
获取数据时修复性能缓慢的问题

与1/10比例的实时数据库相比,我在检索存储在文档中的基本数据时,Firestore的性能问题很慢。
使用FiRecovery,第一次通话平均需要3000毫秒
this.db.collection(‘testCol’)
.doc(‘testDoc’)
.valueChanges().forEach((data) => {
console.log(data);//3000 ms later
});
使用实时数据库,第一次通话平均需要300毫秒
this.db.database.ref(‘/test’).once(‘value’).then(data => {
console.log(data); //300ms later
});
这是网络控制台的屏幕截图:
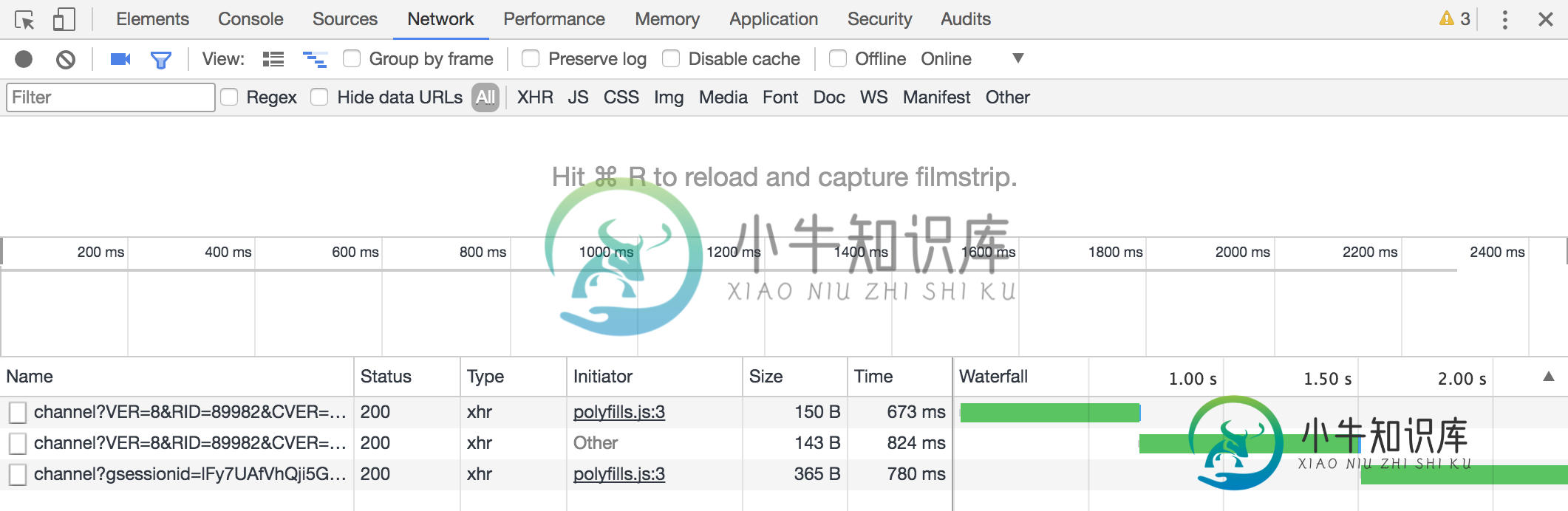
我正在使用AngularFire2 v5.0 rc运行Javascript SDK v4.50。2.
有没有人遇到过这个问题?
