCE)
public void fetchAndStoreData() {
ifDataNotFetched.set(true);
log.debug("START_DATA_FETCH");
// fetch and store data with `saveAll()`
log.debug("END_DATA_FETCH");
ifDataNotFetched.set(false);
}
并在应用程序启动后控制值:
@Value("${sharepark.remote-data-fetch-timeout}")
private int dataFetchTimeout;
private static int fetchCounter;
@Override
public void run(String... args) {
waitRemoteDataStoring();
monitoringService.launchMonitoring();
qrReaderServer.launchServer();
}
private void waitRemoteDataStoring() {
do {
try {
if (fetchCounter == dataFetchTimeout) {
log.warn("Data fetch timeout reached: {}", dataFetchTimeout);
}
Thread.sleep(1_000);
++fetchCounter;
log.debug("{} Wait for data fetch one more second...", fetchCounter);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
} while (DataServiceImpl.getIfDataNotFetched().get() && fetchCounter <= dataFetchTimeout);
}

问题很可能是,由于Id没有标记为GeneratedValue,Spring数据假定传递给save()/saveAll()的所有分离(瞬态)实体都应该具有EntityManager。对其调用persist()。
尝试使IotEntity实现持久并从isNew()返回false。这将告诉Spring Data始终使用EntityManager.merge(),这应该具有预期的效果(即插入不存在的实体并更新现有实体)。
-
嗨,我是Spring Data JPA的新手,我想知道即使我将Id传递给实体,Spring data jpa也是插入而不是合并的。我想当我实现持久接口并实现这两个方法时: 它将自动合并而不是持久化。 我有一个名为User like的实体类: 再上一节课 我有一个名为UserRepostory的自定义存储库,它扩展了JpaReopistory。当我看到实现演示SpringDataJpa使用以上两种方
-
我的讲师在课堂上问过我这个问题,我想知道为什么是宏而不是函数?
-
根据Stevens(图示为TCP/IP),traceroute程序用增量TTL(1、2、3等)向目的主机发送UDP数据包,以从ICMP TTL过期消息中获取中间跳信息。 “到达目的地”条件是ICMP端口无法到达的消息,因为traceroute寻址的随机端口数量很高(也就是说,不太可能有人在那里监听) 所以我的问题是:是否有技术原因(缺点、RFCs等)使用UDP数据包而不使用例如ICMP回送请求消息
-
所以,这可能是一个愚蠢的问题,但据我所知,如果我通过TCP或UDP发送数据,如果组成该TCP/UDP数据包的任何一个IP数据包被丢弃,整个TCP/UDP数据包将被重传,但我的问题是为什么我们不能只发送丢失的部分数据吗?目前,我对此的唯一推理是,如果我们要为收到的每个IP数据包发送确认字符,这将增加网络拥塞。这是正确的,还是有其他原因,当只有一个或几个IP数据包被丢弃时,我们必须重新发送TCP/UD
-
问题内容: 我正在阅读Java JDBC规范(版本4),并且遇到了以下语句: DataSource-此接口在JDBC 2.0可选软件包API中引入。它优于DriverManager,因为它允许有关基础数据源的详细信息对应用程序透明 我想了解的是a 和a 之间的区别以及它为什么存在。我的意思是,上面的代码块说关于数据源的详细信息对于应用程序是透明的,但是是否不会在属性文件中外部化数据库属性(例如用户
-
我试图理解的是和之间的区别,以及它存在的原因。我的意思是,上面的块表明关于数据源的细节对应用程序是透明的,但是在属性文件中外部化数据库属性如用户名、密码、url等,然后使用DriverManager是否会以同样的方式工作? 创建接口是否只是为了有一种返回可以池化的连接的通用方式?在Java EE中,应用程序服务器是否实现了这个接口,并且部署的应用程序是否具有对数据源的引用而不是连接?