共有3个答案

将近3年后,fiRecovery已经脱离了测试版,我可以确认这个可怕的问题仍然存在;-(
在我们的移动应用程序中,我们使用javascript/节点。js firebase客户端。在进行了大量测试以找出为什么我们的应用程序的启动时间约为10秒之后,我们确定了70%的启动时间应该归因于什么。。。对于firebase和firestore的性能和冷启动问题:
- firebase。auth()。onAuthStateChanged()大约在1.5-2秒后激发,已经很糟糕了
- 如果它返回一个用户,我们将使用其ID从firestore获取用户文档。这是对firestore的第一次调用,相应的get()需要4-5秒。相同或其他文档的后续get()大约需要500毫秒
因此,用户初始化总共需要6-7秒,这是完全不可接受的。我们对此无能为力。我们无法测试禁用持久性,因为在javascript客户端中没有这样的选项,持久性在默认情况下总是启用的,所以不调用enablePersistence()不会改变任何事情。

更新日期2018年3月2日
看起来这是一个已知的问题,Firestore的工程师正在进行修复。在与Firestore工程师就这个问题进行了几次电子邮件交流和代码共享之后,这是他今天的回应。
“你实际上是正确的。经过进一步检查,getDocuments()API上的这种缓慢是Cloud Firestbeta中的一种已知行为。我们的工程师已经意识到这个被标记为“冷启动”的性能问题,但不要担心,因为我们正在尽最大努力提高FiRecovery查询性能。
我们已经在进行长期修复,但目前我无法分享任何时间表或细节。虽然Firestore仍在测试阶段,但预计还会有更多的改进。"
所以希望这会很快被淘汰。
使用Swift/iOS
在处理了大约3天后,问题似乎肯定是get()即. getDocuments和. getDocument。我认为导致极端但间歇性延迟的事情,但似乎并非如此:
我能够排除所有这些问题,因为我注意到这个问题并不是每次调用Firestore数据库都会发生。仅使用get()进行检索。我换了脚踢。使用获取文档。添加SnapshotListener来检索我的数据,瞧。包括第一次呼叫在内的每次即时检索。无冷启动。到目前为止,没有问题。addSnapshotListener,仅getDocument。
现在,我只是放弃了。getDocument(),其中时间至关重要,并将其替换为。添加SnapshotListener,然后使用
for document in querySnapshot!.documents{
// do some magical unicorn stuff here with my document.data()
}
... 为了继续前进,直到Firestore解决这个问题。

更新:2018年2月12日-iOS Firestore SDK v0.10.0
与其他一些评论者类似,我还注意到第一个get请求的响应速度较慢(后续请求大约需要100毫秒)。对我来说,它没有30秒那么糟糕,但当我有良好的连接时,可能会在2-3秒左右,这足以在我的应用程序启动时提供糟糕的用户体验。
Firebase表示,他们已经意识到这个“冷启动”问题,并且正在为其制定长期解决方案——不幸的是,没有预计到达时间。我认为这是一个单独的问题,当我连接不良时,可能需要很长时间(超过30年)才能让请求决定从缓存中读取。
虽然Firebase解决了所有这些问题,但我已经开始使用新的disableNetwork()和enableNetwork()方法(在FiRecovery v0.10.0中可用)来手动控制Firebase的在线/离线状态。尽管我必须非常小心在代码中使用它的地方,因为在某些情况下有一个FiRecovery错误可能会导致崩溃。
更新:2017年11月15日-iOS Firestore SDK v0.9.2
现在似乎已经解决了性能缓慢的问题。我重新运行了下面描述的测试,Firestore返回100个文档所需的时间现在似乎一直在100ms左右。
不确定这是最新SDK v0.9.2中的修复还是后端修复(或两者兼有),但我建议每个人都更新他们的Firebase播客。我的应用程序响应速度明显更快,与实时数据库上的方式类似。
我还发现FiRecovery比Realtime DB慢得多,尤其是在阅读大量文档时。
更新的测试(最新的iOSFiRecoverySDKv0.9.0):
我在iOS Swift中使用RTDB和Firestore建立了一个测试项目,并对每个项目运行了100个连续读取操作。对于RTDB,我在100个顶级节点中的每个节点上测试了observeSingleEvent和observe方法。对于Firestore,我在TestCol集合中的100个文档中的每个文档上都使用了getDocument和addSnapshotListener方法。我在打开和关闭磁盘持久性的情况下运行了测试。请参阅附图,其中显示了每个数据库的数据结构。
我在同一台设备和稳定的wifi网络上对每个数据库进行了10次测试。在每次新运行之前,现有的观察器和侦听器都会被销毁。
实时DB观察SingleEvent方法:
func rtdbObserveSingle() {
let start = UInt64(floor(Date().timeIntervalSince1970 * 1000))
print("Started reading from RTDB at: \(start)")
for i in 1...100 {
Database.database().reference().child(String(i)).observeSingleEvent(of: .value) { snapshot in
let time = UInt64(floor(Date().timeIntervalSince1970 * 1000))
let data = snapshot.value as? [String: String] ?? [:]
print("Data: \(data). Returned at: \(time)")
}
}
}
实时DB观察方法:
func rtdbObserve() {
let start = UInt64(floor(Date().timeIntervalSince1970 * 1000))
print("Started reading from RTDB at: \(start)")
for i in 1...100 {
Database.database().reference().child(String(i)).observe(.value) { snapshot in
let time = UInt64(floor(Date().timeIntervalSince1970 * 1000))
let data = snapshot.value as? [String: String] ?? [:]
print("Data: \(data). Returned at: \(time)")
}
}
}
Firestore getDocument方法:
func fsGetDocument() {
let start = UInt64(floor(Date().timeIntervalSince1970 * 1000))
print("Started reading from FS at: \(start)")
for i in 1...100 {
Firestore.firestore().collection("TestCol").document(String(i)).getDocument() { document, error in
let time = UInt64(floor(Date().timeIntervalSince1970 * 1000))
guard let document = document, document.exists && error == nil else {
print("Error: \(error?.localizedDescription ?? "nil"). Returned at: \(time)")
return
}
let data = document.data() as? [String: String] ?? [:]
print("Data: \(data). Returned at: \(time)")
}
}
}
Firestore addSnapshotListener方法:
func fsAddSnapshotListener() {
let start = UInt64(floor(Date().timeIntervalSince1970 * 1000))
print("Started reading from FS at: \(start)")
for i in 1...100 {
Firestore.firestore().collection("TestCol").document(String(i)).addSnapshotListener() { document, error in
let time = UInt64(floor(Date().timeIntervalSince1970 * 1000))
guard let document = document, document.exists && error == nil else {
print("Error: \(error?.localizedDescription ?? "nil"). Returned at: \(time)")
return
}
let data = document.data() as? [String: String] ?? [:]
print("Data: \(data). Returned at: \(time)")
}
}
}
每个方法本质上都是在方法开始执行时以毫秒为单位打印unix时间戳,然后在每次读取操作返回时打印另一个unix时间戳。我取初始时间戳和上次时间戳之间的差值返回。
结果-禁用磁盘持久性:
结果-已启用磁盘持久性:
数据结构:
当Firestore getDocument/addSnapshotListener方法被卡住时,它似乎会被卡住大约30秒的倍数。也许这可以帮助Firebase团队找出SDK中的哪些地方卡住了?
-
问题内容: 我正在尝试解决回文分割问题。您可以在https://leetcode.com/problems/palindrome- partitioning/中 找到问题。 我想出了解决方案: 但是性能很差。超过时间限制。 但是Python实现的相同想法可以通过: 这让我想知道如何改进swift的实现以及为什么swift的实现比python慢。 问题答案: Swift 是的集合,并且a 表示单
-
我们在服务器和客户机模式下使用Ignite 2.7.6:两个服务器和六个客户机。 正如我们所看到的,现在所有服务器节点的CPU负载都很高,约为250%(更新前为20%),而长G1 Young Gen的停顿时间高达5毫秒(更新前为300微秒)。 服务器配置为: 在Ignite服务器节点的内存转储中,我们看到大量,大小为21MB
-
问题内容: 这是两个非常相似的地方。 实施:https : //gist.github.com/bgreenlee/52d93a1d8fa1b8c1f38b 和实现:https : //gist.github.com/boratlibre/1593632 在一个是慢得多然后实现我送给几个小时,使其速度更快,但......好像阵列和操作是不一样快。 在2000年的计算中,执行速度比慢约100(!!!
-
问题内容: 我是ORMLite的主要作者,它使用类上的Java注释来构建数据库模式。我们的程序包最大的启动性能问题是在Android 1.6下调用注释方法。直到3.0我都看到了相同的行为。 我们看到以下简单的注释代码 难以置信地 占用大量GC,这是一个实际的性能问题。在快速的Android设备上,对注释方法的1000次调用几乎耗时一秒。Macbook Pro上运行的相同代码可以同时进行2800万次
-
我正在使用reactjs构建一个前端唯一的基本天气应用程序。对于API请求,我使用Fetch API。在我的应用程序中,我从一个简单的API获取当前位置,它以JSON对象的形式给出了位置。但是当我通过获取API请求它时,我得到了这个错误。 所以我搜索并找到了多种解决方案来解决这个问题。 在Chrome启用CORS解决了这个错误,但是当我在heroku上部署应用程序时,我如何通过移动设备访问它,而不
-
问题内容: 我对Redis有点陌生,所以如果这是一个愚蠢的问题,我深表歉意。 我正在将Django与Redis用作缓存。 我正在腌制约200个对象的集合并将其存储在Redis中。 当我从Redis请求收集时,Django Debug Toolbar通知我对Redis的请求大约需要3 秒钟 。我一定在做些可怕的错误。 该服务器具有3.5GB的ram,看起来Redis当前仅使用约50mb,因此我敢肯定